1. Canal介绍
Releases · alibaba/canal
- Canal是一个组件,canal感知到MySQL数据变动,然后解析变动数据,将变动数据发送到MQ或者同步到其他数据库,等待进一步业务逻辑处理。
2. canal工作原理
2.1 MySQL的主从复制原理
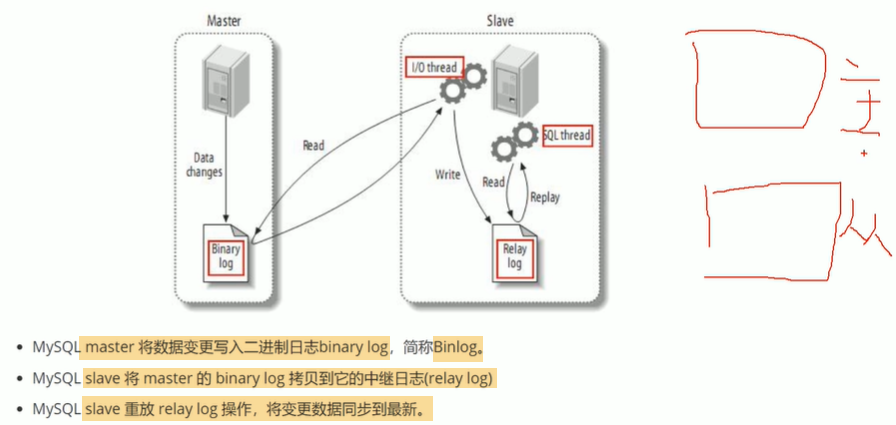
2.2 MySQL Binlog日志
2.2.1 介绍
- MySQL的Binlog是MySQL最重要的日志,记录所有的增删改(DML)和建表/改结构(DDL)操作。
- MySQL默认情况下是不开启Binlog,因为记录Binlog日志需要消耗时间,官方给出的数据是有1%的性能损耗。
- 具体开不开启,开发中需要根据实际情况做取舍。 一般来说,在下面两场景下会开启Binlog日志:
1️⃣MySQL主从集群部署时,需要在Master端开启Binlog,方便将数据同步到Slaves中
2️⃣数据恢复了,通过使用MySQLBinlog工具来使恢复数据。
2.2.2 Binlog的分类
- MySQL Binlog的格式有三种,分别是STATEMENT, MIXED,ROW。
- 在配置文件中可以选择配置binlog_format= statement | mixed | row。
| 分类 |
介绍 |
优点 |
缺点 |
| STATEMENT |
语句级别,记录每一次执行写操作的语句,相对于ROW模式节省了空间,但是可能产生数据不一致如update set create_date=now(),由于执行时间不同产生的数据就不同 |
节省空间 |
可能造成数据不一致 |
| ROW |
行级,记录每次操作后每行记录的变化。假如一个update的sql执行结果是1万行statement只存一条,如果是row的话会把这个1万行的结果存这。 |
持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果 |
占用较大空间 |
| MIXED |
是对statement的升级,如当函数中包含UUID时,包含AUTO_INCREMENT字段的表被更新时,执行INSERTDELAYED语句时,用UDF时,会按照ROW的方式进行处理 |
节省空间,同时兼顾了一定的一致性 |
还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便 |
- STATEMENT(语句级)格式:你告诉别人“去把饭炒一下”,但没告诉他加了哪些调料,不同人做出来味道不同。
