数据结构与算法-3
八、堆(Heap)
8.1 堆
堆(heap)是一种满足特定条件的完全二叉树,主要可分为两种类型,如图所示。
- 小顶堆(min heap):任意节点的值 ≤ 其子节点的值。
- 大顶堆(max heap):任意节点的值 ≥ 其子节点的值。
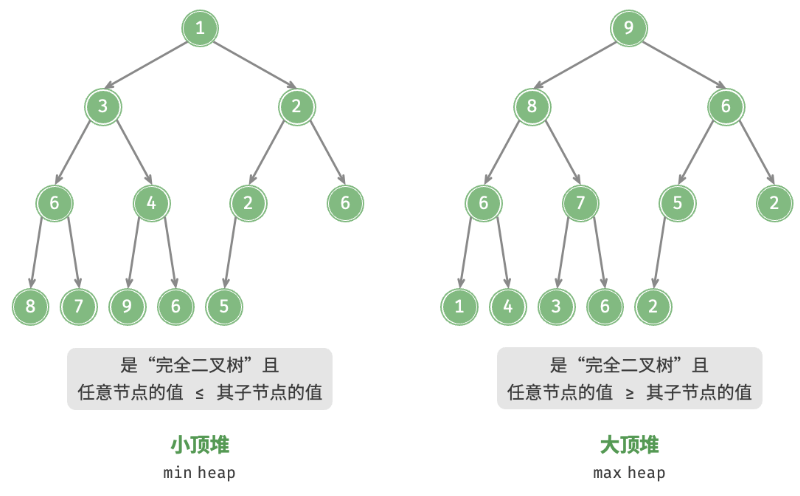
堆作为完全二叉树的一个特例,具有以下特性。
- 最底层节点靠左填充,其他层的节点都被填满。
- 我们将二叉树的根节点称为“堆顶”,将底层最靠右的节点称为“堆底”。
- 对于大顶堆(小顶堆),堆顶元素(根节点)的值是最大(最小)的。
8.1.1 堆的常用操作
优先队列(priority queue),这是一种抽象的数据结构,定义为具有优先级排序的队列。
堆通常用于实现优先队列,大顶堆相当于元素按从大到小的顺序出队的优先队列。从使用角度来看,我们将“优先队列”和“堆”看作等价的数据结构。本书对两者不做特别区分,统一称作“堆”。

1 | |
8.1.2 堆的实现
下文实现的是大顶堆。若要将其转换为小顶堆,只需将所有大小逻辑判断进行逆转(例如,将 ≥ 替换为 ≤ )。
1. 堆的存储与表示
“二叉树”章节讲过,完全二叉树非常适合用数组表示。由于堆正是一种完全二叉树,因此我们将采用数组来存储堆。
当使用数组表示二叉树,元素代表节点值,索引代表节点在二叉树中的位置。节点指针通过索引映射公式来实现。
如图所示,给定索引 $i$ ,其左子节点的索引为 $2i+1$ ,右子节点的索引为 $2i+2$ ,父节点的索引为 $(i−1)/2$(向下整除)。当索引越界时,表示空节点或节点不存在。
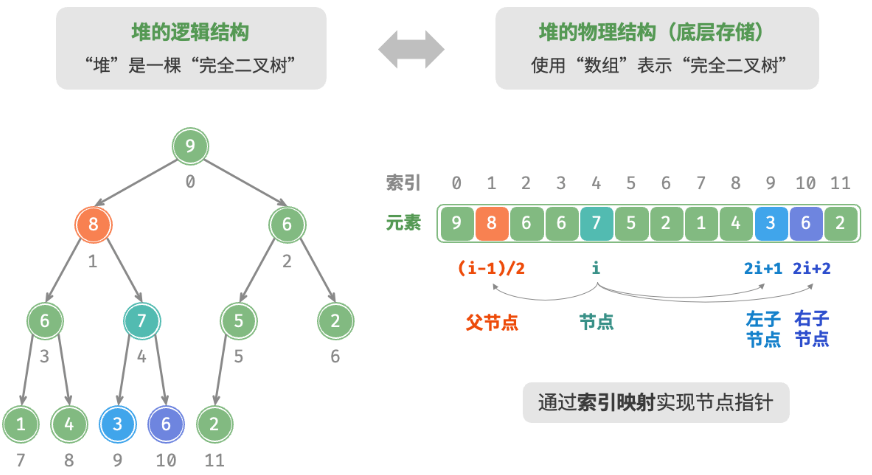
我们可以将索引映射公式封装成函数,方便后续使用:
1 | |
2. 访问堆顶元素
堆顶元素即为二叉树的根节点,也就是列表的首个元素:
1 | |
3. 元素入堆(Sift UP)
给定元素
val,我们首先将其添加到堆底。添加之后,由于val可能大于堆中其他元素,堆的成立条件可能已被破坏,因此需要修复从插入节点到根节点的路径上的各个节点,这个操作被称为堆化(heapify)。考虑从入堆节点开始,从底至顶执行堆化。如图所示,我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。
也称上滤。
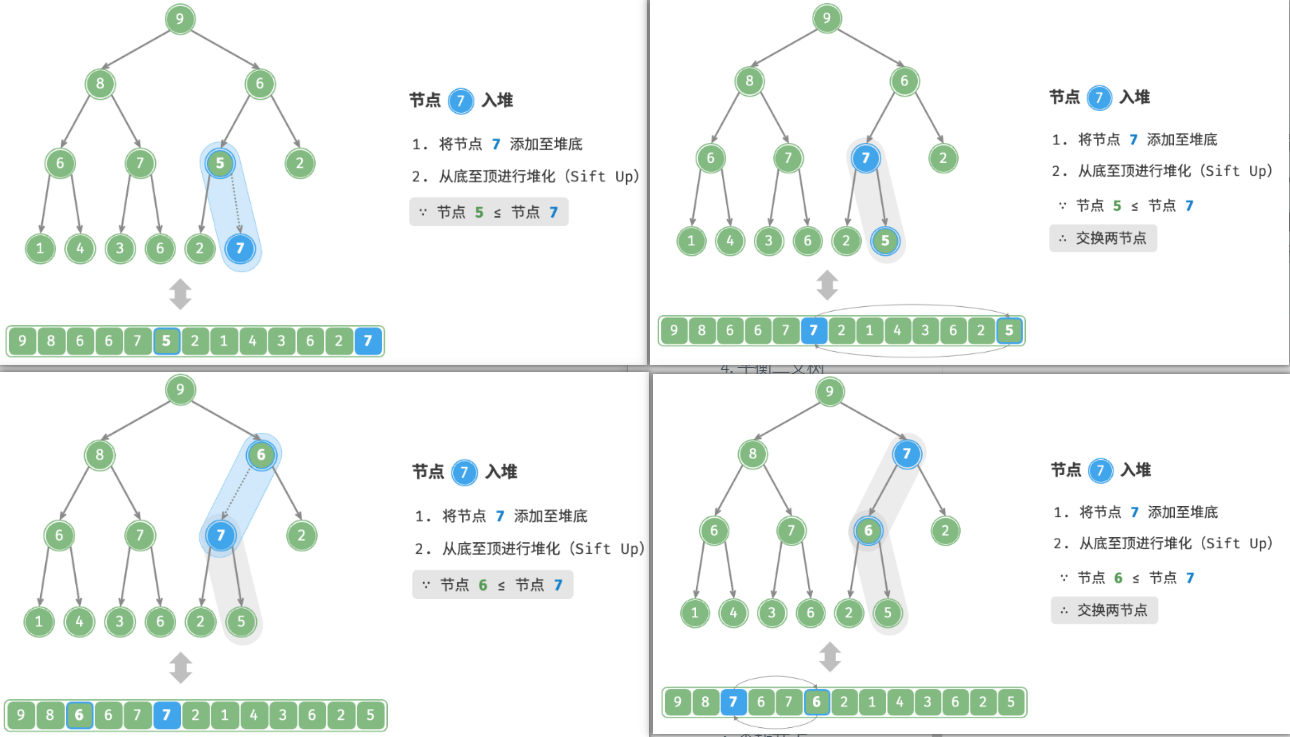
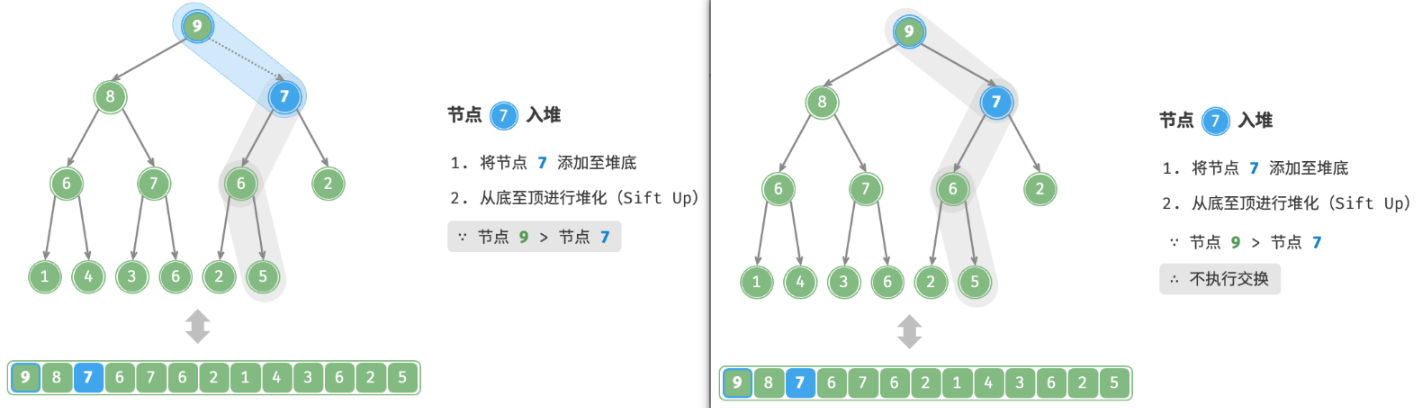
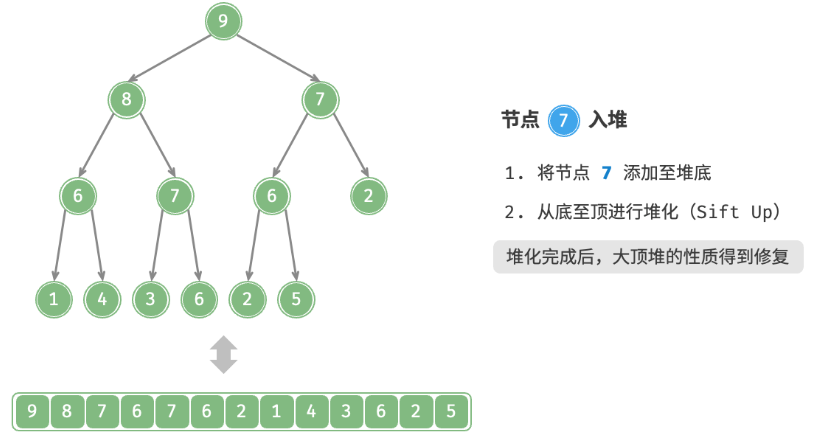
设节点总数为 n ,则树的高度为 O(logn) 。由此可知,堆化操作的循环轮数最多为 O(logn) ,元素入堆操作的时间复杂度为 O(logn) 。代码如下所示:
1 | |
4. 堆顶元素出堆(Sift Down)
堆顶元素是二叉树的根节点,即列表首元素。如果我们直接从列表中删除首元素,那么二叉树中所有节点的索引都会发生变化,这将使得后续使用堆化进行修复变得困难。为了尽量减少元素索引的变动,我们采用以下操作步骤。
- 交换堆顶元素与堆底元素(交换根节点与最右叶节点)。
- 交换完成后,将堆底从列表中删除(注意,由于已经交换,因此实际上删除的是原来的堆顶元素)。
- 从根节点开始,从顶至底执行堆化。