- ROW(行级)格式:你告诉别人“把这个菜炒成这个味道”,详细到每一克盐、油、火候,结果完全一样,但要讲很多很多细节。
- MIXED(混合)格式:有时候说“去炒饭”(简单的语句),有时候说“把米、菜、调料都列出来”(复杂情况),比较灵活,但别人可能不好还原全过程。
综上对比,Canal想做监控分析,选择ROW格式比较合适
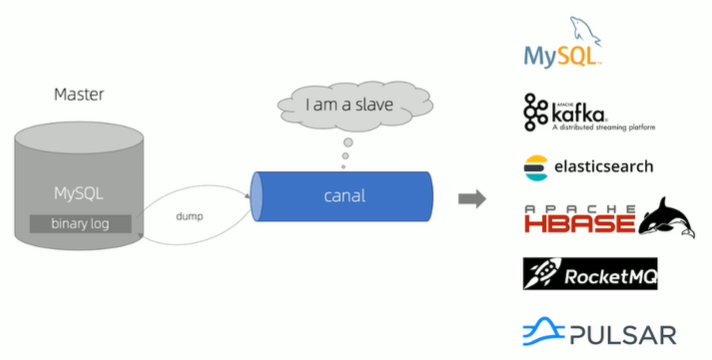
2.3 Canal工作原理
- Canal模拟MysQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议
- MySQL master收到dump请求,开始推送binary log给slave(即canal)
- Canal解析Binlog对象(原始为byte流)
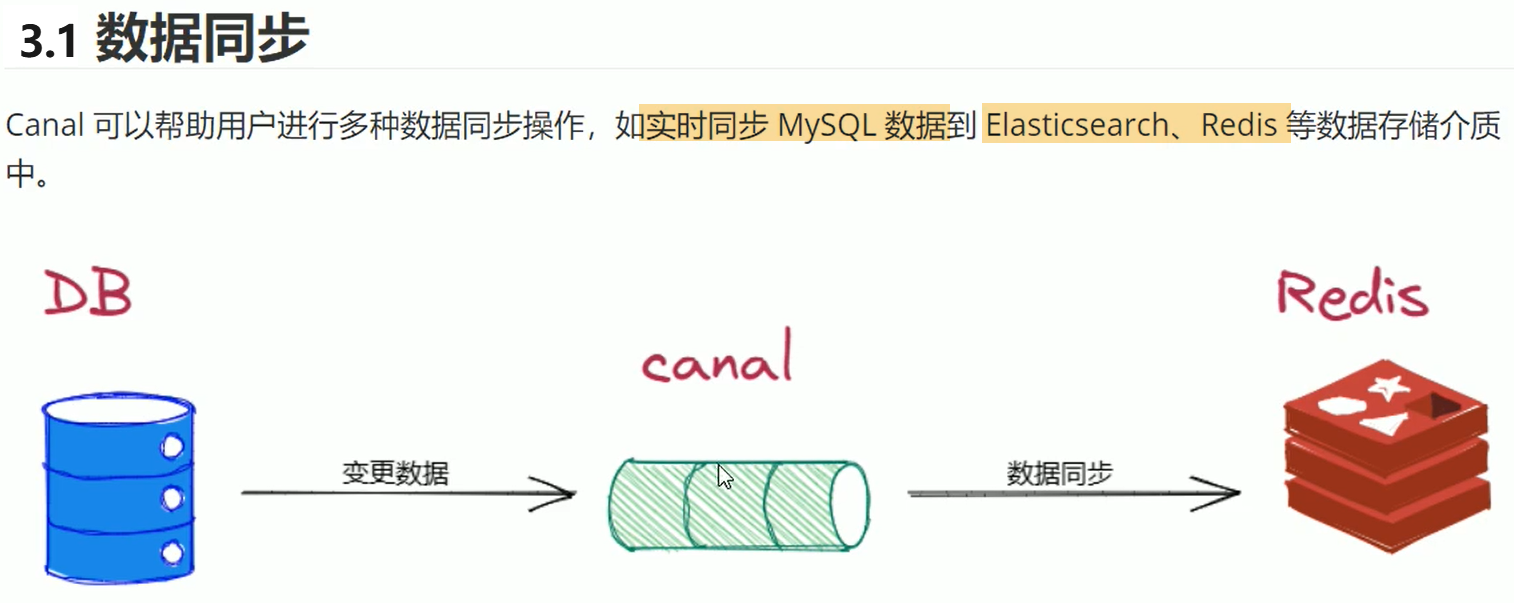
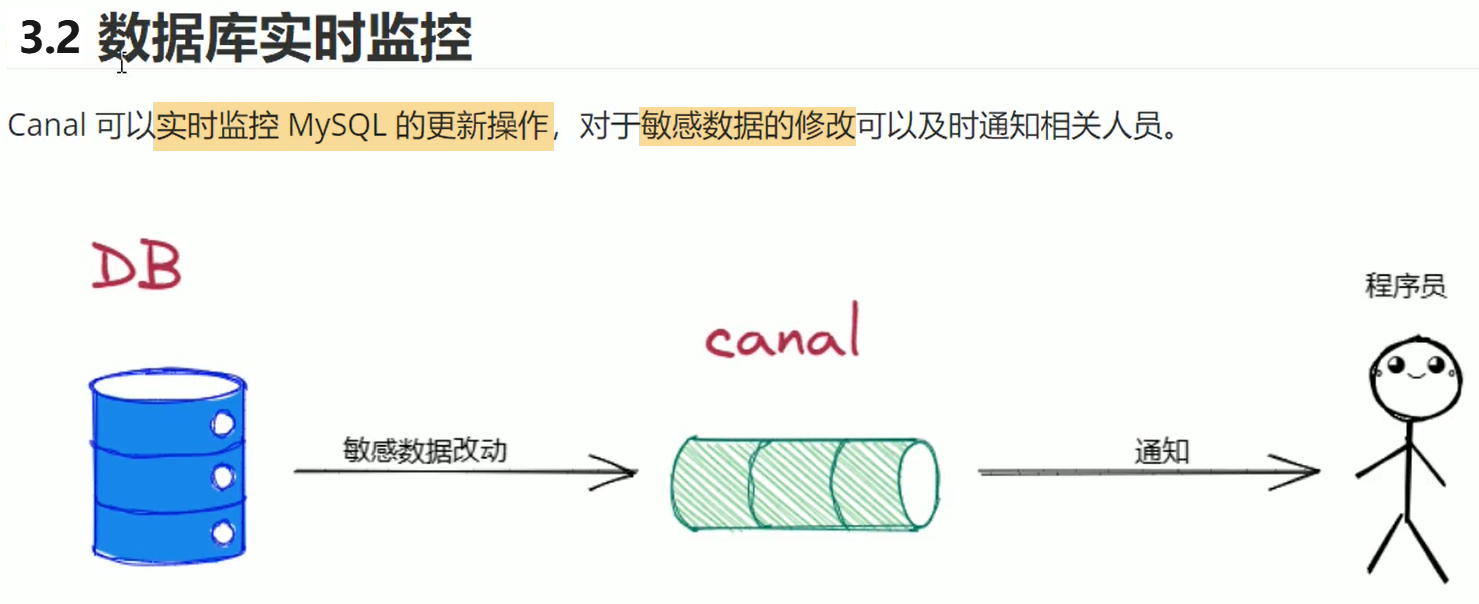
3. Canal运用场景
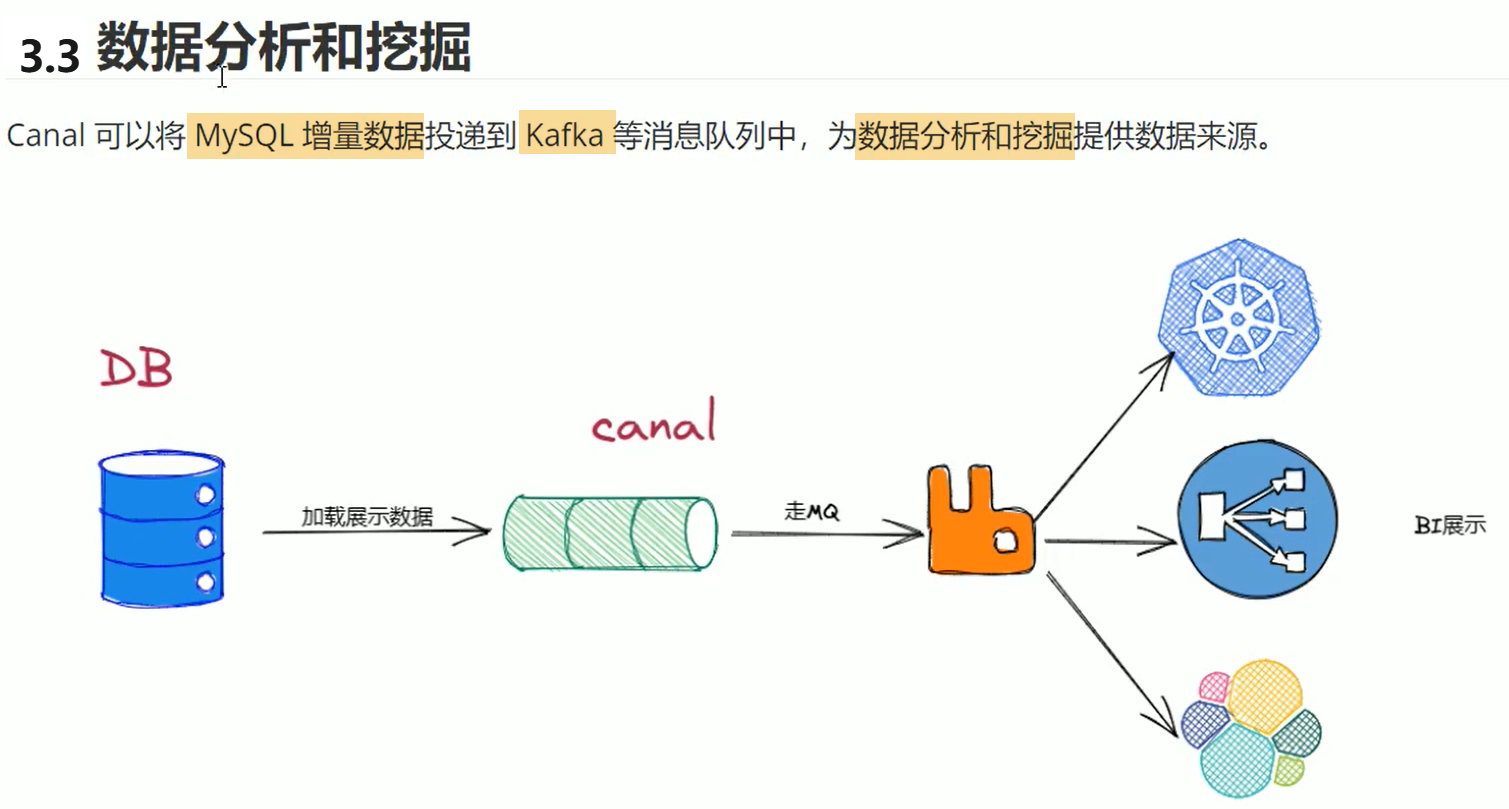

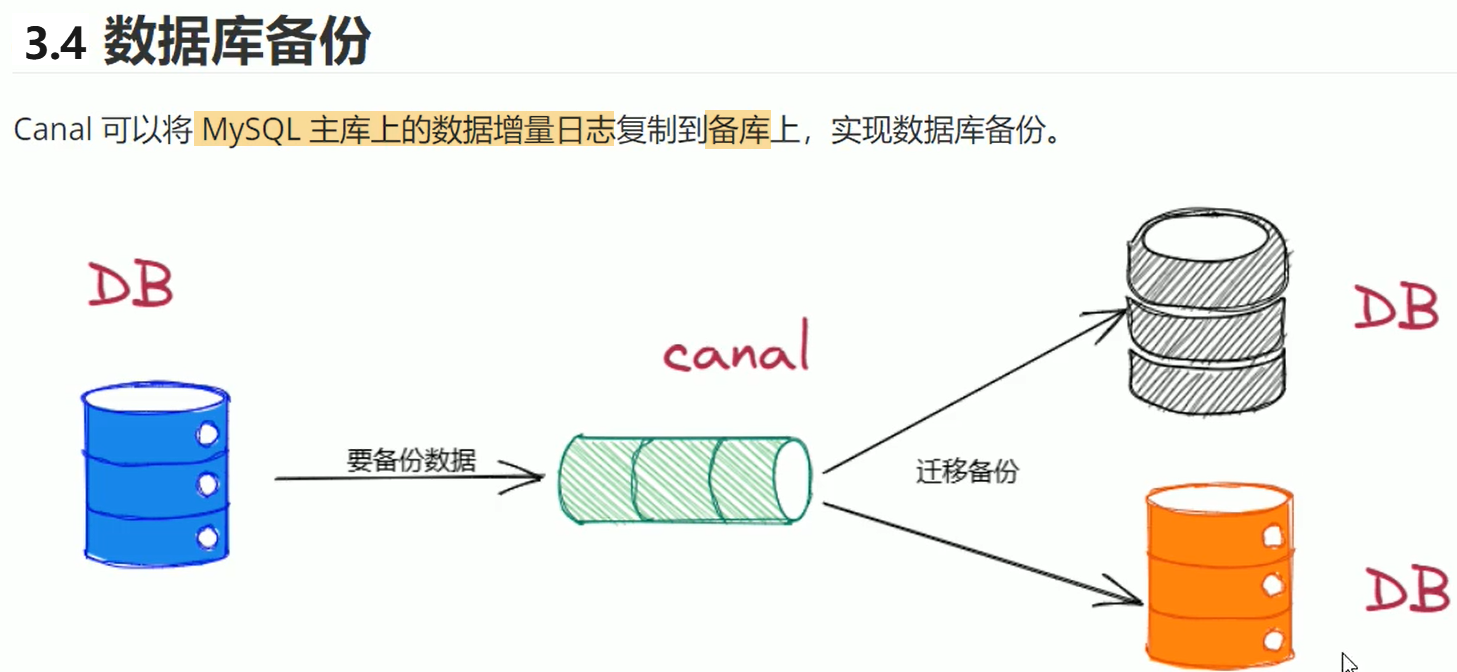
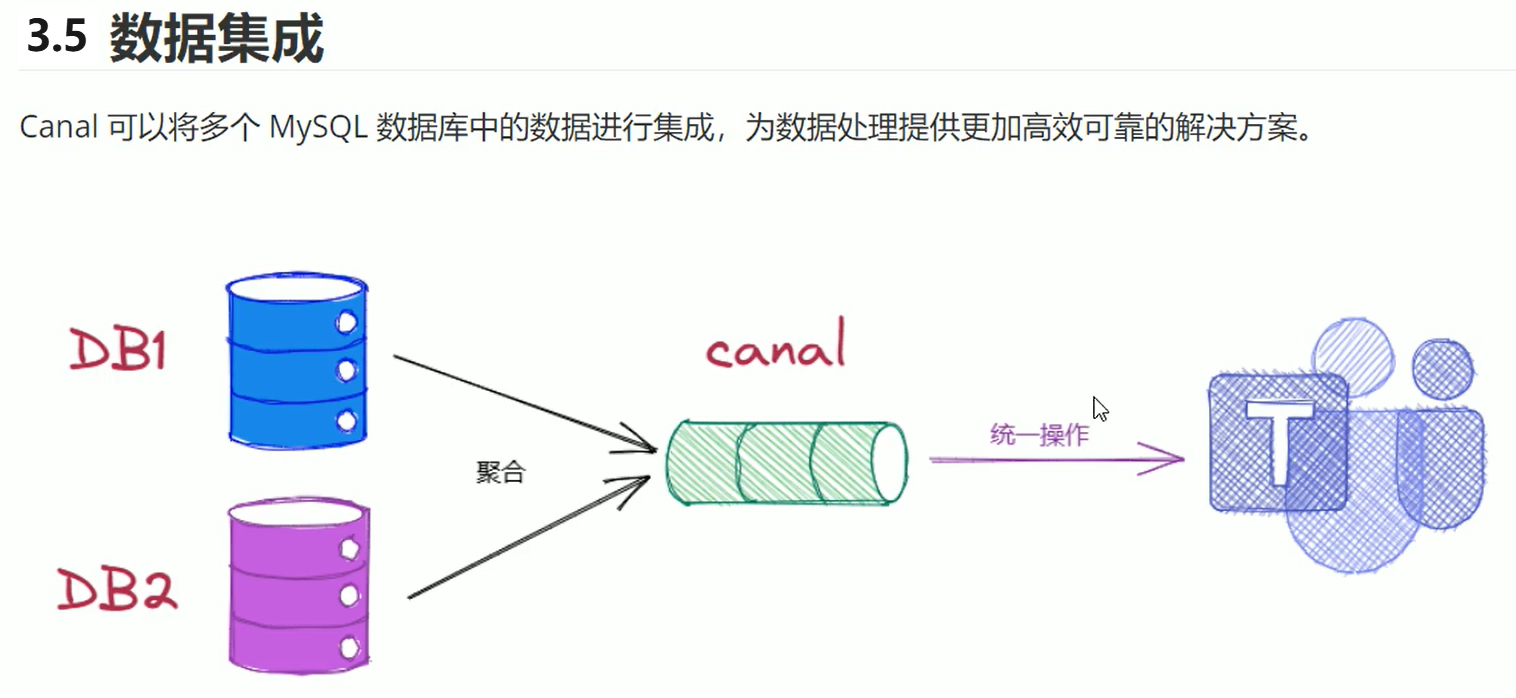
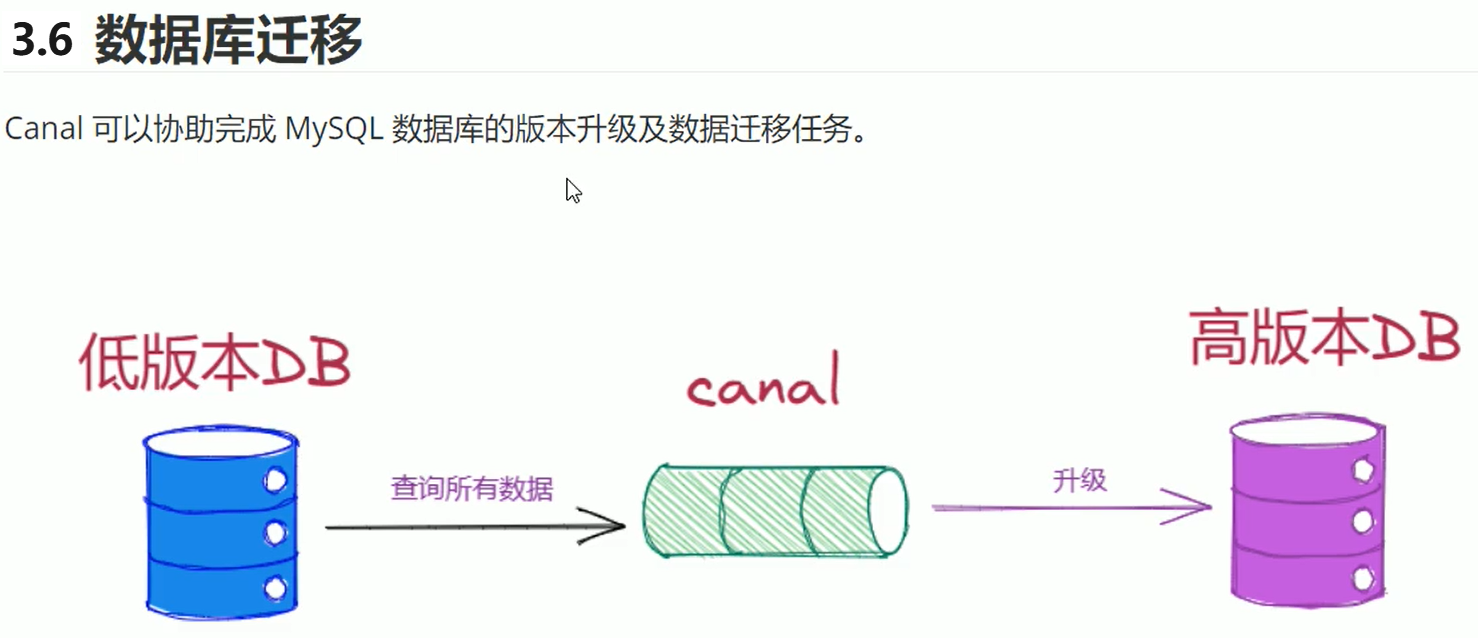
4. MySQL准备
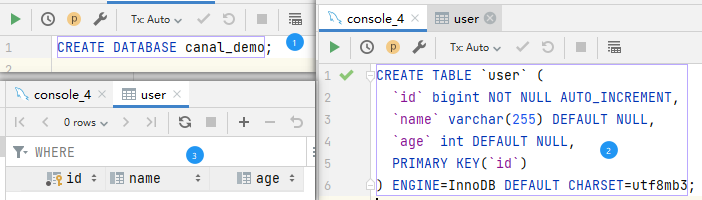
4.1 创建数据库 创建表
1
2
3
4
5
6
7
8
| CREATE DATABASE canal_demo;
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY(`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
|
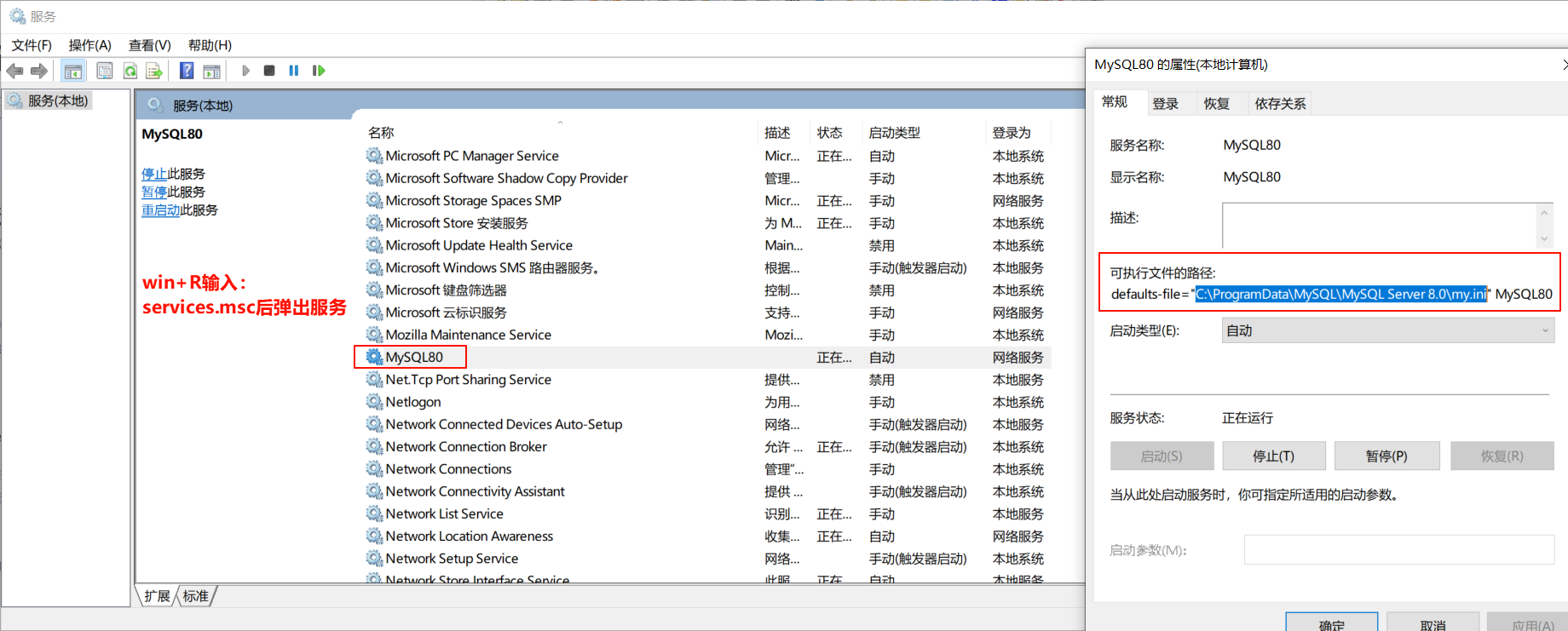
4.2 修改配置文件开启
1
2
3
4
5
6
7
8
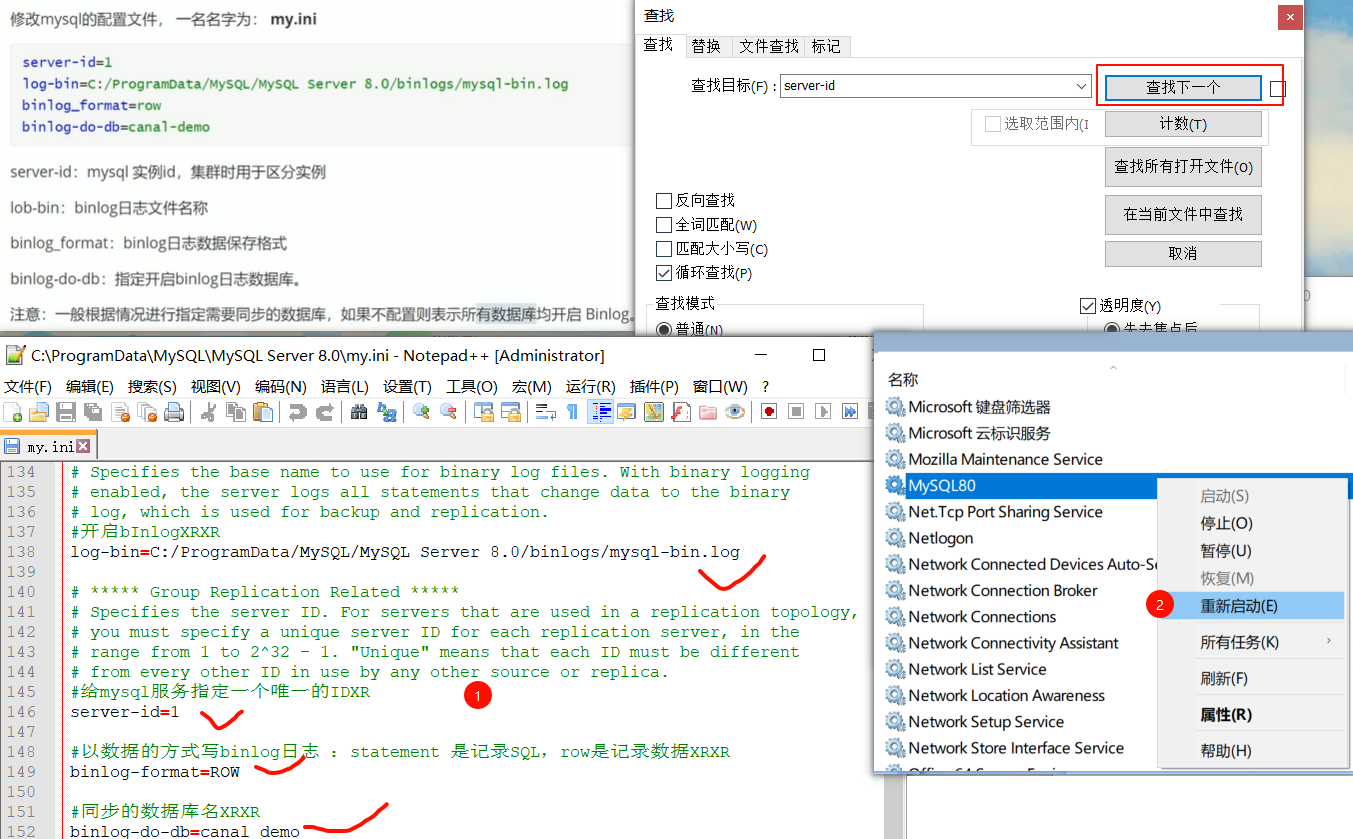
| #给mysql服务指定一个唯一的ID
server-id=1
#开启bInlog
log-bin=C:/ProgramData/MySQL/MySQL Server 8.0/binlogs/mysql-bin.log