如图,“从顶至底堆化”的操作方向与“从底至顶堆化”相反,我们将根节点的值与其两个子节点的值进行比较,将最大的子节点与根节点交换。然后循环执行此操作,直到越过叶节点或遇到无须交换的节点时结束。
也称下滤。
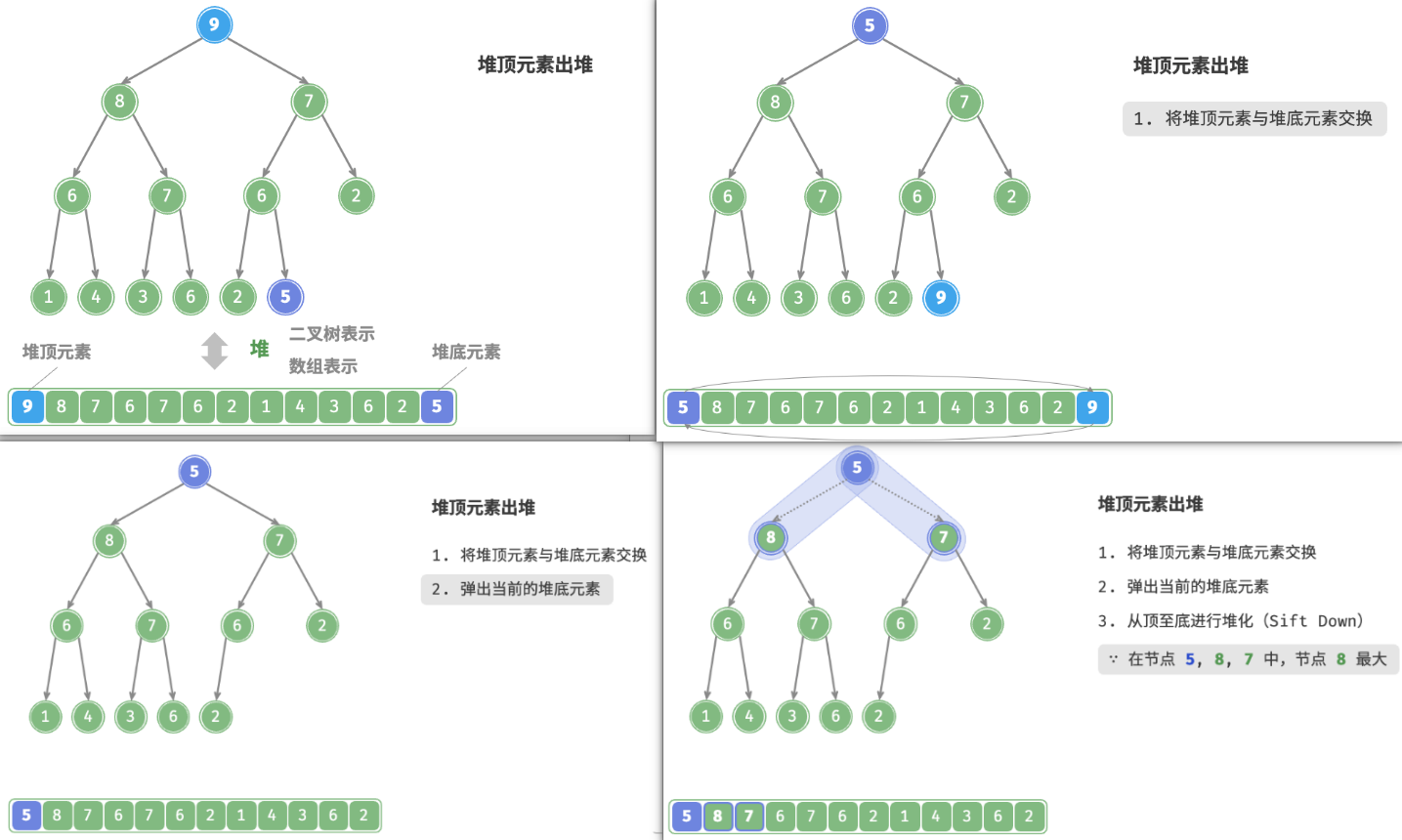
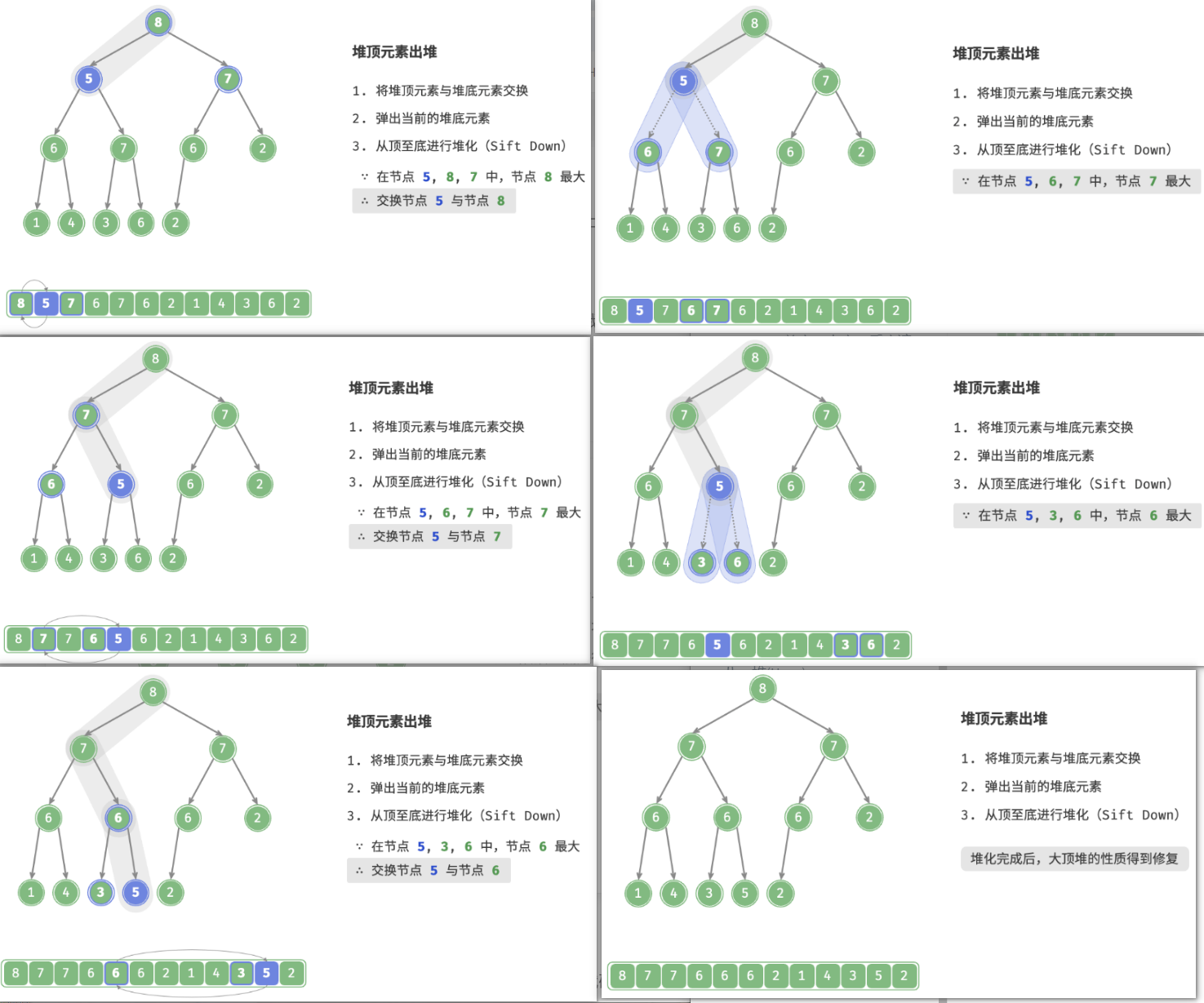
与元素入堆操作相似,堆顶元素出堆操作的时间复杂度也为 O(logn) 。代码如下所示:
1 | |
8.1.3 堆的常见应用
- 优先队列:堆通常作为实现优先队列的首选数据结构,其入队和出队操作的时间复杂度均为 O(logn) ,而建堆操作为 O(n) ,这些操作都非常高效。
- 堆排序:给定一组数据,我们可以用它们建立一个堆,然后不断地执行元素出堆操作,从而得到有序数据。然而,我们通常会使用一种更优雅的方式实现堆排序,详见“堆排序”章节。
- 获取最大的 k 个元素:这是一个经典的算法问题,同时也是一种典型应用,例如选择热度前 10 的新闻作为微博热搜,选取销量前 10 的商品等。
8.2 建堆操作(Heapify)
堆是一种特殊的数据结构,通常用完全二叉树来实现,建堆操作就是用一堆数据来构建这样一个堆。下面是两种建堆方法:
8.2.1 借助入堆操作实现
逐个插入元素并进行堆化:逐步插入每个元素,在每次插入后调整堆的结构,确保满足堆的性质
首先创建一个空堆,然后遍历列表,依次对每个元素执行“入堆操作”,即先将元素添加至堆的尾部,再对该元素执行“从底至顶”堆化。
每当一个元素入堆,堆的长度就加一。由于节点是从顶到底依次被添加进二叉树的,因此堆是“自上而下”构建的。(这里的“从顶到底”指的是元素按照完全二叉树的层序(即从上到下、从左到右)依次添加到堆的尾部。例如,插入第一个元素作为根节点,第二个作为左子节点,第三个作为右子节点,依此类推。每次插入后,通过从底至顶的堆化(即比较当前节点与父节点,必要时交换)来维护堆的性质。)
设元素数量为 $n$ ,每个元素的入堆操作使用 $O(logn)$ 时间,因此该建堆方法的时间复杂度为 $O(nlogn)$ 。
8.2.2 通过遍历堆化实现
一次性添加所有元素后,进行倒序遍历的堆化
另一种更为高效的建堆方法,共分为两步:
- 将列表所有元素原封不动地添加到堆中,此时堆的性质尚未得到满足。
- 倒序遍历堆(层序遍历的倒序),依次对每个非叶节点执行“从顶至底堆化”。
每当堆化一个节点后,以该节点为根节点的子树就形成一个合法的子堆。而由于是倒序遍历,因此堆是“自下而上”构建的。
之所以选择倒序遍历,是因为这样能够保证当前节点之下的子树已经是合法的子堆,这样堆化当前节点才是有效的。
这种方法的时间复杂度是 $O(n)$。
值得说明的是,由于叶节点没有子节点,因此它们天然就是合法的子堆,无须堆化。如以下代码所示,最后一个非叶节点是最后一个节点的父节点,我们从它开始倒序遍历并执行堆化:
1 | |
8.3 Top-k 问题
给定一个长度为 n 的无序数组
nums,请返回数组中最大的 $k$ 个元素。
对于该问题,我们先介绍两种思路比较直接的解法,再介绍效率更高的堆解法。
8.3.1 方法一:遍历选择
我们可以进行图所示的 $k$ 轮遍历,分别在每轮中提取第 $1、2、…、k$ 大的元素,时间复杂度为 $O(nk)$ 。
此方法只适用于 $k≪n$ 的情况,因为当 $k$ 与 $n$ 比较接近时,其时间复杂度趋向于 $O(n^2)$ ,非常耗时。
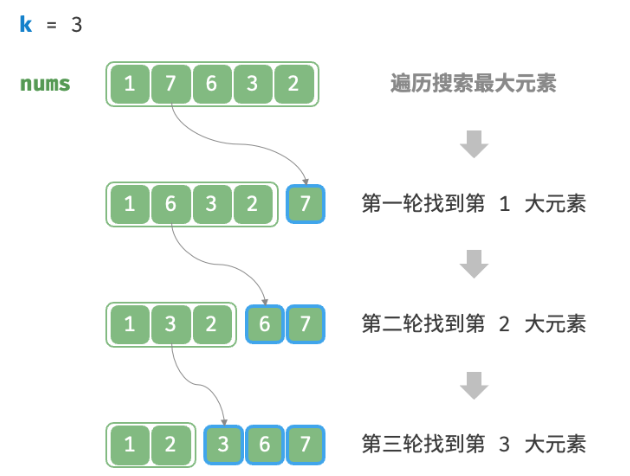