#以数据的方式写binlog日志 :statement 是记录SQL,row是记录数据
binlog-format=ROW
#同步的数据库名
binlog-do-db=canal_demo
|
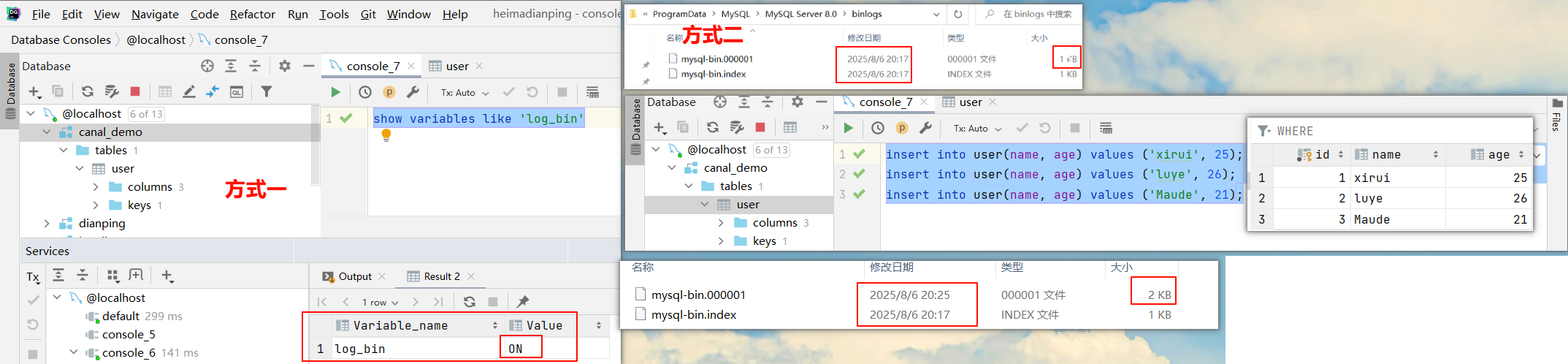
5. Canal安装与配置
5.1 下载解压
- canal.deployer:相当于 canal 的服务端,启动它才可以在客户端接收数据库变更信息。
- canal.adapter:增加客户端数据落地的适配及启动功能(当 deployer 接收到消息后,会根据不同的目标源做适配,比如是 es 目标源适配和 hbase 适配等等)。

5.2 修改canal.properties的配置
- canal.port:默认端口11111
- canal.serverMode:服务模式,tcp表示输入客户端,xxMQ输出到各类消息中间件
- canal.destinations:canal能可以收集多个MySQL数据库数据,每个MySQL数据库都有独立的配置文件控制。具体配置规则:conf/目录下,使用文件夹放置,文件夹名代表一个MySQL实例。canal.destinations用于配置需要监控数据的数据库。如果是多个,使用,隔开

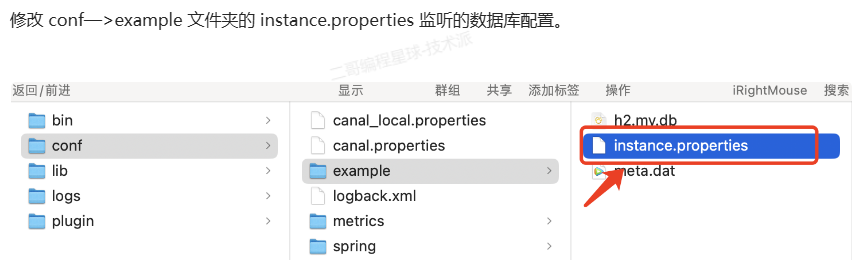
5.3 修改MySQL实例配置文件instance.properties
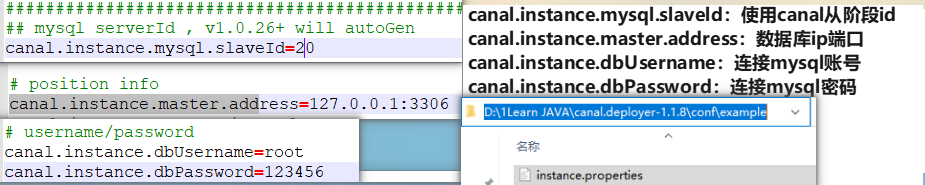
5.4 canal.deployer启动
双击D:\1Learn JAVA\canal.deployer-1.1.8\bin\startup.bat
系统属性里改成JDK17打开startup.bat立马闪退

6. ⭐️虚拟机
6.1 虚拟机中MySQL操作
6.1.1 修改/etc/my.cnf 开启binlog
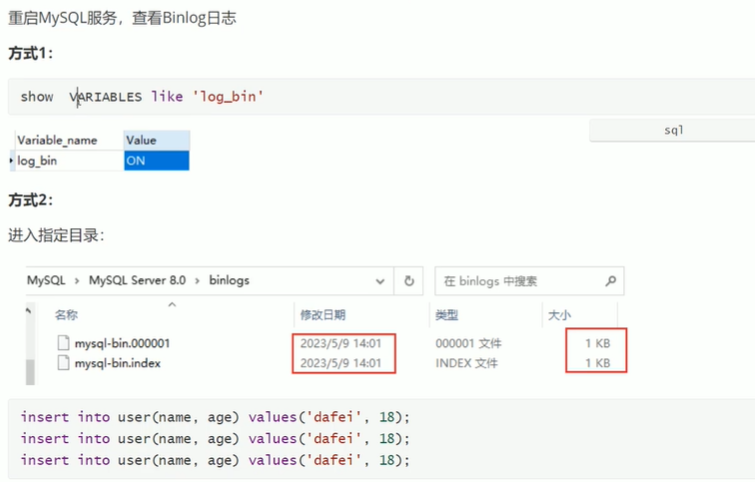
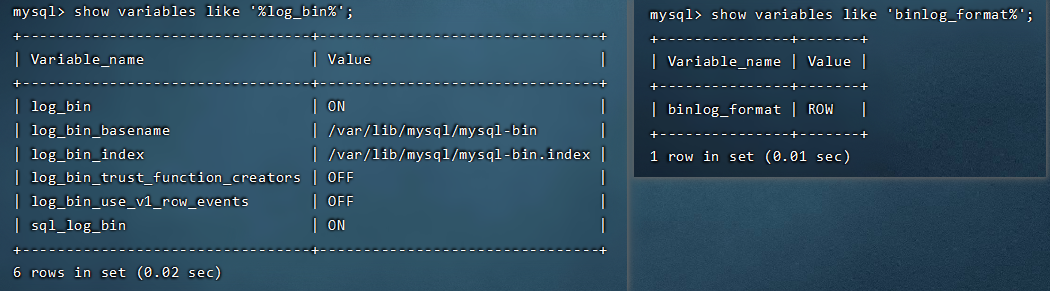
然后再重启 MySQL。
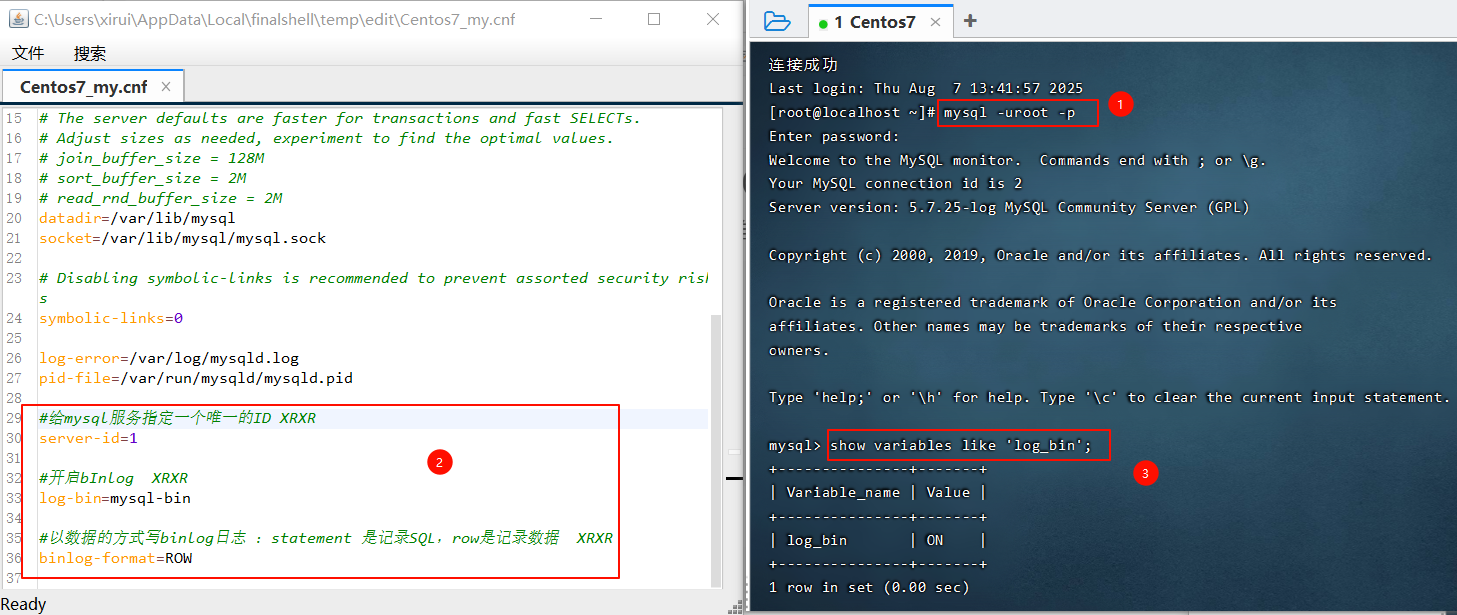
BinLog 开启后,会看到 BinLog 日志。

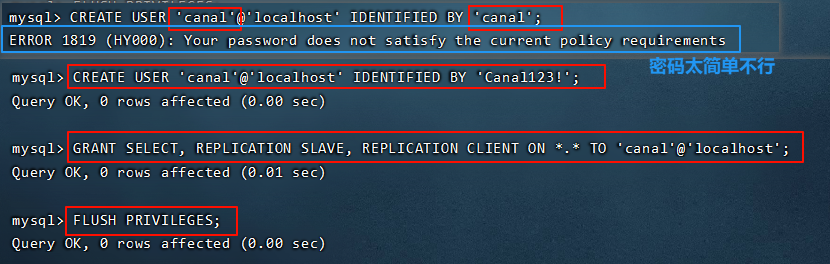
6.1.2 创建MySQL账号 Cannal
账号和密码都是 Cannal,给后面 Canal 使用。
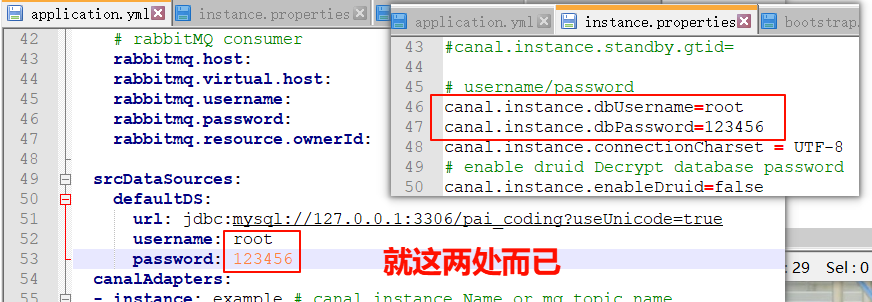
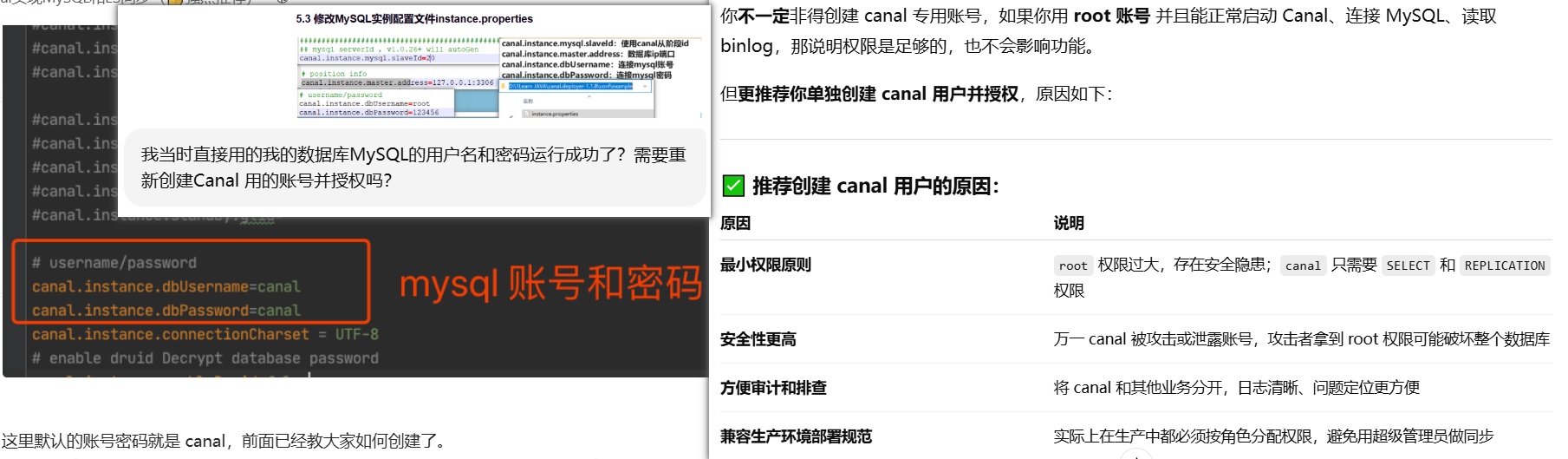
用root 123456也能成功但有弊端。所以换成了canal。
不用改cannal了,改了后面双击启动D:\1LearnJAVA\canal.adapter-1.1.8\bin\startup.bat有问题
用root,123456.一点儿问题没有
1
2
3
| CREATE USER 'canal'@'localhost' IDENTIFIED BY 'Canal123!';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'localhost';
FLUSH PRIVILEGES;
|
6.2 Canal安装解压

6.2.1 修改canal.properties配置端口
- canal.port:默认端口11111
- canal.serverMode:服务模式,tcp表示输入客户端,xxMQ输出到各类消息中间件
- canal.destinations:canal能可以收集多个MySQL数据库数据,每个MySQL数据库都有独立的配置文件控制。具体配置规则:conf/目录下,使用文件夹放置,文件夹名代表一个MySQL实例。canal.destinations用于配置需要监控数据的数据库。如果是多个,使用,隔开

6.2.2 canal.deployer配置
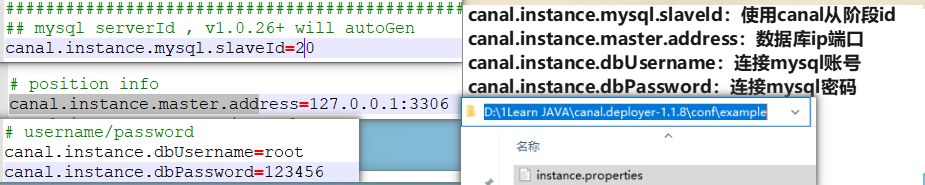
instance.properties配置账号密码
6.2.3 canal.deployer启动
双击D:\1Learn JAVA\canal.deployer-1.1.8\bin\startup.bat
6.2.4 canal.adapter 配置
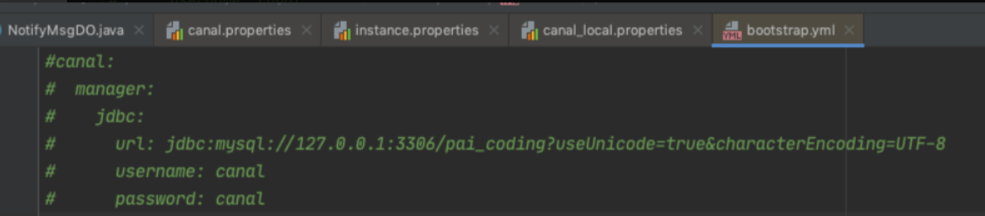
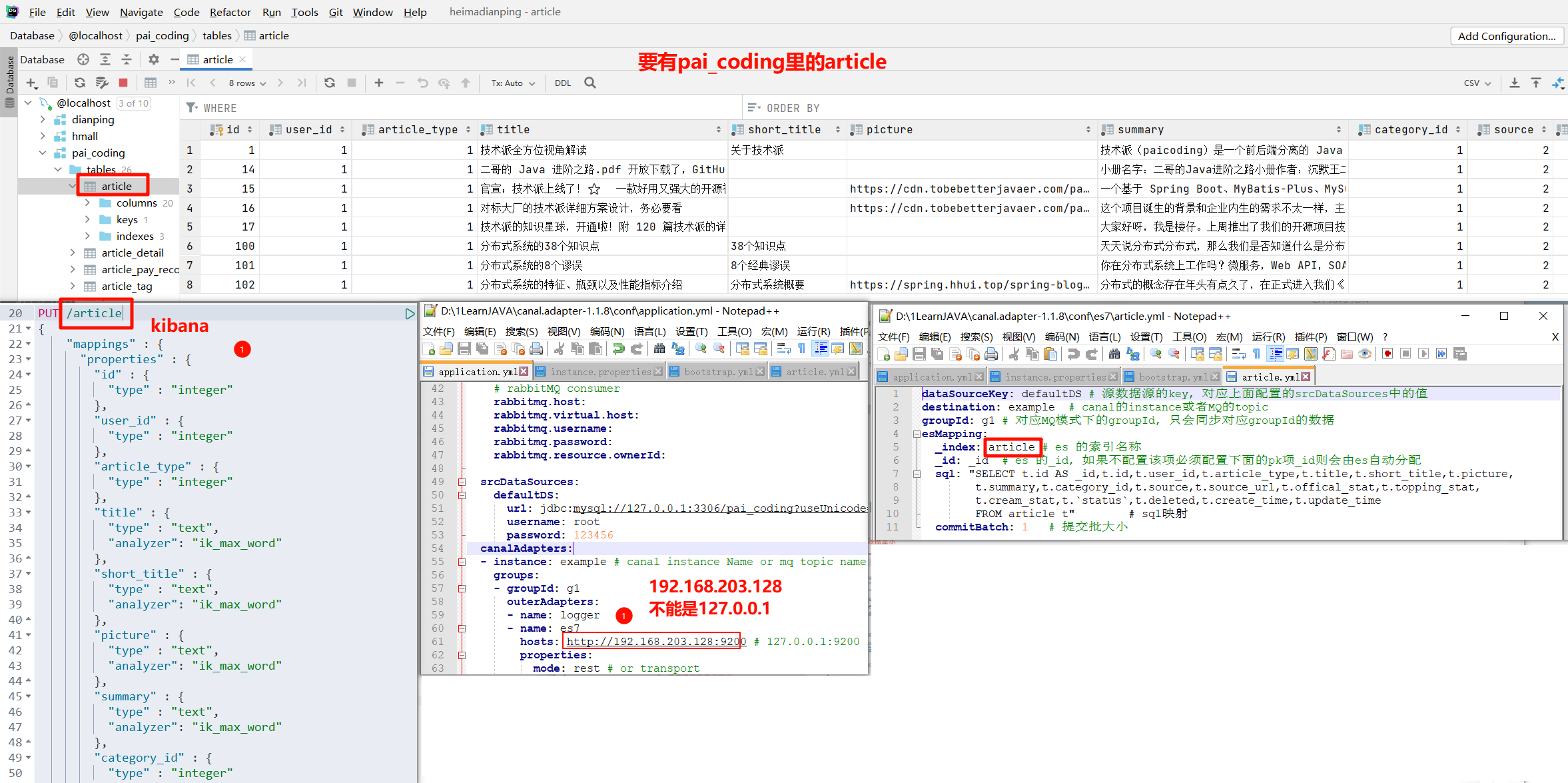
Step1: 先把 adapter 下面的 bootstrap.yml,全部注释掉,否则会提示你 XX 表不存在。

Step2: 再修改 adapter 的 application.yml 配置文件。
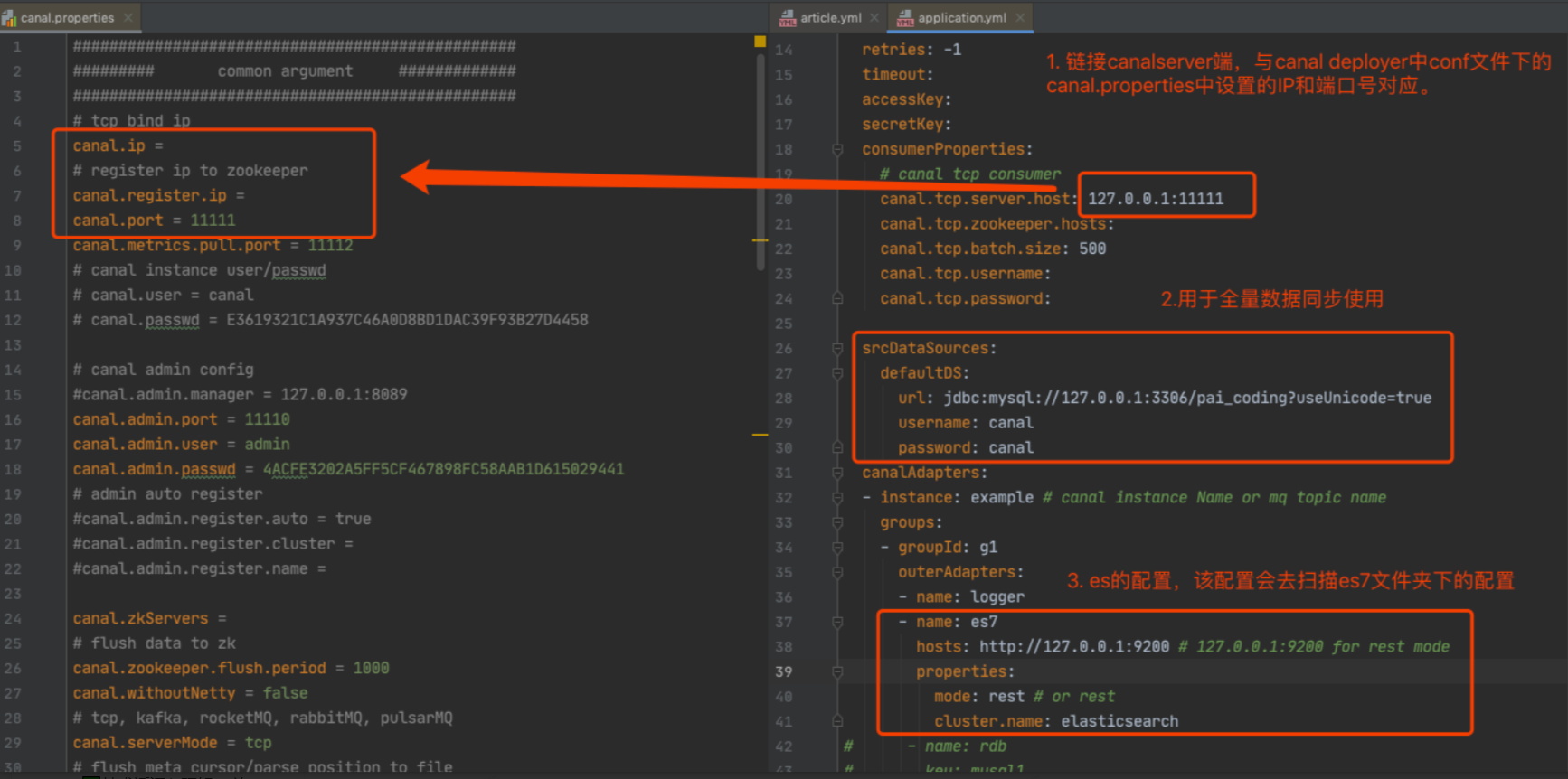
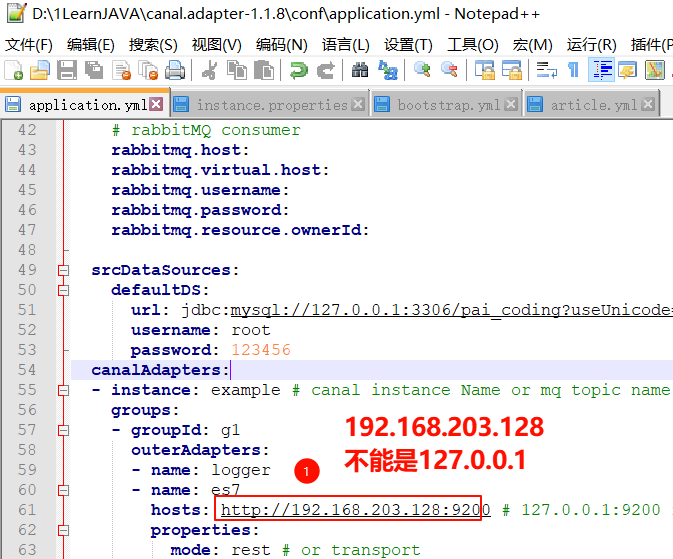