当 $k=n$ 时,我们可以得到完整的有序序列,此时等价于“选择排序”算法。
8.3.2 方法二:排序
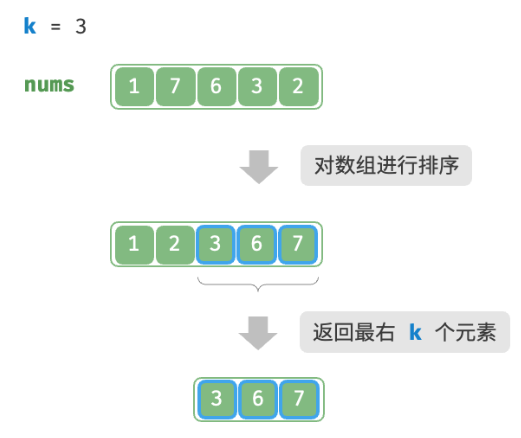
如图所示,我们可以先对数组
nums进行排序,再返回最右边的 k 个元素,时间复杂度为 O(nlogn) 。显然,该方法“超额”完成任务了,因为我们只需找出最大的 k 个元素即可,而不需要排序其他元素。
8.3.3 方法三:堆
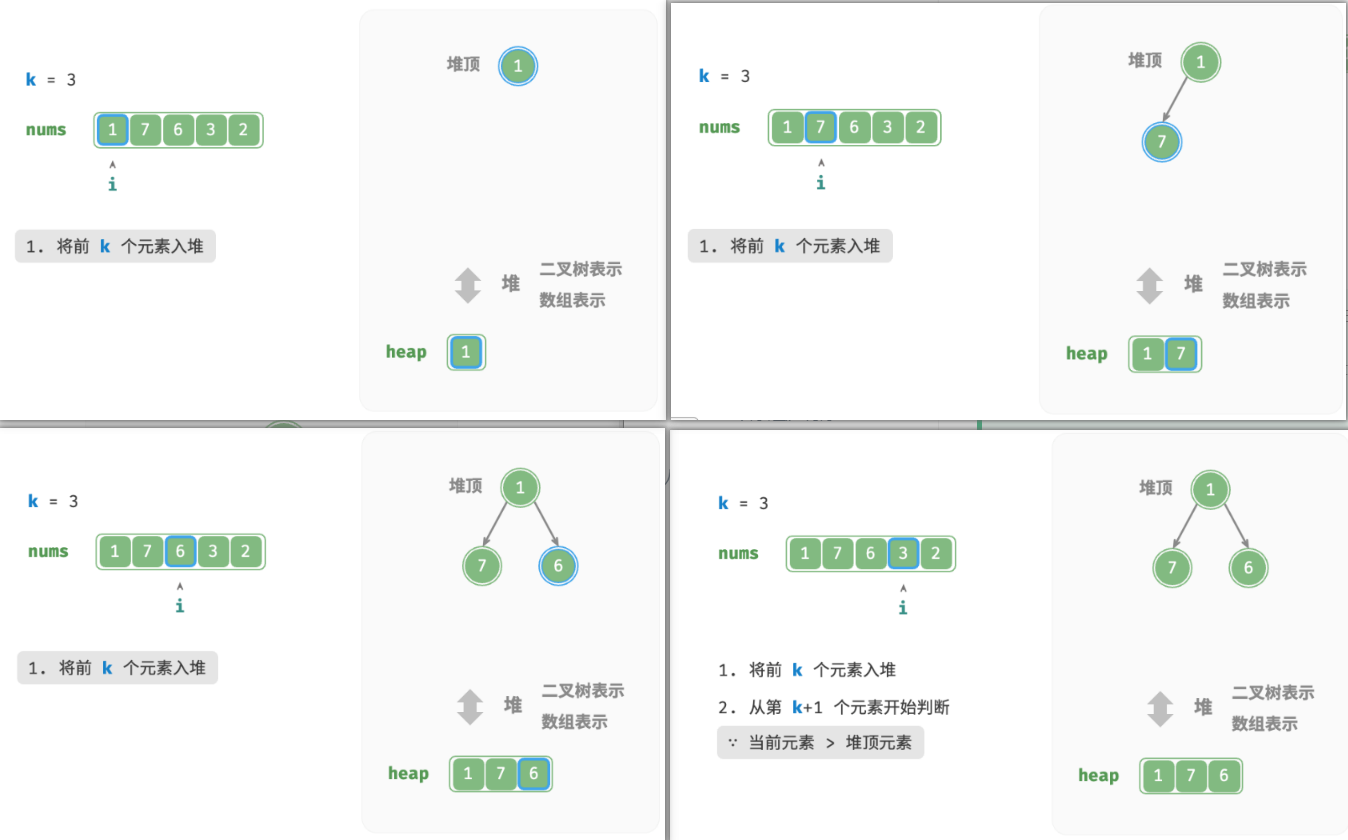
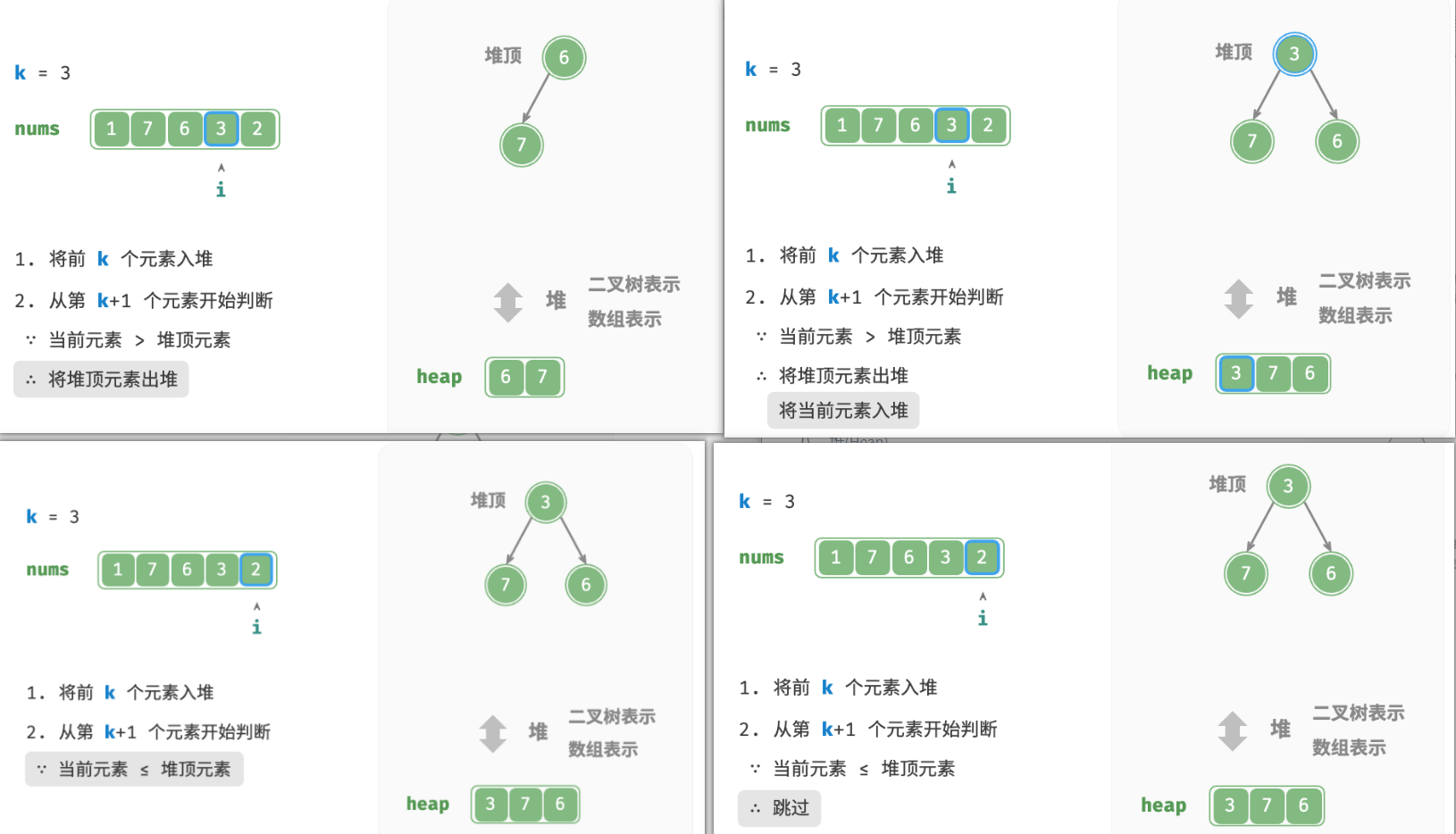
我们可以基于堆更加高效地解决 Top-k 问题,流程如图所示。
- 初始化一个小顶堆,其堆顶元素最小。
- 先将数组的前 k 个元素依次入堆。
- 从第 k+1 个元素开始,若当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆。
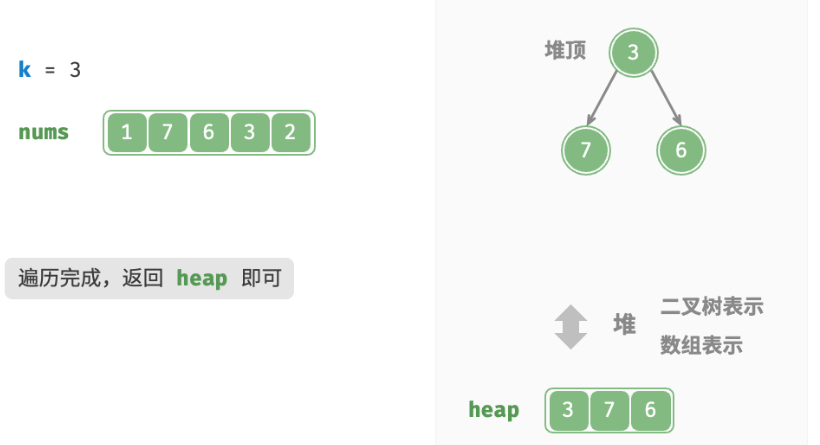
- 遍历完成后,堆中保存的就是最大的 k 个元素。
1 | |
总共执行了 $n$ 轮入堆和出堆,堆的最大长度为 k ,因此时间复杂度为 $O(nlogk)$ 。该方法的效率很高,当 $k$ 较小时,时间复杂度趋向 $O(n)$ ;当 $k$ 较大时,时间复杂度不会超过 $O(nlogn)$ 。
九、图(graph)
9.1 图
图是一种非线性数据结构,由顶点(vertex)和边(edge)组成。我们可以将图 G 抽象地表示为一组顶点 V 和一组边 E 的集合。
如果将顶点看作节点,将边看作连接各个节点的引用(指针),我们就可以将图看作一种从链表拓展而来的数据结构。
相较于线性关系(链表)和分治关系(树),网络关系(图)的自由度更高,因而更为复杂。
以下示例展示了一个包含 5 个顶点和 7 条边的图:
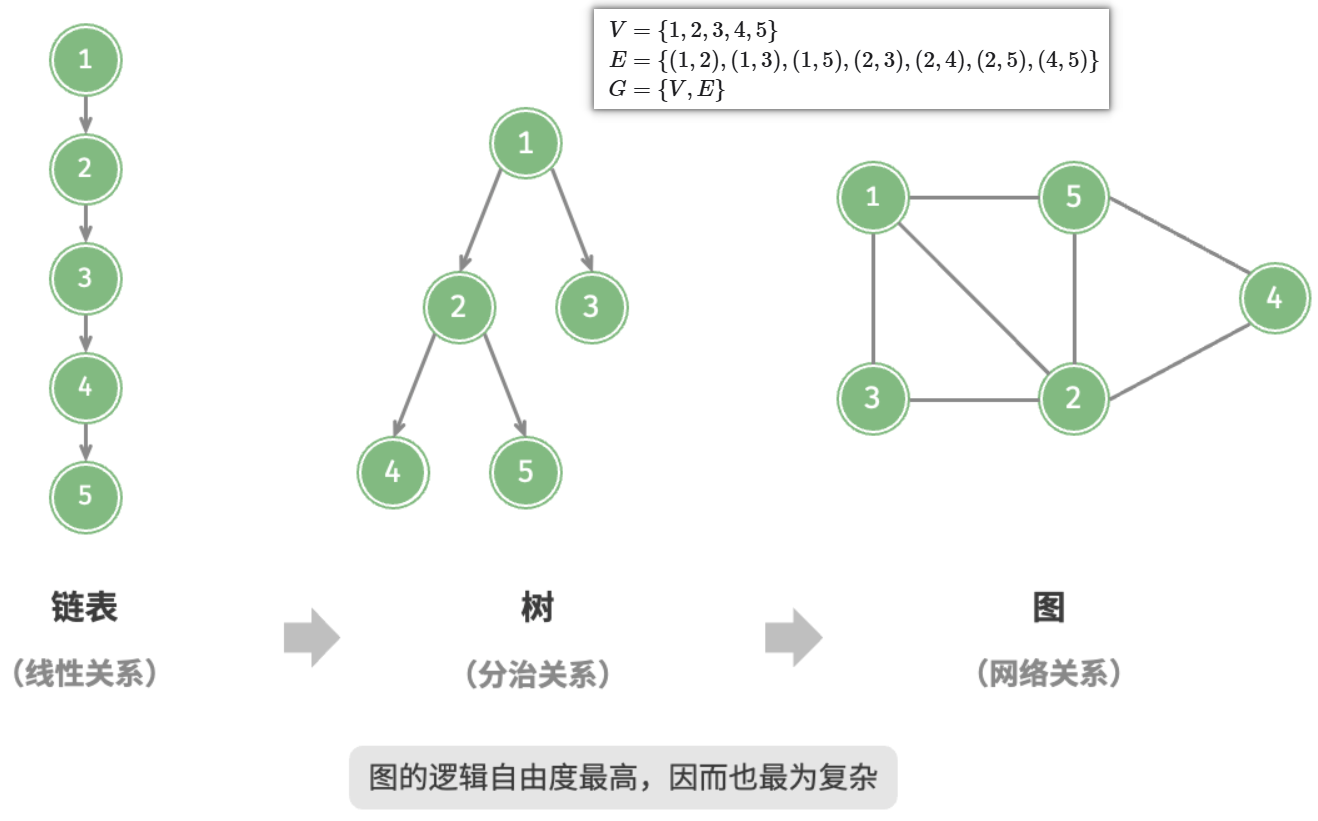
9.1.1 图的常见类型与术语
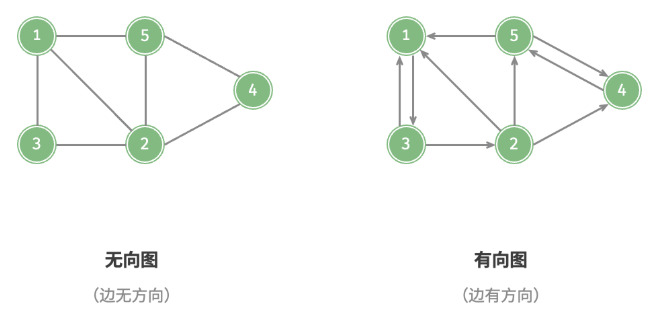
根据边是否具有方向,可分为无向图(undirected graph)和有向图(directed graph),如图所示。
- 在无向图中,边表示两顶点之间的“双向”连接关系,例如微信或 QQ 中的“好友关系”。
- 在有向图中,边具有方向性,即 A→B 和 A←B 两个方向的边是相互独立的,例如微博或抖音上的“关注”与“被关注”关系。
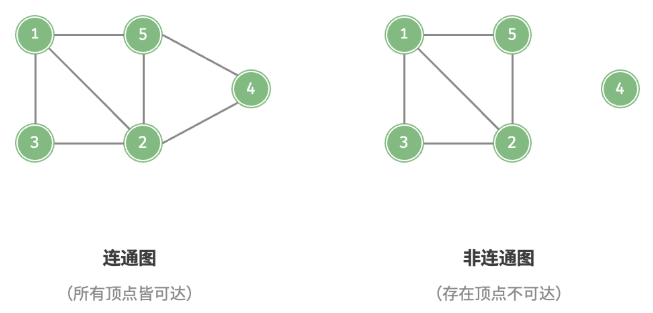
根据所有顶点是否连通,分为连通图(connected graph)和非连通图(disconnected graph),如图所示
- 对于连通图,从某个顶点出发,可以到达其余任意顶点。
- 对于非连通图,从某个顶点出发,至少有一个顶点无法到达。
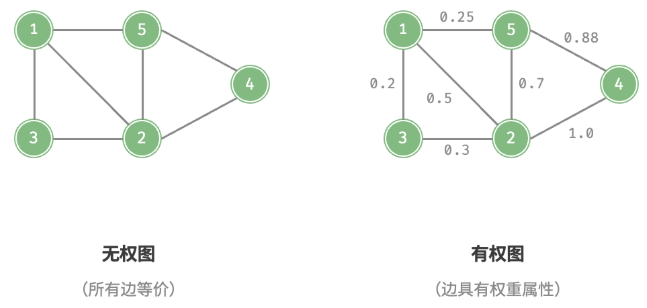
我们还可以为边添加“权重”变量,从而得到如图所示的有权图(weighted graph)。例如系统会根据共同游戏时间来计算玩家之间的“亲密度”,这种亲密度网络就可以用有权图来表示。
图数据结构包含以下常用术语。
- 邻接(adjacency):当两顶点之间存在边相连时,称这两顶点“邻接”。在上图中,顶点 1 的邻接顶点为顶点 2、3、5。