这里的坑,一般就是 mysql 的账号密码不对,或者给的 es 链接,没有”http://“前缀,这些都是我过踩的坑.
Step3: 修改我们在 application.yml 中配置的目标数据源 es7 文件夹内容。
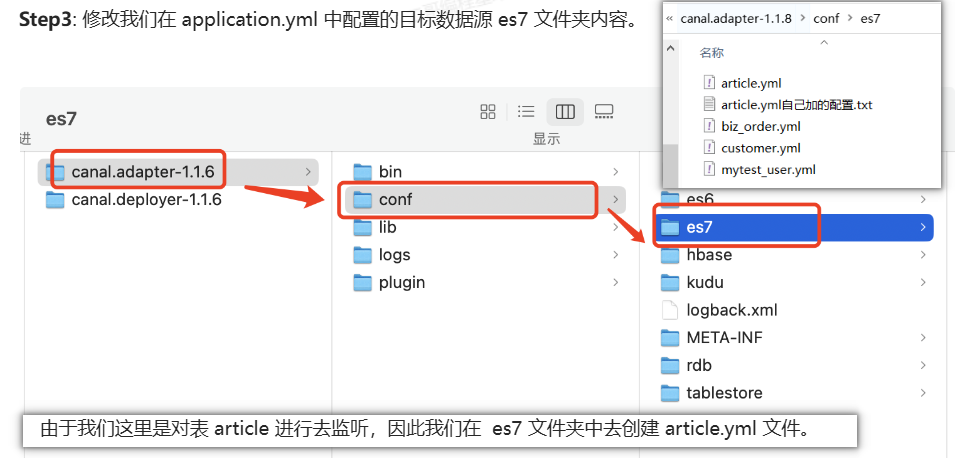
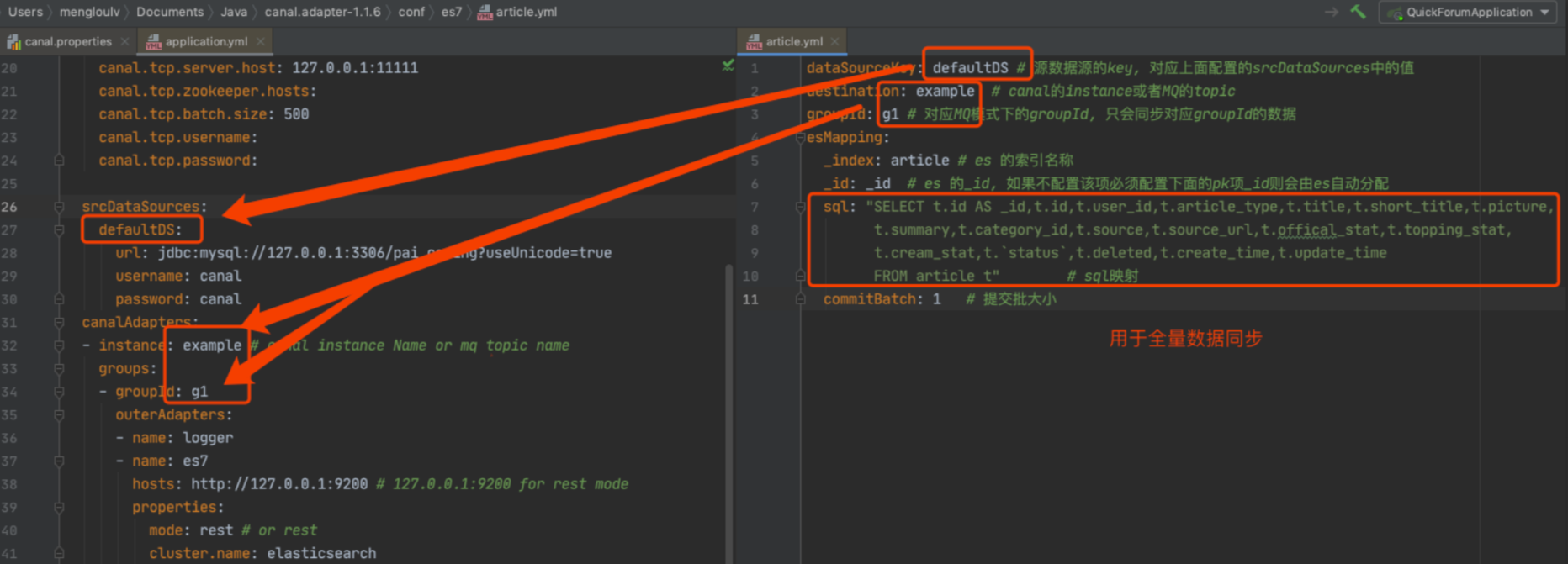
由于我们需要把技术派项目中的文章查询功能,改造成 ES 的查询方式,所以我们就把技术派的文章表 article,同步到 ES 中。
yml文件配置如下:
1
2
3
4
5
6
7
8
| dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: article
_id: _id
sql: "SELECT t.id AS _id,t.id, t.user_id, t.article_type, t.title, t.short_title, t.picture, t.summary, t.category_id, t.source, t.source_url, t.offical_stat, t.topping_stat, t.cream_stat, t.`status`, t.deleted, t.create_time, t.update_time FROM article t"
commitBatch: 1
|
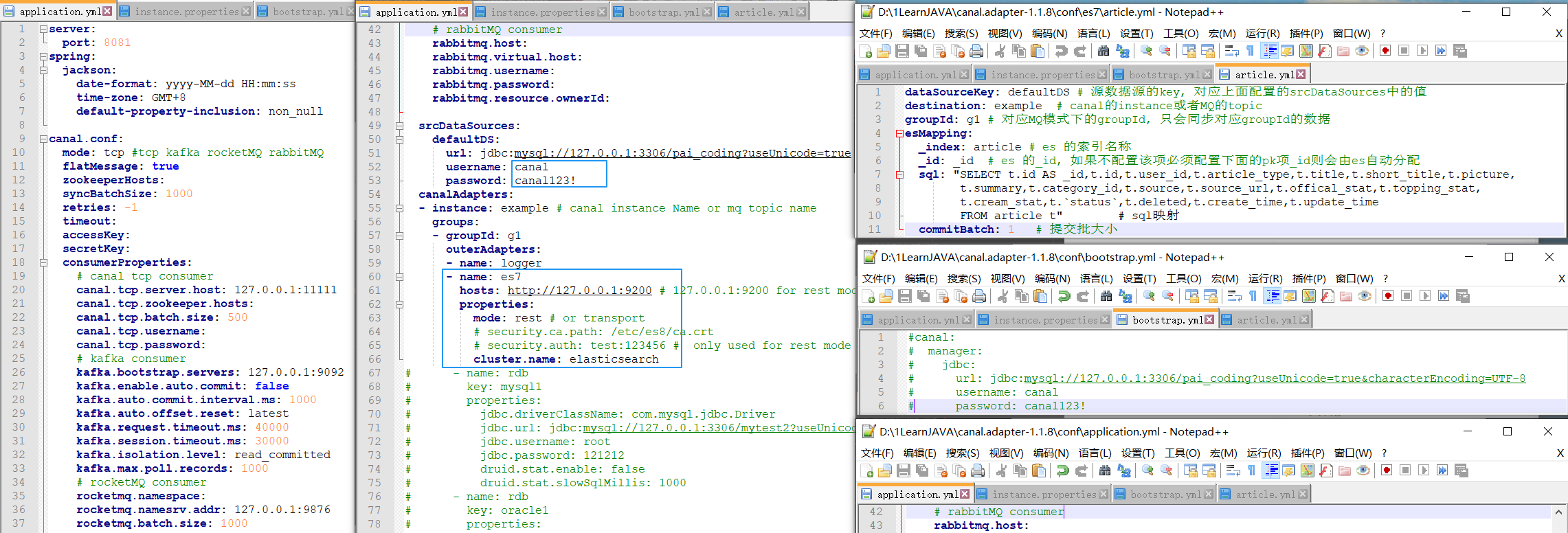
Step4: 在 Kibana 中创建 ES 的 article 索引。
代码如下:
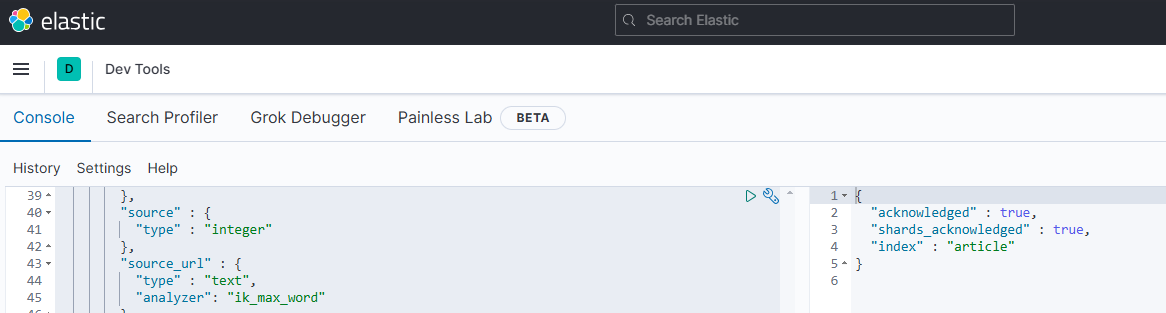
不要article_v2就是article。与pai_coding里的article表一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| PUT /article
{
"mappings" : {
"properties" : {
"id" : {
"type" : "integer"
},
"user_id" : {
"type" : "integer"
},
"article_type" : {
"type" : "integer"
},
"title" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"short_title" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"picture" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"summary" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"category_id" : {
"type" : "integer"
},
"source" : {
"type" : "integer"
},
"source_url" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"offical_stat" : {
"type" : "integer"
},
"topping_stat" : {
"type" : "integer"
},
"cream_stat" : {
"type" : "integer"
},
"status" : {
"type" : "integer"
},
"deleted" : {
"type" : "integer"
},
"create_time" : {
"type" : "date"
},
"update_time" : {
"type" : "date"
}
}
}
}
|
6.2.5 canal.adapter启动
双击D:\1Learn JAVA\canal.adapter-1.1.8\bin\startup.bat
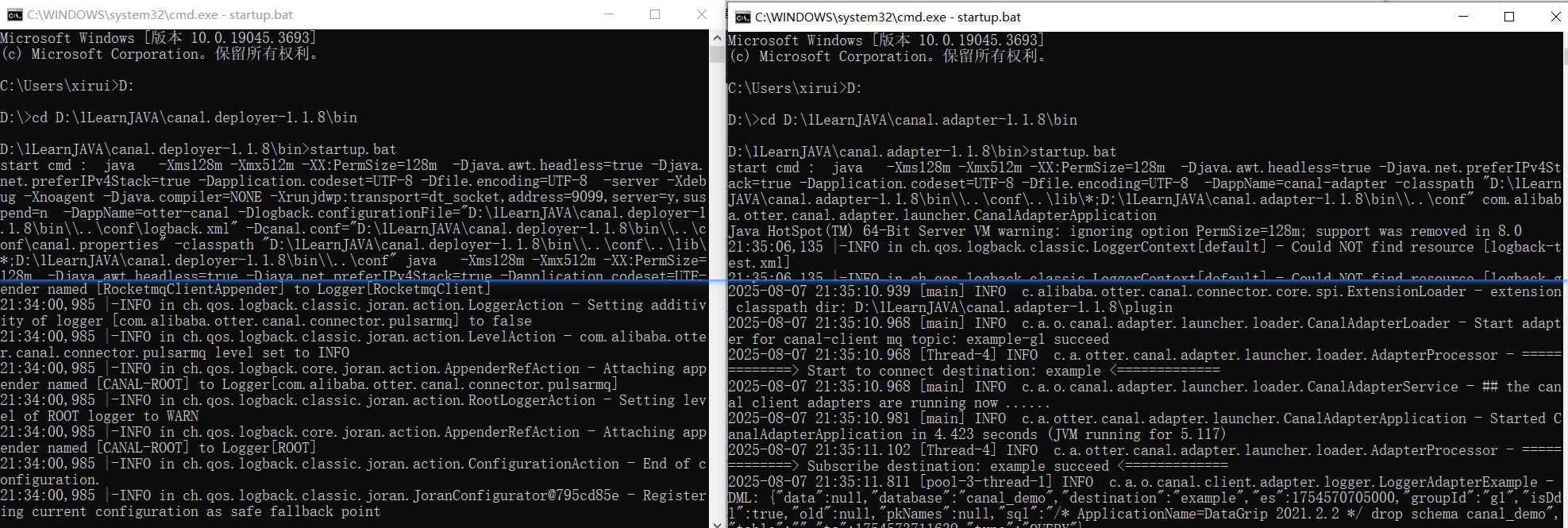
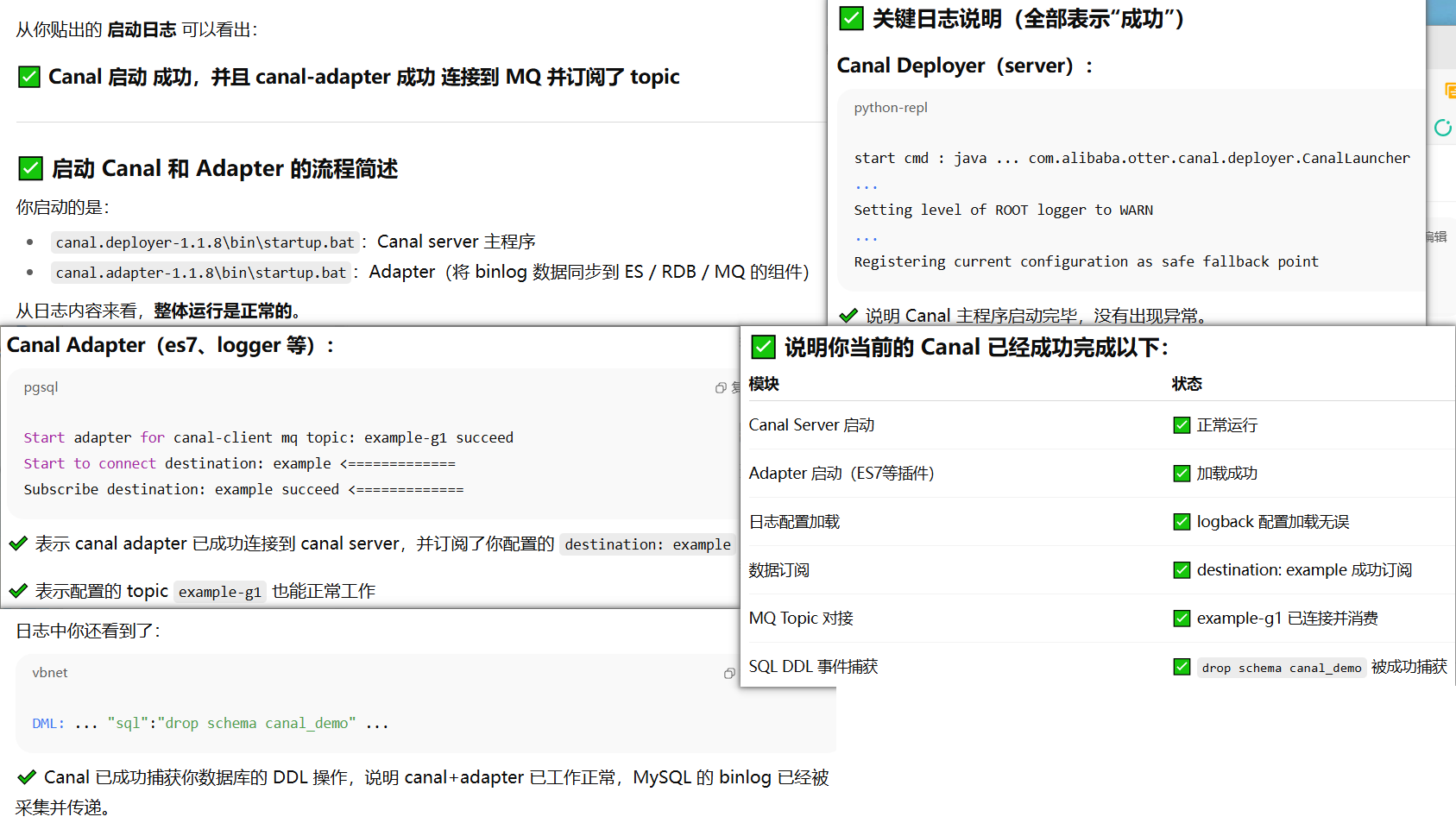
6.3 数据同步实战
6.3.1 全量同步
win+R cmd输入:
1
| curl http://127.0.0.1:8081/etl/es7/article.yml -X POST
|

上面就是执行同步成功后,提示已经导入8 条(我的数据库article表里就8条)。
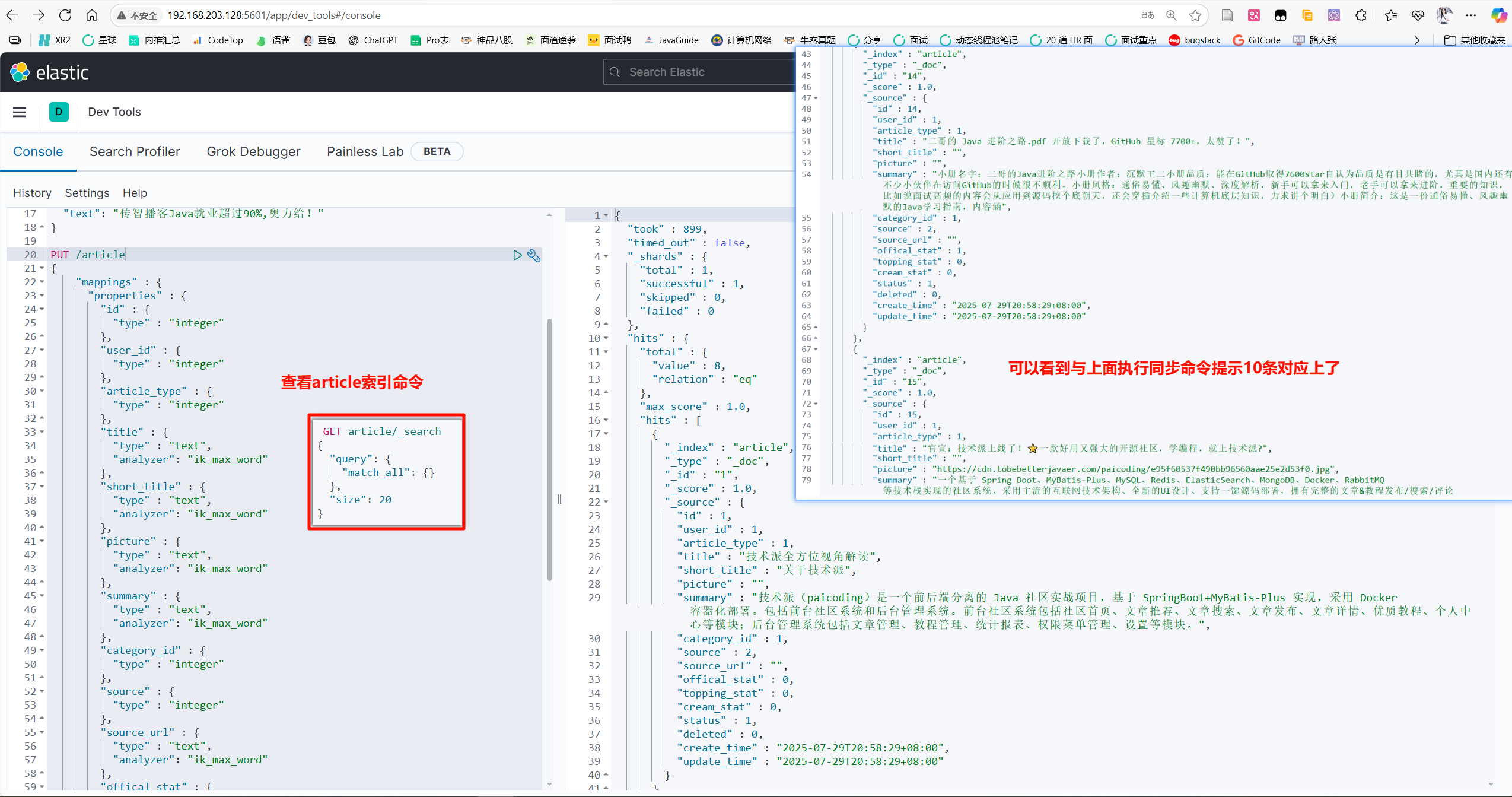
然后运行kibana下列代码,查看article索引命令
1
2
3
4
5
6
7
| GET article/_search
{
"query": {
"match_all": {}
},
"size": 20
}
|
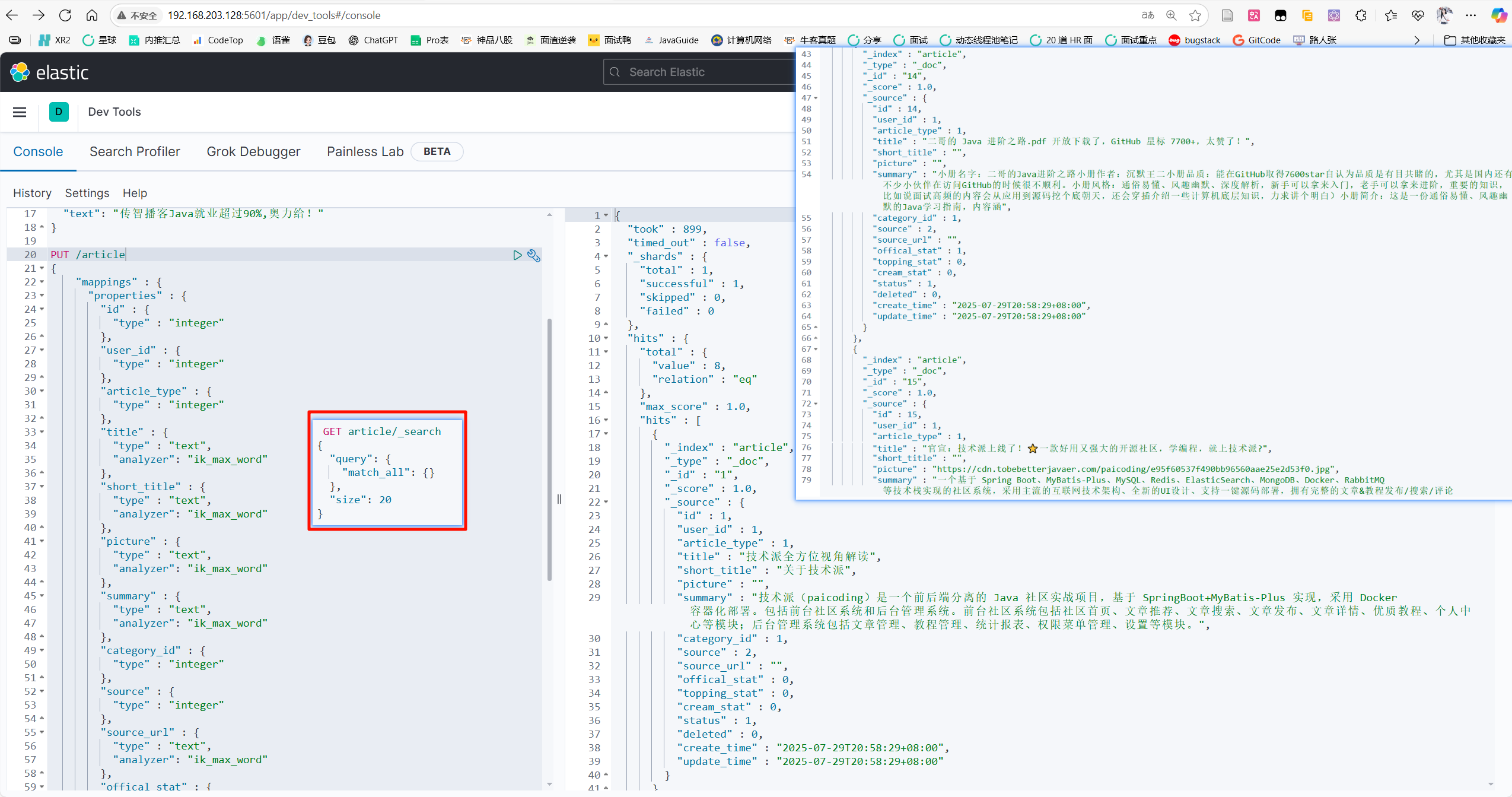