- 路径(path):从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”。在上图中,边序列 1-5-2-4 是顶点 1 到顶点 4 的一条路径。
- 度(degree):一个顶点拥有的边数。对于有向图,入度(in-degree)表示有多少条边指向该顶点,出度(out-degree)表示有多少条边从该顶点指出。
9.1.2 图的表示
图的常用表示方式包括“邻接矩阵”和“邻接表”。以下使用无向图进行举例。
1. 邻接矩阵
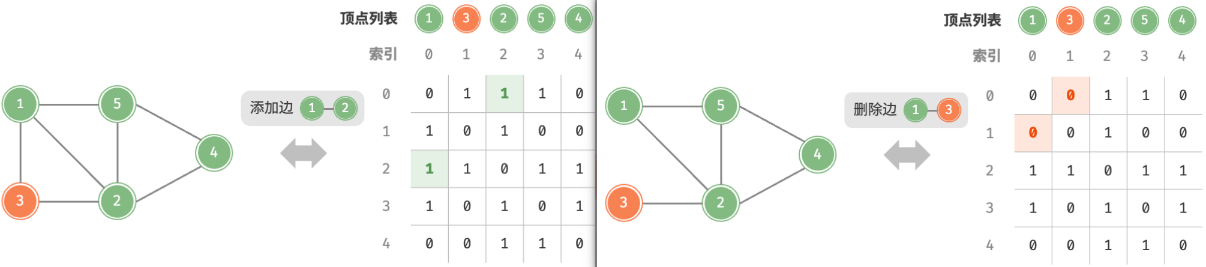
设图的顶点数量为 n ,邻接矩阵(adjacency matrix)使用一个 n×n 大小的矩阵来表示图,每一行(列)代表一个顶点,矩阵元素代表边,用 1 或 0 表示两个顶点之间是否存在边。
如图所示,设邻接矩阵为 M、顶点列表为 V ,那么矩阵元素 M[i,j]=1 表示顶点 V[i] 到顶点 V[j] 之间存在边,反之 M[i,j]=0 表示两顶点之间无边。
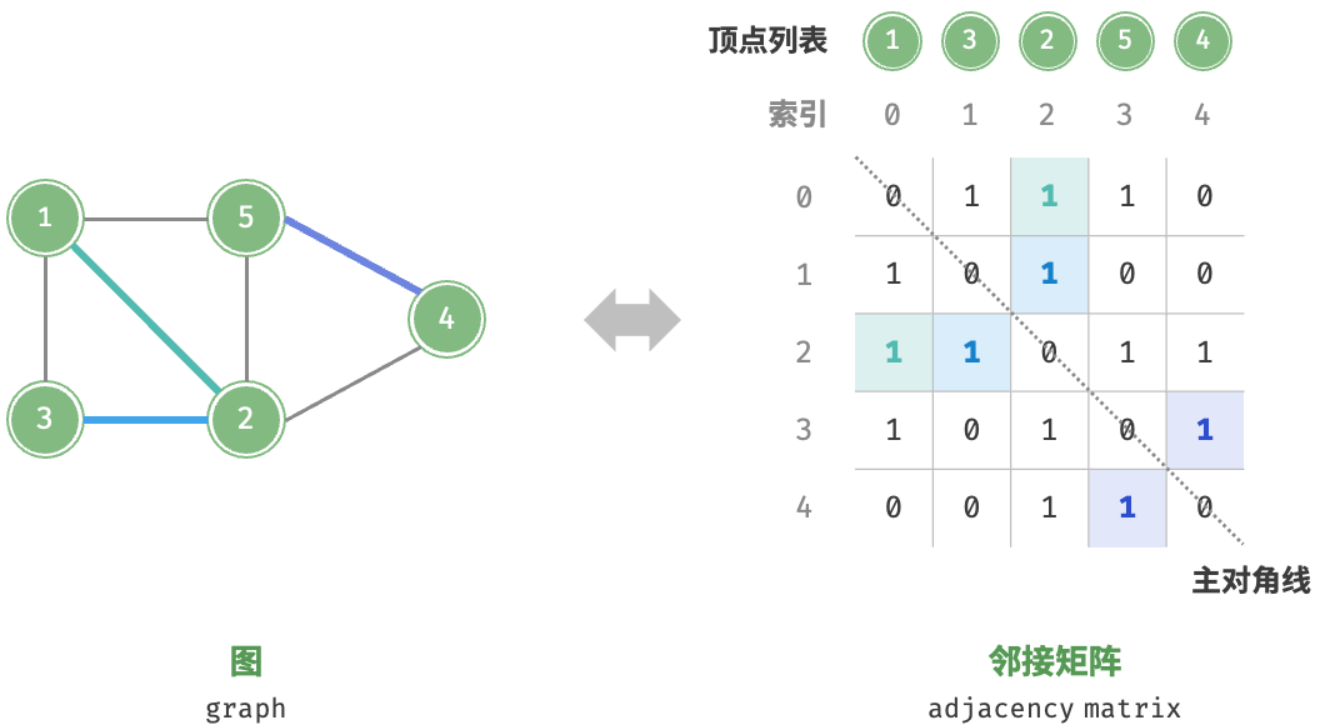
邻接矩阵具有以下特性。
- 在简单图中,顶点不能与自身相连,此时邻接矩阵主对角线元素没有意义。
- 对于无向图,两个方向的边等价,此时邻接矩阵关于主对角线对称。
- 将邻接矩阵的元素从 1 和 0 替换为权重,则可表示有权图。
使用邻接矩阵表示图时,我们可以直接访问矩阵元素以获取边,因此增删查改操作的效率很高,时间复杂度均为 O(1) 。然而,矩阵的空间复杂度为 O(n2) ,内存占用较多。
2. 邻接表
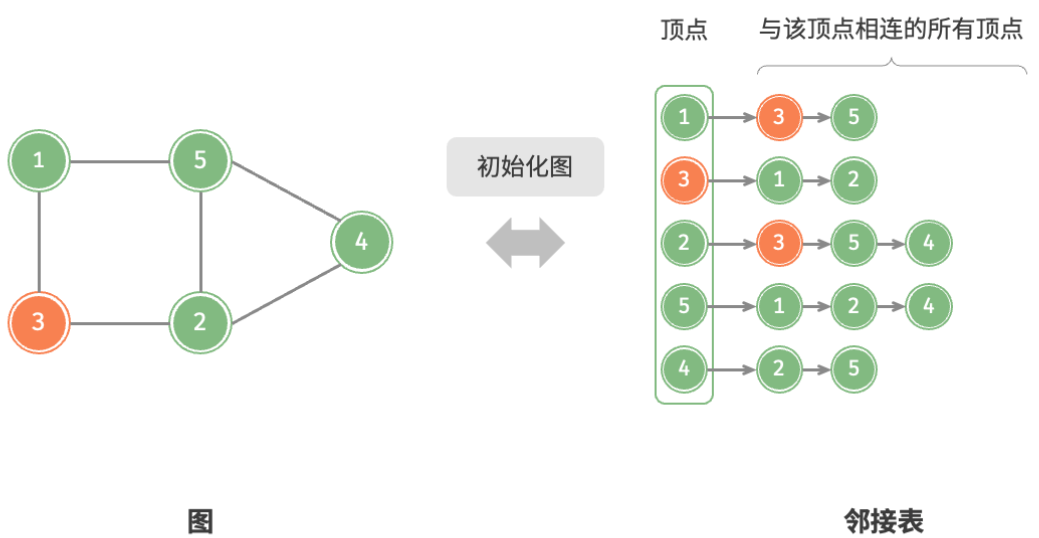
邻接表(adjacency list)使用 n 个链表来表示图,链表节点表示顶点。第 i 个链表对应顶点 i ,其中存储了该顶点的所有邻接顶点(与该顶点相连的顶点)。
图展示了一个使用邻接表存储的图的示例。
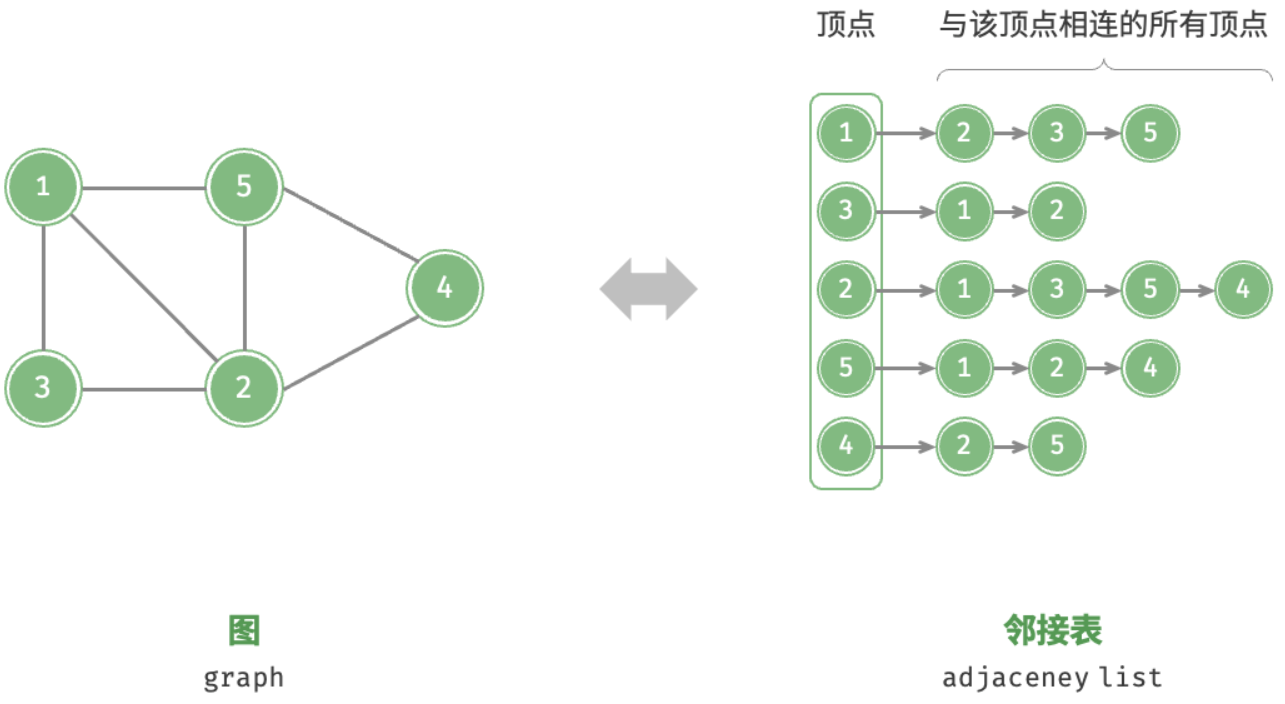
邻接表仅存储实际存在的边,而边的总数通常远小于 n2 ,因此它更加节省空间。然而,在邻接表中需要通过遍历链表来查找边,因此其时间效率不如邻接矩阵。
观察图 ,邻接表结构与哈希表中的“链式地址”非常相似,因此我们也可以采用类似的方法来优化效率。比如当链表较长时,可以将链表转化为 AVL 树或红黑树,从而将时间效率从 O(n) 优化至 O(logn) ;还可以把链表转换为哈希表,从而将时间复杂度降至 O(1) 。
9.2 图的基础操作
图的基础操作可分为对“边”的操作和对“顶点”的操作。在“邻接矩阵”和“邻接表”两种表示方法下,实现方式有所不同。
9.2.1 基于邻接矩阵的实现
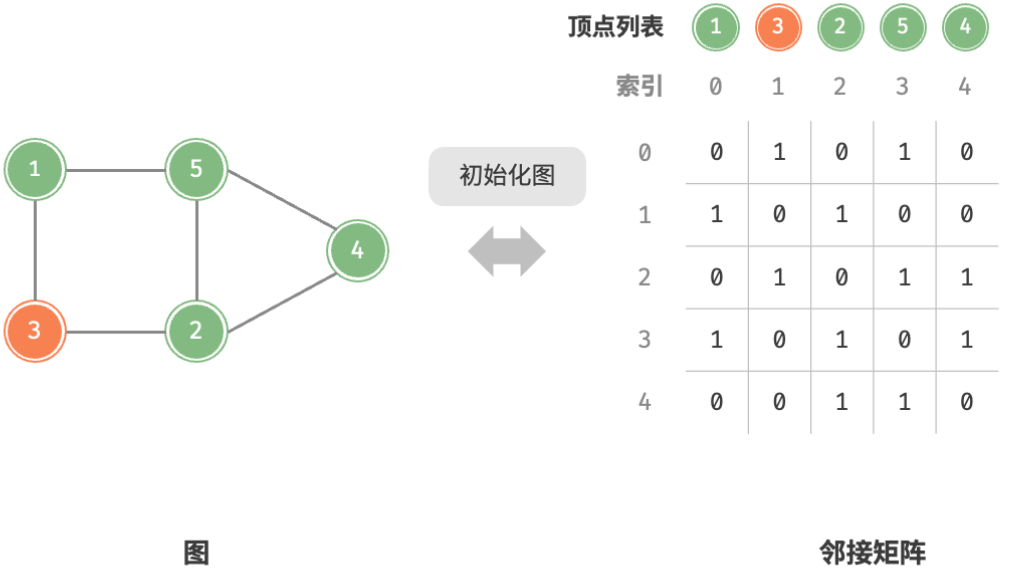
给定一个顶点数量为 n 的无向图,则各种操作的实现方式如图所示。
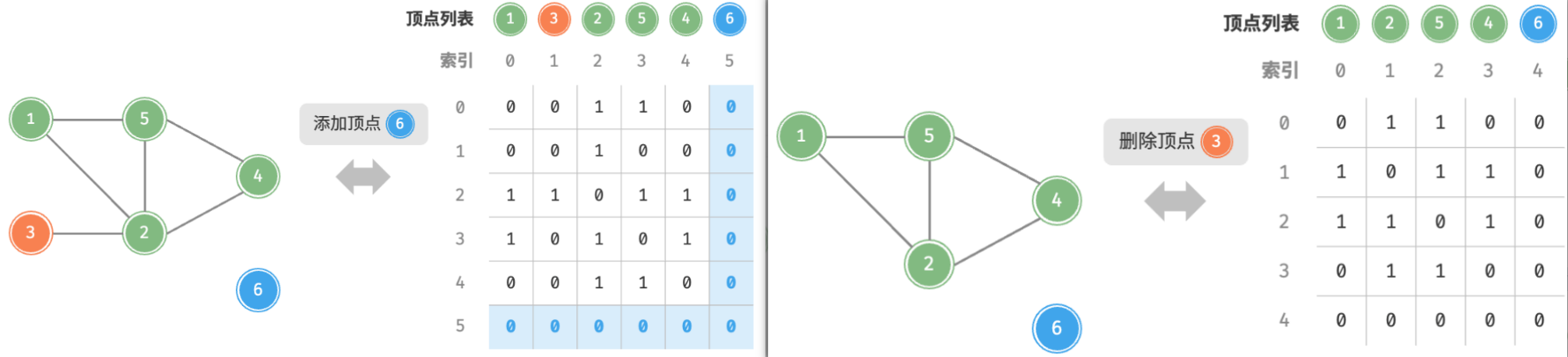
- 添加或删除边:直接在邻接矩阵中修改指定的边即可,使用 O(1) 时间。而由于是无向图,因此需要同时更新两个方向的边。
- 添加顶点:在邻接矩阵的尾部添加一行一列,并全部填 0 即可,使用 O(n) 时间。
- 删除顶点:在邻接矩阵中删除一行一列。当删除首行首列时达到最差情况,需要将 (n−1)2 个元素“向左上移动”,从而使用 O(n2) 时间。
- 初始化:传入 n 个顶点,初始化长度为 n 的顶点列表