可以看到与上面执行同步命令提示10条对应上了
6.3.2 增量同步
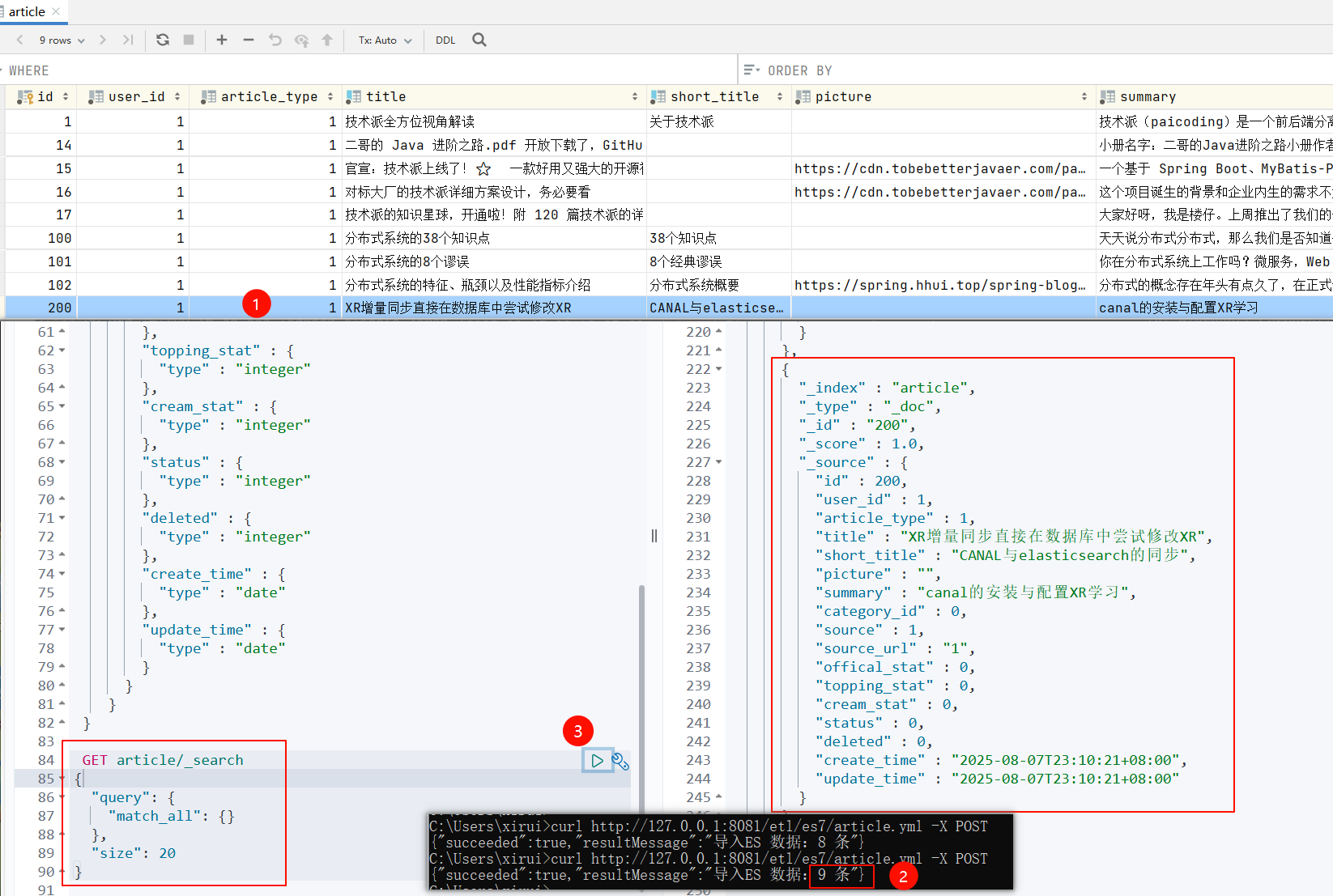
即增量同步成功
增量数据就是当我在 MySQL 中 update、delete 和 insert 时,那么 ES 中数据也会对应发生变化,我下面演示下修改:
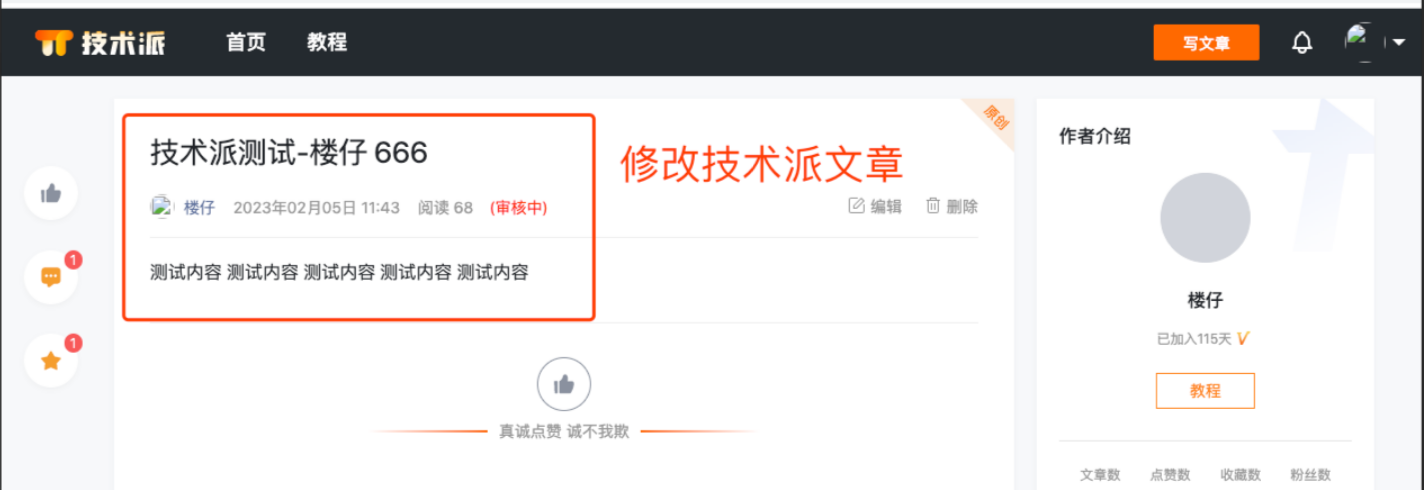
日志打印如下
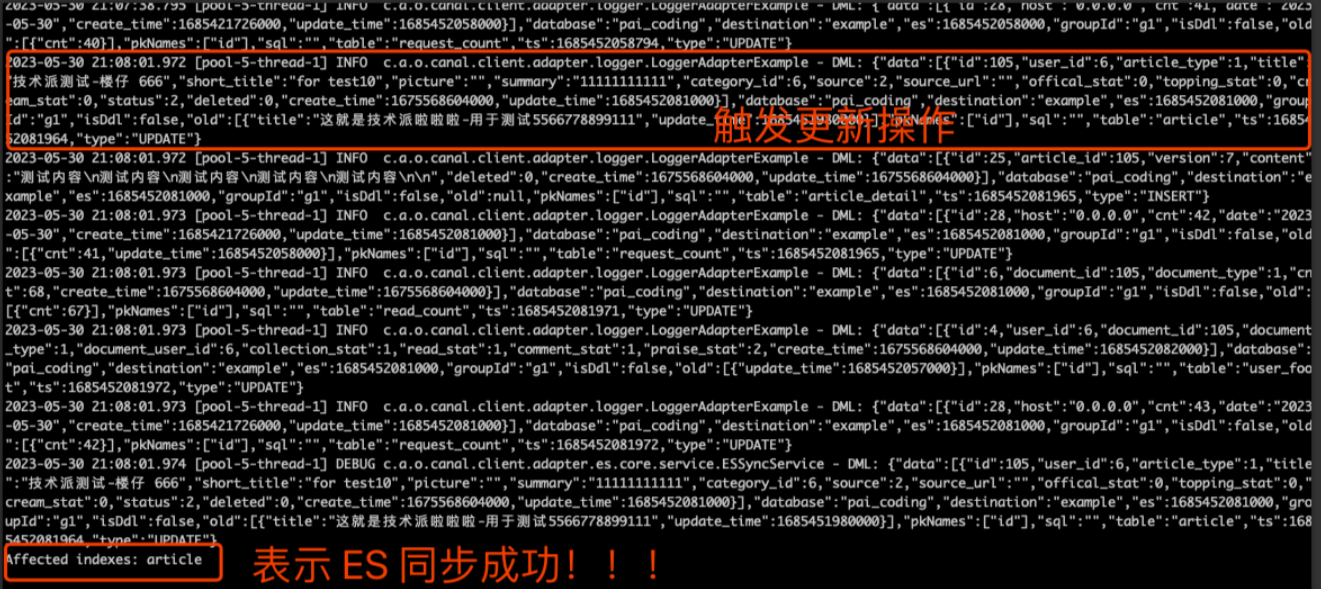
ES查询结果如下:
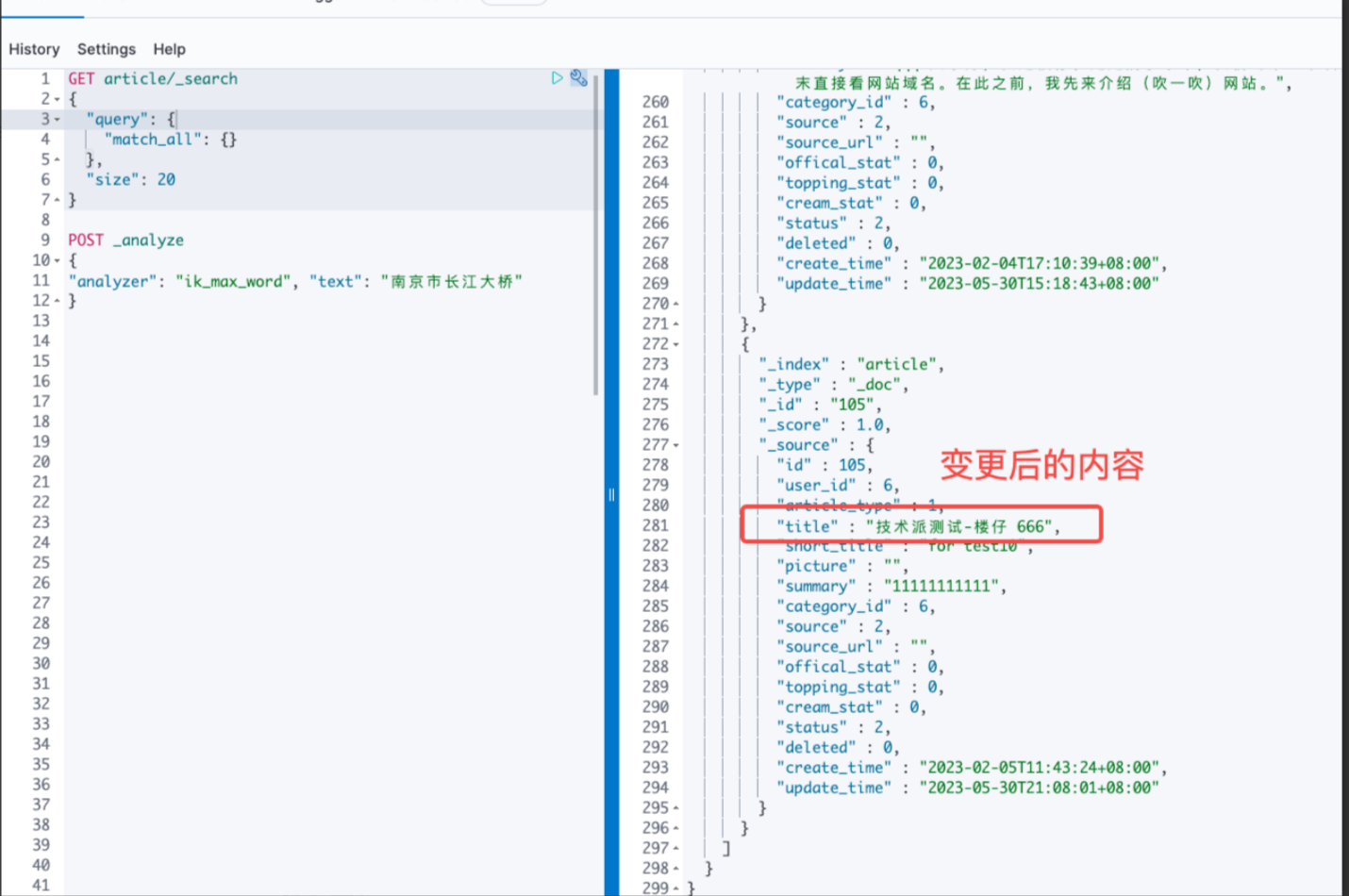
上面结果中说明 ES 已经更改成功。
6.3.3 总结
回顾一下整体执行流程:
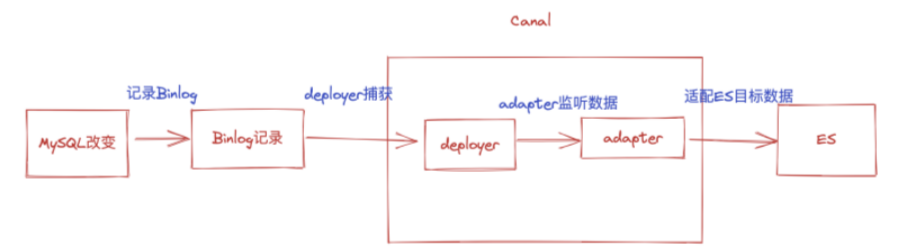
写到这里,就结束了,教你如何将 MySQL 同步到 ES,不仅是增量同步,还包括全量同步,如果你的项目也需要用到该场景,基本可以直接照搬。
7. Canal编程
7.1 Hello
1>创建IDEA项目:canal
2>导入canal相关依赖
1
2
3
4
5
| <dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
|
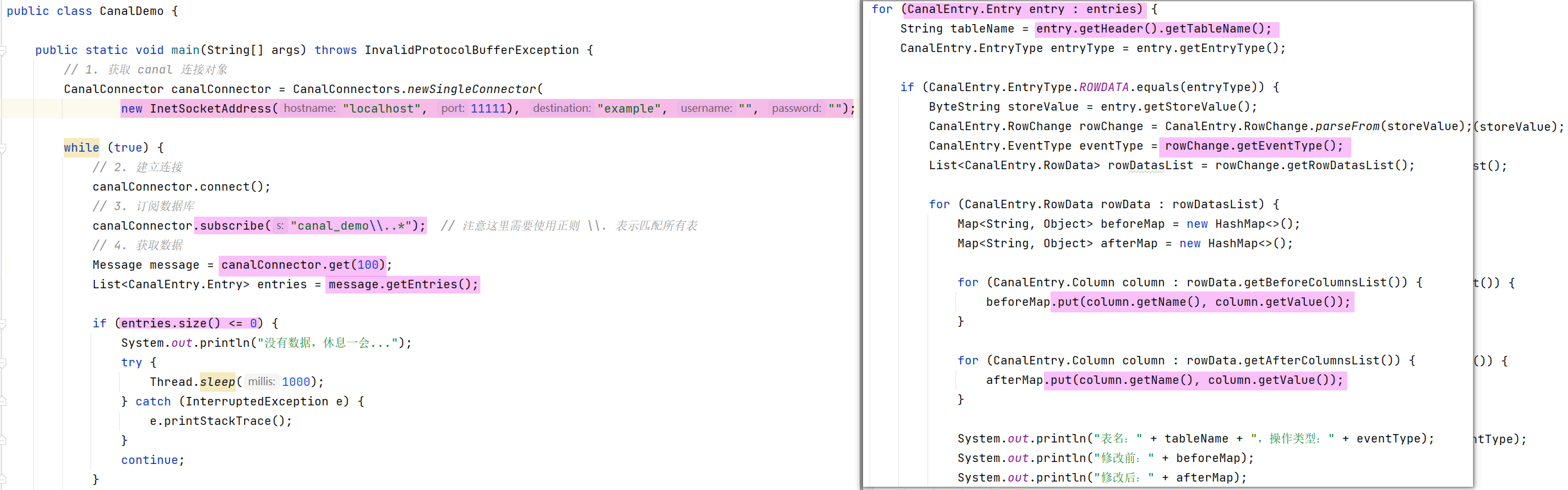
3>编写测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| package com.xirui.canalhello.canal_demo;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class CanalDemo {
public static void main(String[] args) throws InvalidProtocolBufferException {
CanalConnector canalConnector = CanalConnectors.newSingleConnector(
new InetSocketAddress("localhost", 11111), "example", "", "");
while (true) {
canalConnector.connect();
canalConnector.subscribe("canal_demo\\..*");