vertices,使用 O(n) 时间;初始化 n×n 大小的邻接矩阵adjMat,使用 O(n2) 时间。
以下是基于邻接矩阵表示图的实现代码:
1 | |
9.2.2 基于邻接表的实现
设无向图的顶点总数为 n、边总数为 m ,则可根据图所示的方法实现各种操作。
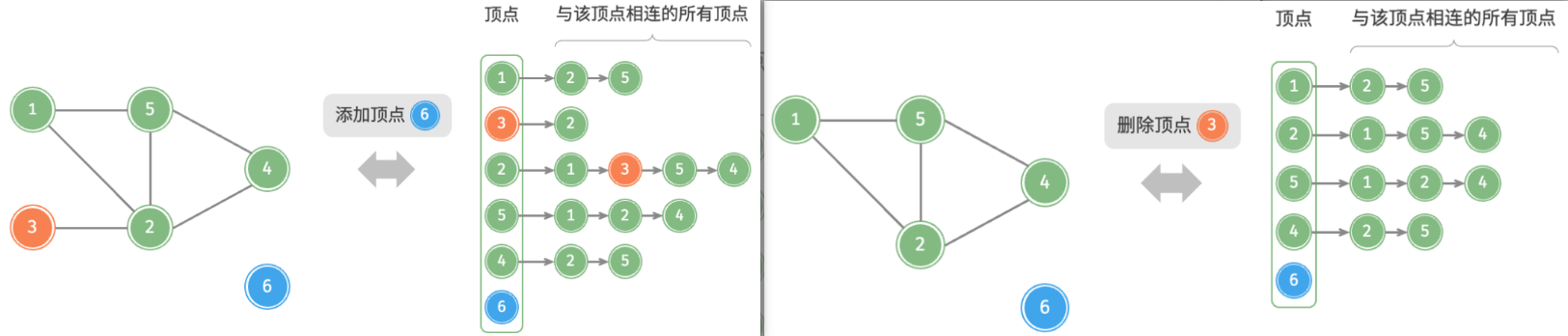
- 添加边:在顶点对应链表的末尾添加边即可,使用 O(1) 时间。因为是无向图,所以需要同时添加两个方向的边。
- 删除边:在顶点对应链表中查找并删除指定边,使用 O(m) 时间。在无向图中,需要同时删除两个方向的边。
- 添加顶点:在邻接表中添加一个链表,并将新增顶点作为链表头节点,使用 O(1) 时间。
- 删除顶点:需遍历整个邻接表,删除包含指定顶点的所有边,使用 O(n+m) 时间。
- 初始化:在邻接表中创建 n 个顶点和 2m 条边,使用 O(n+m) 时间。

以下是邻接表的代码实现,对比邻接矩阵,实际代码有以下不同。
- 为了方便添加与删除顶点,以及简化代码,我们使用列表(动态数组)来代替链表。
- 使用哈希表来存储邻接表,**
key为顶点实例,value为该顶点的邻接顶点列表**(链表)。另外,我们在邻接表中使用
Vertex类来表示顶点,这样做的原因是:如果与邻接矩阵一样,用列表索引来区分不同顶点,那么假设要删除索引为 i 的顶点,则需遍历整个邻接表,将所有大于 i 的索引全部减 1 ,效率很低。而如果每个顶点都是唯一的Vertex实例,删除某一顶点之后就无须改动其他顶点了。
1 | |
9.2.3 效率对比
设图中共有 n 个顶点和 m 条边,表 9-2 对比了邻接矩阵和邻接表的时间效率和空间效率。
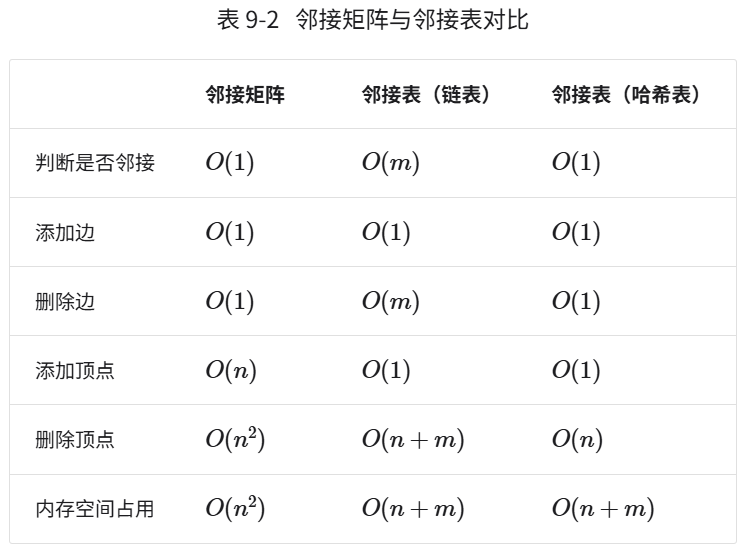
观察表似乎邻接表(哈希表)的时间效率与空间效率最优。但实际上,在邻接矩阵中操作边的效率更高,只需一次数组访问或赋值操作即可。综合来看,邻接矩阵体现了“以空间换时间”的原则,而邻接表体现了“以时间换空间”的原则。
9.3 图的遍历
树代表的是“一对多”的关系,而图则具有更高的自由度,可以表示任意的“多对多”关系。因此,我们可以把树看作图的一种特例。显然,树的遍历操作也是图的遍历操作的一种特例。
图和树都要应用搜索算法来实现遍历操作。图的遍历方式也可分为两种:广度优先遍历和深度优先遍历
9.3.1 广度优先遍历
**广度优先遍历是一种==由近及远==的遍历方式,从某个节点出发,始终==优先访问距离最近的顶点==,并==一层层向外扩张==**。
如图所示,从左上角顶点出发,首先遍历该顶点的所有邻接顶点,然后遍历下一个顶点的所有邻接顶点,以此类推,直至所有顶点访问完毕。
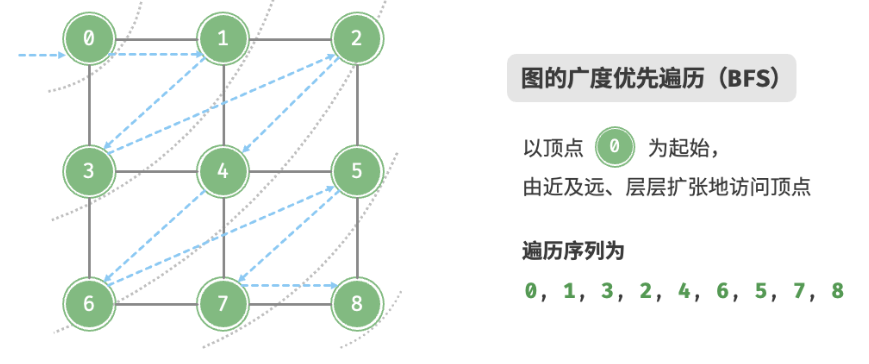
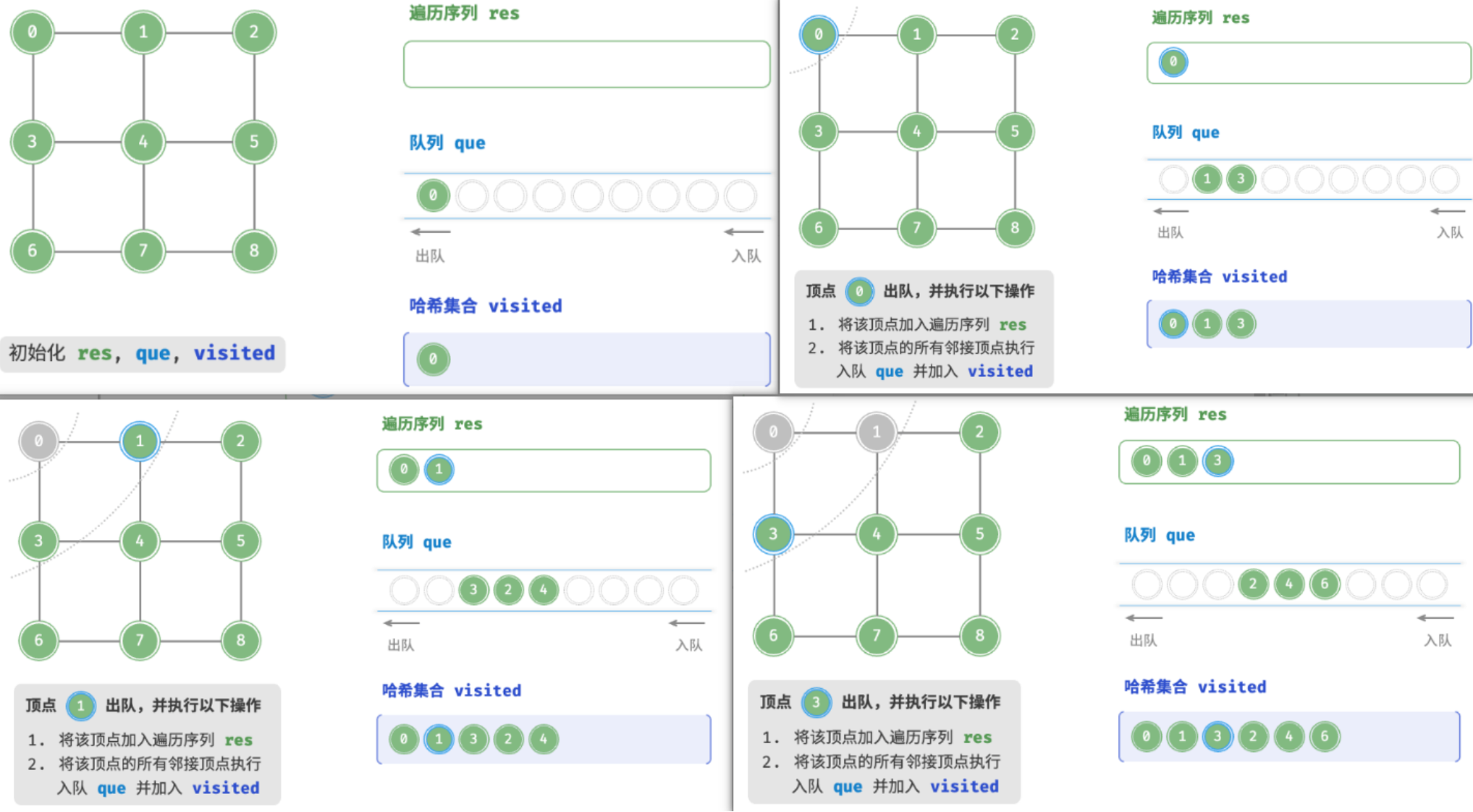
BFS 通常借助队列来实现,代码如下所示。队列具有“先入先出”的性质,这与 BFS 的“由近及远”的思想异曲同工。
- 将遍历起始顶点
startVet加入队列,并开启循环。- 在循环的每轮迭代中,弹出队首顶点并记录访问,然后将该顶点的所有邻接顶点加入到队列尾部。
- 循环步骤
2.,直到所有顶点被访问完毕后结束。为了防止重复遍历顶点,我们需要借助一个哈希集合
visited来记录哪些节点已被访问。
哈希集合可以看作一个只存储
key而不存储value的哈希表,它可以在 O(1) 时间复杂度下进行key的增删查改操作。根据key的唯一性,哈希集合通常用于数据去重等场景。
1 | |
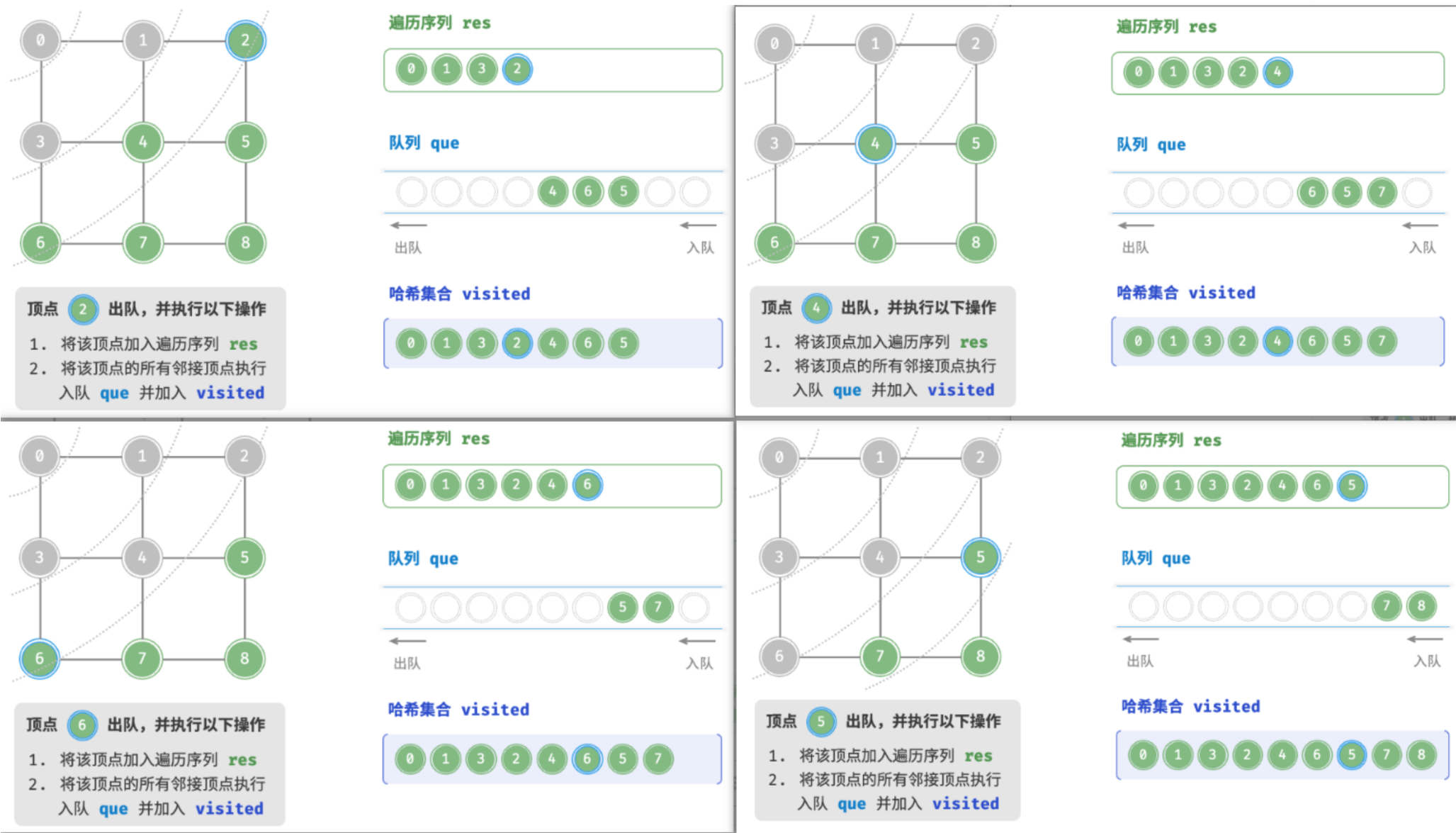
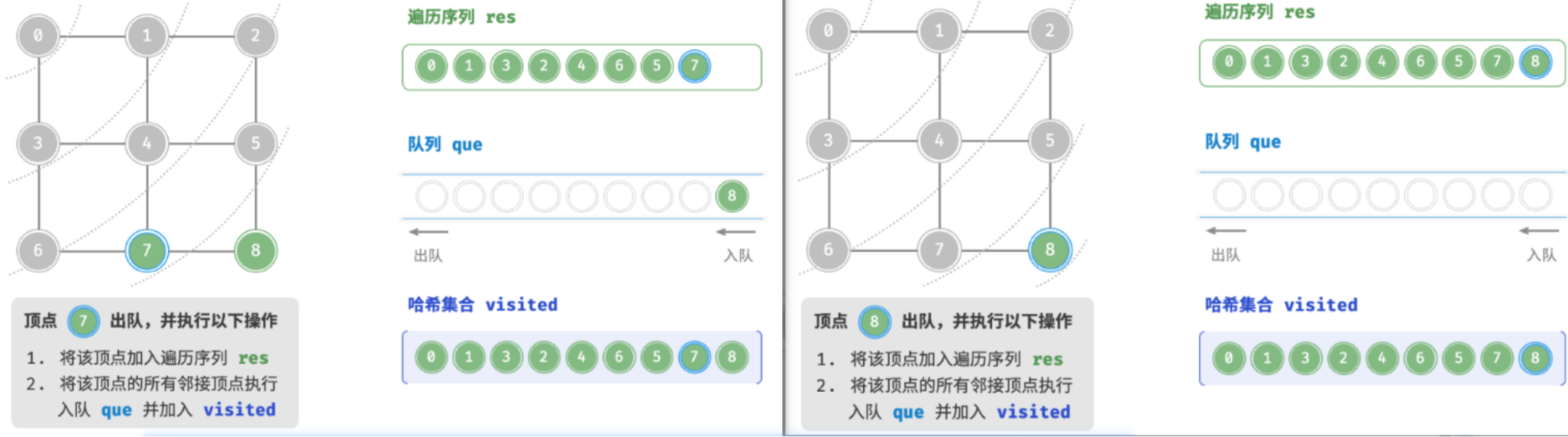
广度优先遍历的序列是否唯一?
不唯一。广度优先遍历只要求按“由近及远”的顺序遍历,而多个相同距离的顶点的遍历顺序允许被任意打乱。以图为例,顶点 1、3 的访问顺序可以交换,顶点 2、4、6 的访问顺序也可以任意交换。
复杂度分析
时间复杂度:所有顶点都会入队并出队一次,使用 O(|V|) 时间;在遍历邻接顶点的过程中,由于是无向图,因此所有边都会被访问 2 次,使用 O(2|E|) 时间;总体使用 O(|V|+|E|) 时间。
空间复杂度:列表
res,哈希集合visited,队列que中的顶点数量最多为 |V| ,使用 O(|V|) 空间。
9.3.2 深度优先遍历
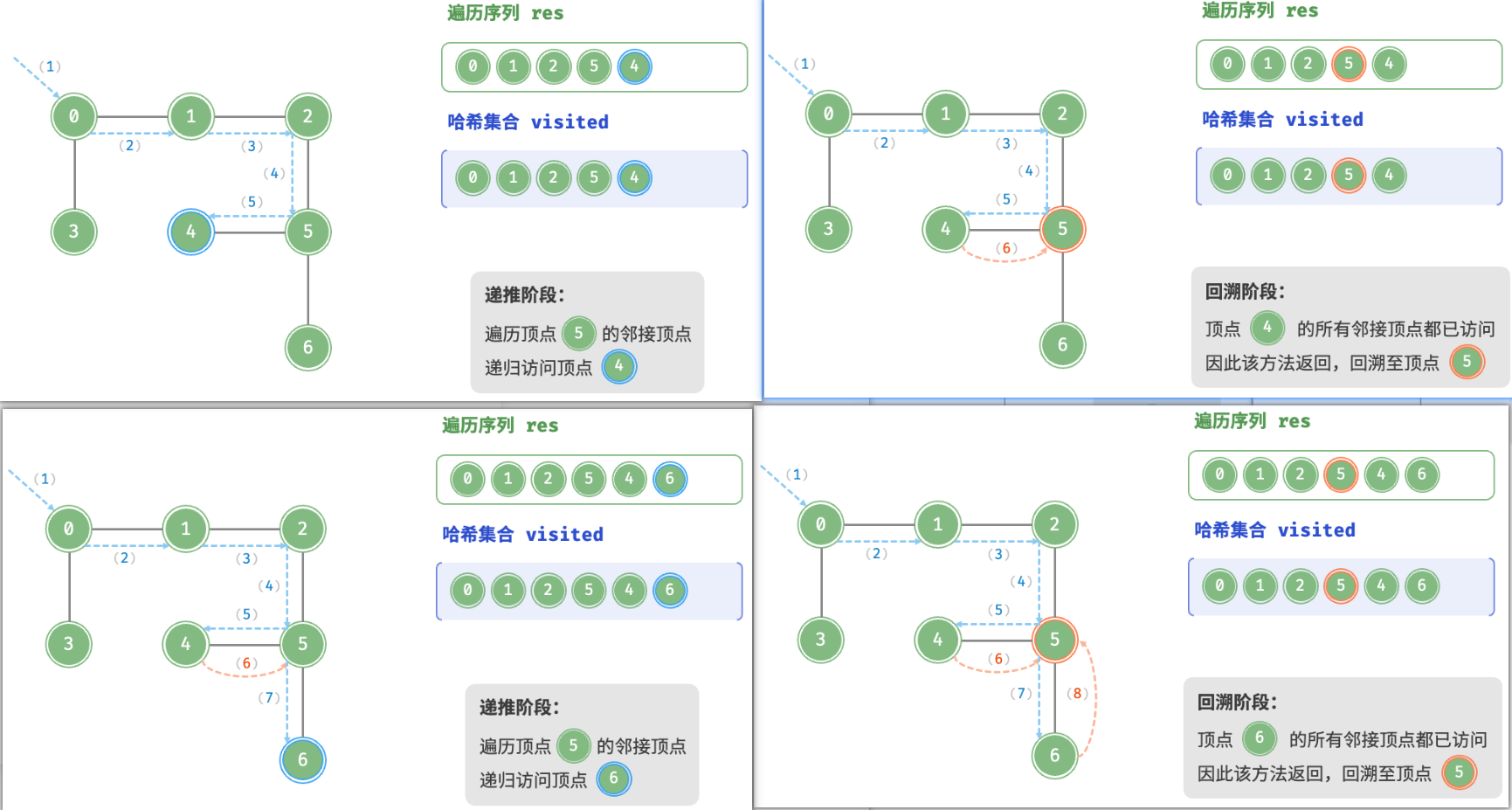
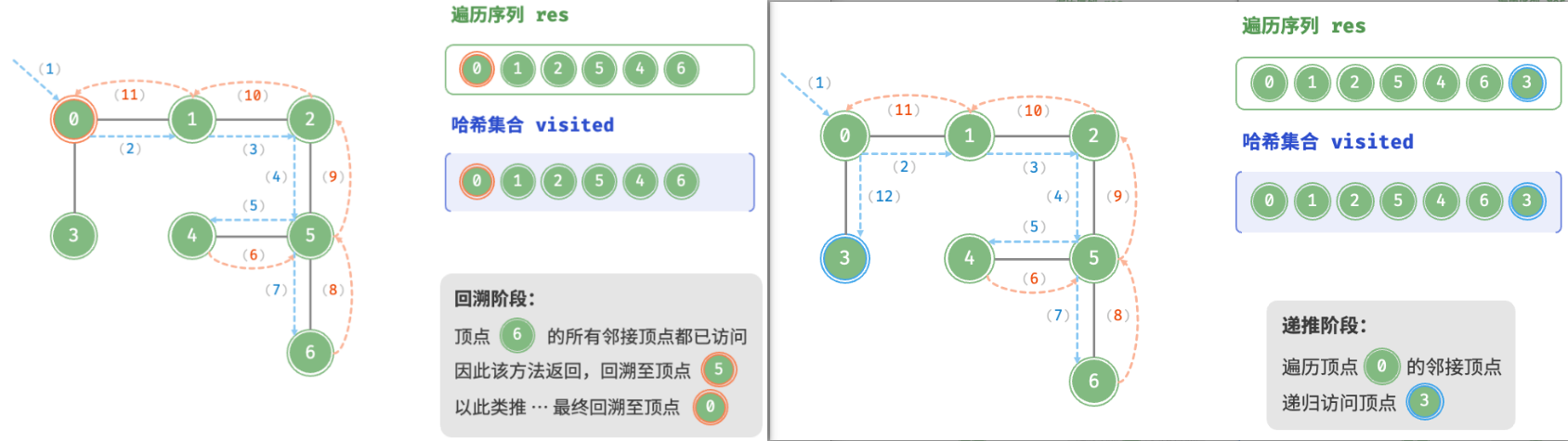
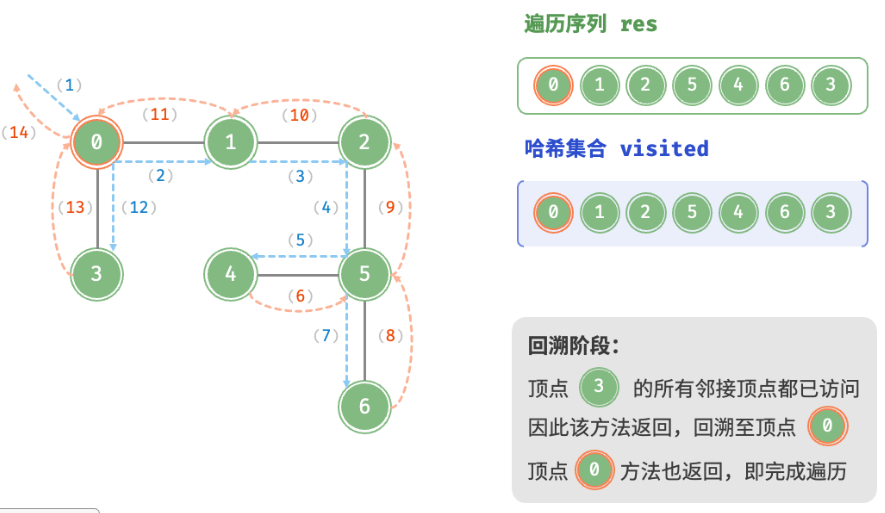
深度优先遍历是一种==优先走到底==、==无路可走再回头==的遍历方式。如图所示,从左上角顶点出发,访问当前顶点的某个邻接顶点,直到走到尽头时返回,再继续走到尽头并返回,以此类推,直至所有顶点遍历完成。
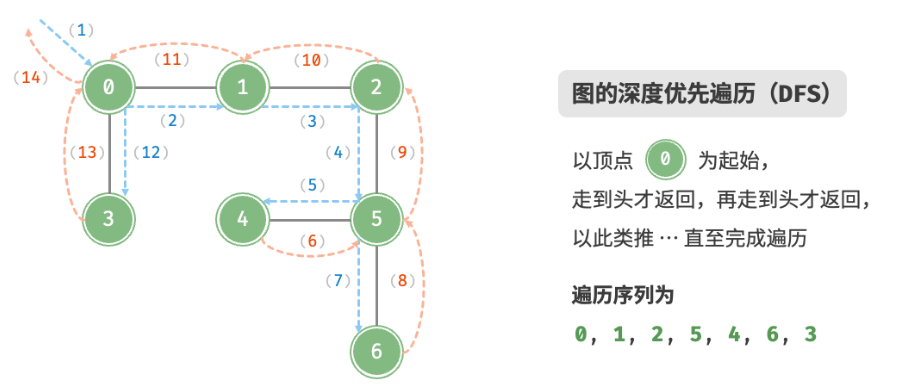
这种“走到尽头再返回”的算法范式通常基于递归来实现。与广度优先遍历类似,在深度优先遍历中,我们也需要借助一个哈希集合
visited来记录已被访问的顶点,以避免重复访问顶点。
1 | |
深度优先遍历的算法流程如图所示。
- 直虚线代表向下递推,表示开启了一个新的递归方法来访问新顶点。
- 曲虚线代表向上回溯,表示此递归方法已经返回,回溯到了开启此方法的位置。
为了加深理解,建议将图与代码结合起来,在脑中模拟(或者用笔画下来)整个 DFS 过程,包括每个递归方法何时开启、何时返回。
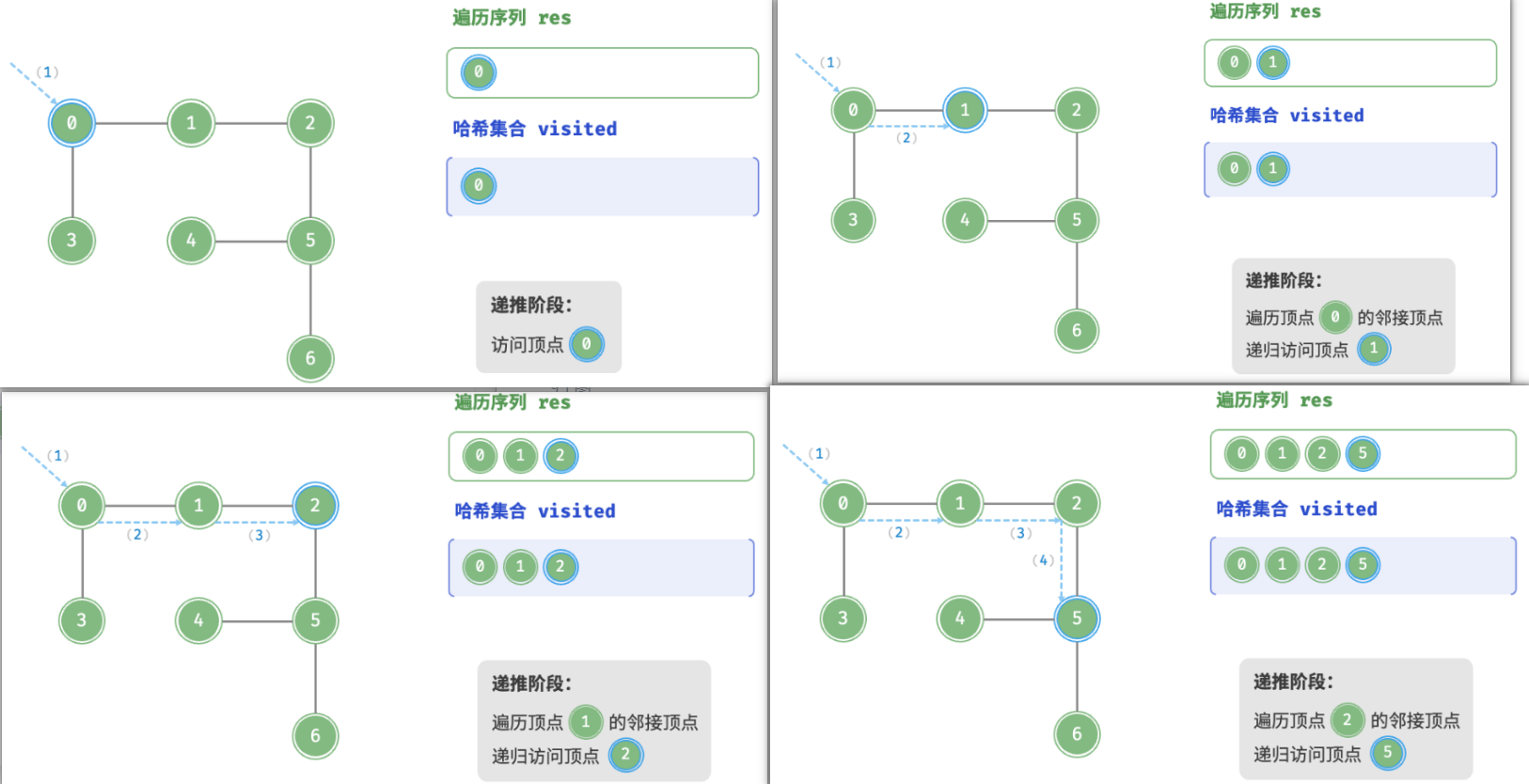
深度优先遍历的序列是否唯一?
与广度优先遍历类似,深度优先遍历序列的顺序也不是唯一的。给定某顶点,先往哪个方向探索都可以,即邻接顶点的顺序可以任意打乱,都是深度优先遍历。
以树的遍历为例,“根 → 左 → 右”“左 → 根 → 右”“左 → 右 → 根”分别对应前序、中序、后序遍历,它们展示了三种遍历优先级,然而这三者都属于深度优先遍历。
复杂度分析
时间复杂度:所有顶点都会被访问 1 次,使用 O(|V|) 时间;所有边都会被访问 2 次,使用 O(2|E|) 时间;总体使用 O(|V|+|E|) 时间。
空间复杂度:列表
res,哈希集合visited顶点数量最多为 |V| ,递归深度最大为 |V| ,因此使用 O(|V|) 空间。
算法
十、搜索
搜索是一场未知的冒险,我们或许需要走遍神秘空间的每个角落,又或许可以快速锁定目标。
在这场寻觅之旅中,每一次探索都可能得到一个未曾料想的答案。
10.1 二分查找
二分查找(binary search)是一种基于分治策略的高效搜索算法。它利用数据的有序性,每轮缩小一半搜索范围,直至找到目标元素或搜索区间为空为止。
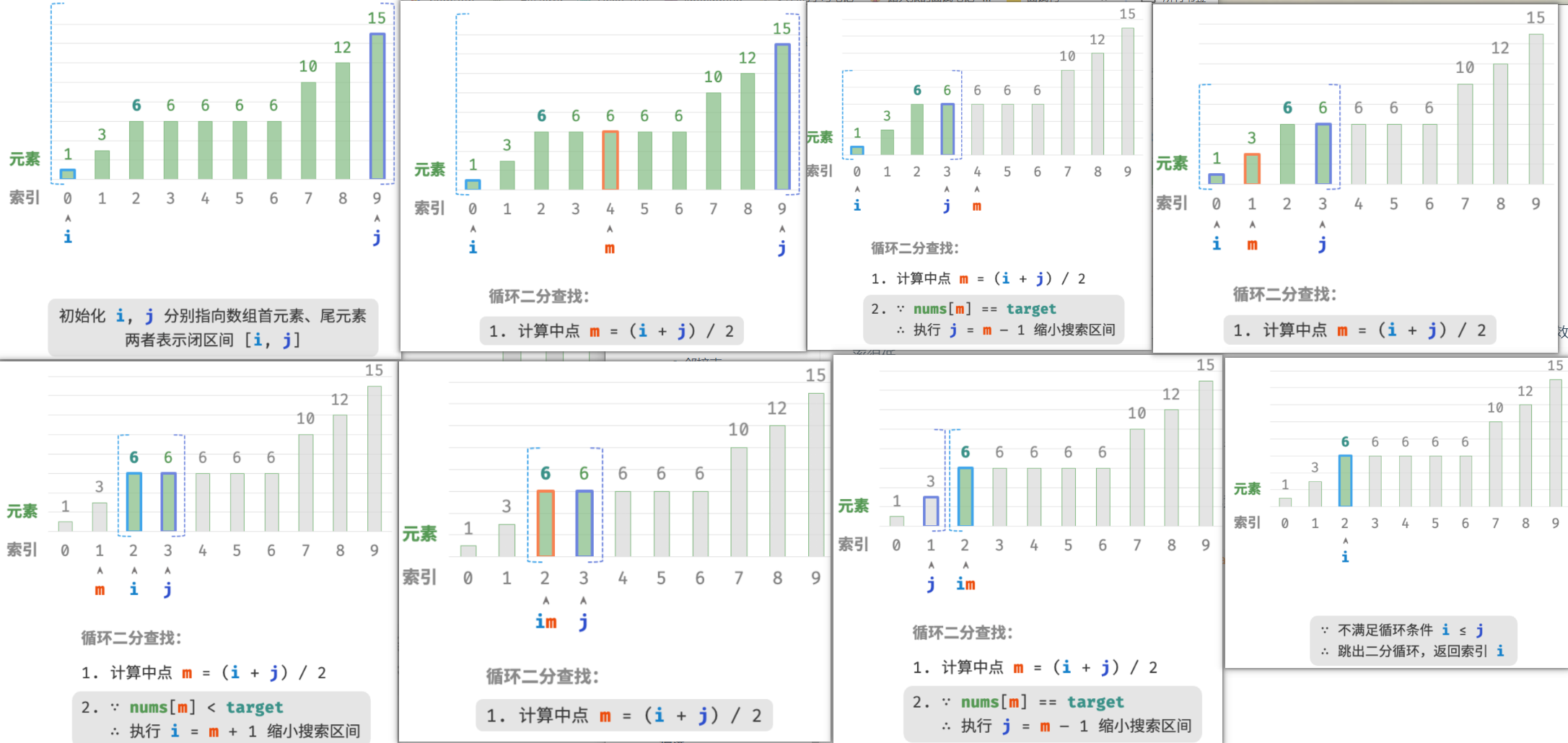
给定一个长度为 n 的数组 nums ,元素按从小到大的顺序排列且不重复。请查找并返回元素 target 在该数组中的索引。若数组不包含该元素,则返回 −1 。示例如图所示。
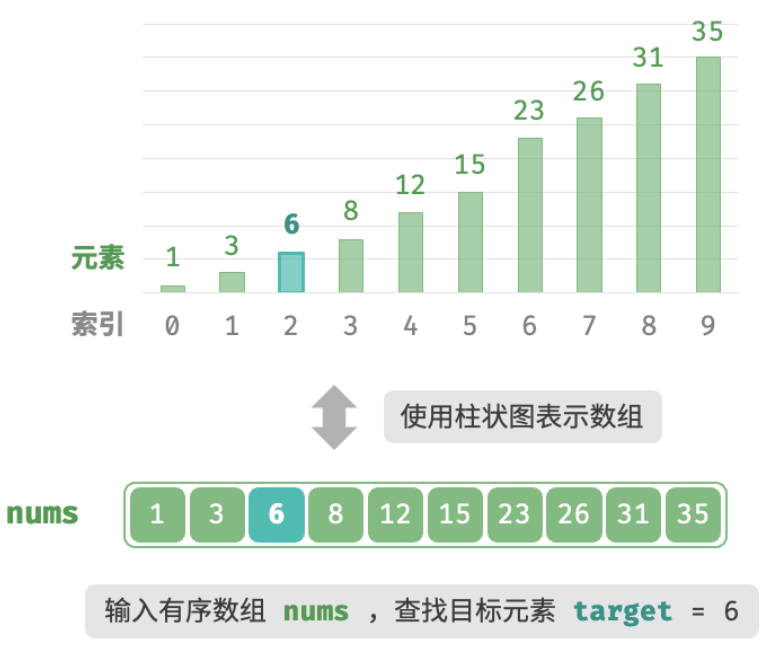

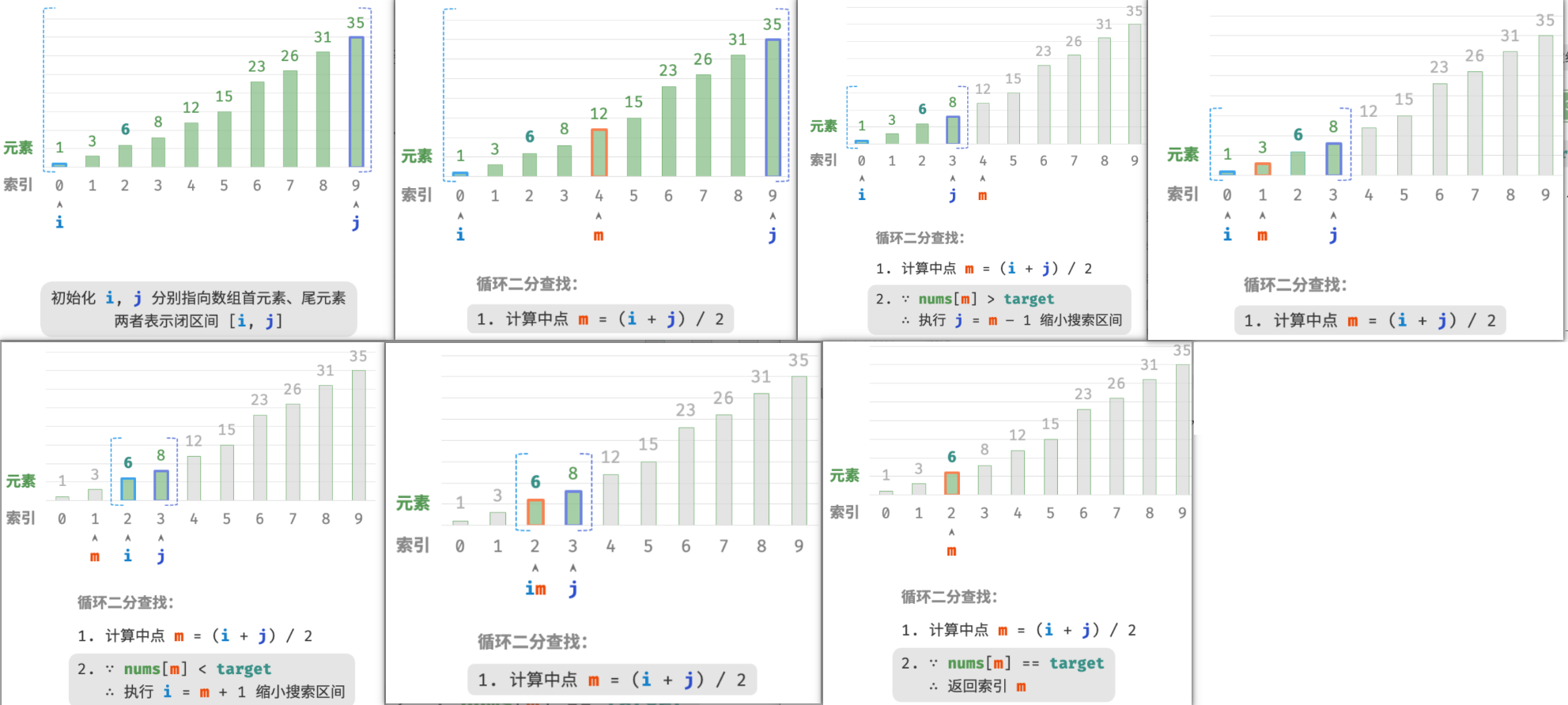
由于 i 和 j 都是 int 类型,因此 i+j 可能会超出 int 类型的取值范围。为了避免大数越界,我们通常采用公式 m=⌊i+(j−i)/2⌋ 来计算中点。
1 | |
时间复杂度为 O(logn) :在二分循环中,区间每轮缩小一半,因此循环次数为 log2n 。
空间复杂度为 O(1) :指针 i 和 j 使用常数大小空间。
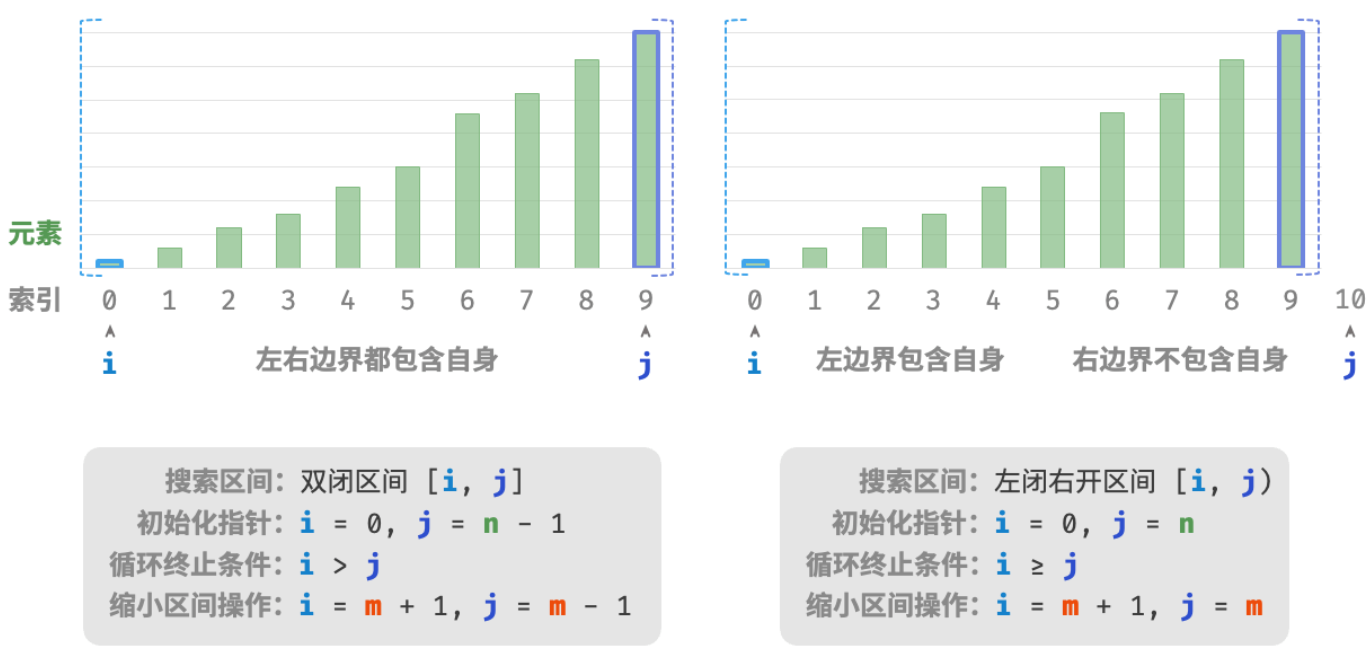
10.1.1 区间表示方法
除了上述双闭区间外,常见的区间表示还有“左闭右开”区间,定义为 [0,n) ,即左边界包含自身,右边界不包含自身。在该表示下,区间 [i,j) 在 i=j 时为空。
我们可以基于该表示实现具有相同功能的二分查找算法:
1 | |
在两种区间表示下,二分查找算法的初始化、循环条件和缩小区间操作皆有所不同。
由于“双闭区间”表示中的左右边界都被定义为闭区间,因此通过指针 i 和指针 j 缩小区间的操作也是对称的。这样更不容易出错,因此一般建议采用“双闭区间”的写法。
10.1.2 优点与局限性
二分查找在时间和空间方面都有较好的性能:
- 二分查找的时间效率高。在大数据量下,对数阶的时间复杂度具有显著优势。当数据大小 n=220 时,线性查找需要 220=1048576 轮循环,而二分查找仅需 log2220=20 轮循环。
- 二分查找无须额外空间。相较于需要借助额外空间的搜索算法(例如哈希查找),二分查找更加节省空间。
然而,二分查找并非适用于所有情况,主要有以下原因:
- 二分查找仅适用于有序数据。若输入数据无序,为了使用二分查找而专门进行排序,得不偿失。因为排序算法的时间复杂度通常为 O(nlogn) ,比线性查找和二分查找都更高。对于频繁插入元素的场景,为保持数组有序性,需要将元素插入到特定位置,时间复杂度为 O(n) ,也是非常昂贵的。
- 二分查找仅适用于数组。二分查找需要跳跃式(非连续地)访问元素,而在链表中执行跳跃式访问的效率较低,因此不适合应用在链表或基于链表实现的数据结构。
- 小数据量下,线性查找性能更佳。在线性查找中,每轮只需 1 次判断操作;而在二分查找中,需要 1 次加法、1 次除法、1 ~ 3 次判断操作、1 次加法(减法),共 4 ~ 6 个单元操作;因此,当数据量 n 较小时,线性查找反而比二分查找更快。
10.2 二分查找插入点
二分查找不仅可用于搜索目标元素,还可用于解决许多变种问题,比如搜索目标元素的插入位置。
10.2.1 无重复元素的情况
给定一个长度为 n 的有序数组 nums 和一个元素 target ,数组不存在重复元素。现将 target 插入数组 nums 中,并保持其有序性。若数组中已存在元素 target ,则插入到其左方。请返回插入后 target 在数组中的索引。示例如图所示。
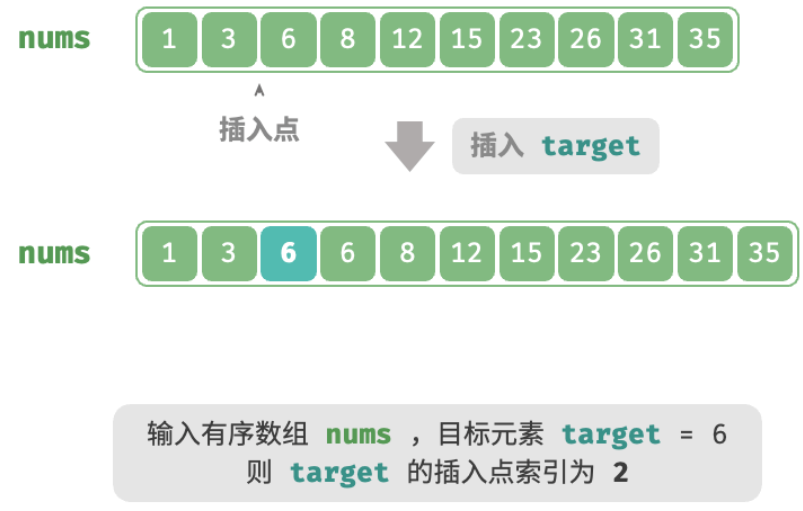
如果想复用上一节的二分查找代码,则需要回答以下两个问题。
问题一:当数组中包含
target时,插入点的索引是否是该元素的索引?题目要求将
target插入到相等元素的左边,这意味着新插入的target替换了原来target的位置。也就是说,当数组包含target时,插入点的索引就是该target的索引。问题二:当数组中不存在
target时,插入点是哪个元素的索引?进一步思考二分查找过程:当
nums[m] < target时 i 移动,这意味着指针 i 在向大于等于target的元素靠近。同理,指针 j 始终在向小于等于target的元素靠近。因此二分结束时一定有:B。易得当数组不包含
target时,插入索引为 i 。代码如下所示:
1 | |
10.2.2 存在重复元素的情况
在上一题的基础上,规定数组可能包含重复元素,其余不变。
假设数组中存在多个 target ,则普通二分查找只能返回其中一个 target 的索引,**而无法确定该元素的左边和右边还有多少 target**。
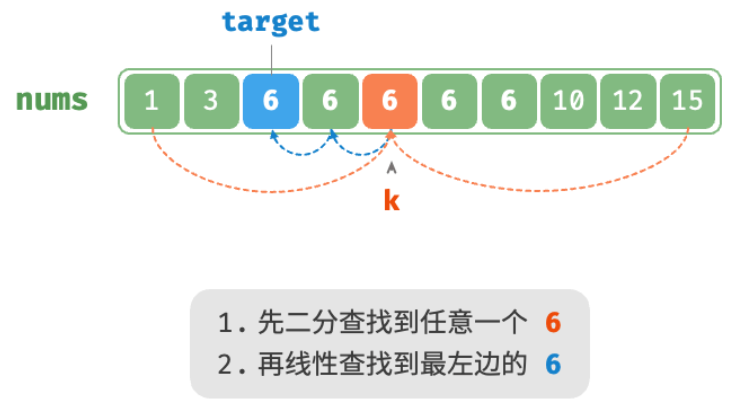
题目要求将目标元素插入到最左边,所以我们需要查找数组中最左一个 target 的索引。初步考虑通过图所示的步骤实现。
- 执行二分查找,得到任意一个
target的索引,记为 k 。 - 从索引 k 开始,向左进行线性遍历,当找到最左边的
target时返回。
此方法虽然可用,但其包含线性查找,因此时间复杂度为 O(n) 。当数组中存在很多重复的 target 时,该方法效率很低。
现考虑拓展二分查找代码。如图所示,整体流程保持不变,每轮先计算中点索引 m ,再判断 target 和 nums[m] 的大小关系,分为以下几种情况。
- 当
nums[m] < target或nums[m] > target时,说明还没有找到target,因此采用普通二分查找的缩小区间操作,从而使指针 i 和 j 向target靠近。 - 当
nums[m] == target时,说明小于target的元素在区间 [i,m−1] 中,因此采用 j=m−1 来缩小区间,从而使指针 j 向小于target的元素靠近。
循环完成后,i 指向最左边的 target ,j 指向首个小于 target 的元素,因此索引 i 就是插入点。
观察以下代码,判断分支 nums[m] > target 和 nums[m] == target 的操作相同,因此两者可以合并。
即便如此,我们仍然可以将判断条件保持展开,因为其逻辑更加清晰、可读性更好。
1 | |
总的来看,二分查找无非就是给指针 i 和 j 分别设定搜索目标,目标可能是一个具体的元素(例如 target ),也可能是一个元素范围(例如小于 target 的元素)。
在不断的循环二分中,指针 i 和 j 都逐渐逼近预先设定的目标。最终,它们或是成功找到答案,或是越过边界后停止。
10.3 二分查找边界
10.3.1 查找左边界
给定一个长度为 n 的有序数组 nums ,其中可能包含重复元素。请返回数组中最左一个元素 target 的索引。若数组中不包含该元素,则返回 −1 。
回忆二分查找插入点的方法,搜索完成后 i 指向最左一个 target ,因此查找插入点本质上是在查找最左一个 target 的索引。
考虑通过查找插入点的函数实现查找左边界。请注意,数组中可能不包含 target ,这种情况可能导致以下两种结果
- 插入点的索引 i 越界。
- 元素
nums[i]与target不相等。
当遇到以上两种情况时,直接返回 −1 即可。代码如下所示:
1 | |