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println("没有数据,休息一会...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
for (CanalEntry.Entry entry : entries) {
String tableName = entry.getHeader().getTableName();
CanalEntry.EntryType entryType = entry.getEntryType();
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
ByteString storeValue = entry.getStoreValue();
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
CanalEntry.EventType eventType = rowChange.getEventType();
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDatasList) {
Map<String, Object> beforeMap = new HashMap<>();
Map<String, Object> afterMap = new HashMap<>();
for (CanalEntry.Column column : rowData.getBeforeColumnsList()) {
beforeMap.put(column.getName(), column.getValue());
}
for (CanalEntry.Column column : rowData.getAfterColumnsList()) {
afterMap.put(column.getName(), column.getValue());
}
System.out.println("表名:" + tableName + ",操作类型:" + eventType);
System.out.println("修改前:" + beforeMap);
System.out.println("修改后:" + afterMap);
}
}
}
}
}
}
|
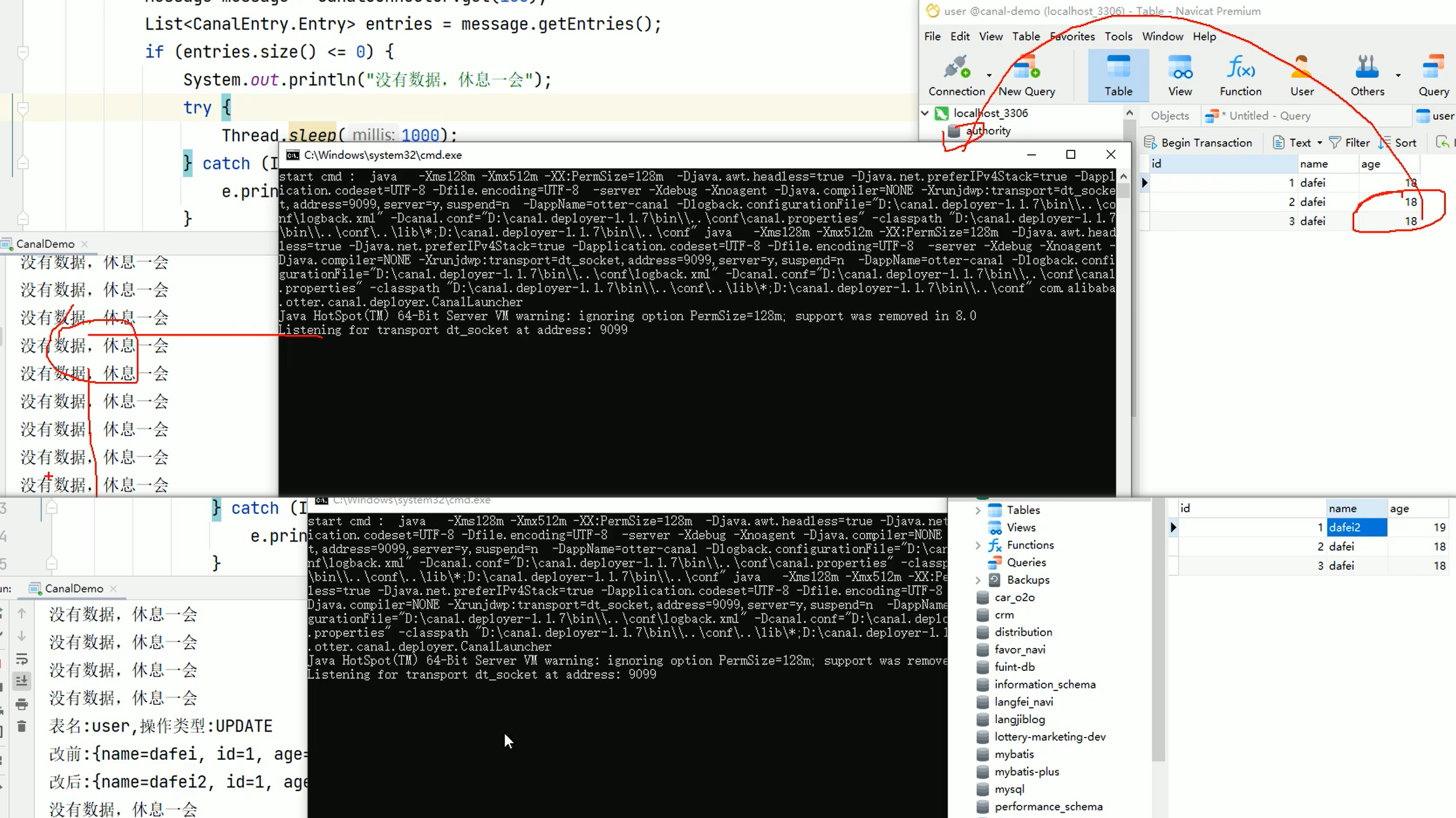
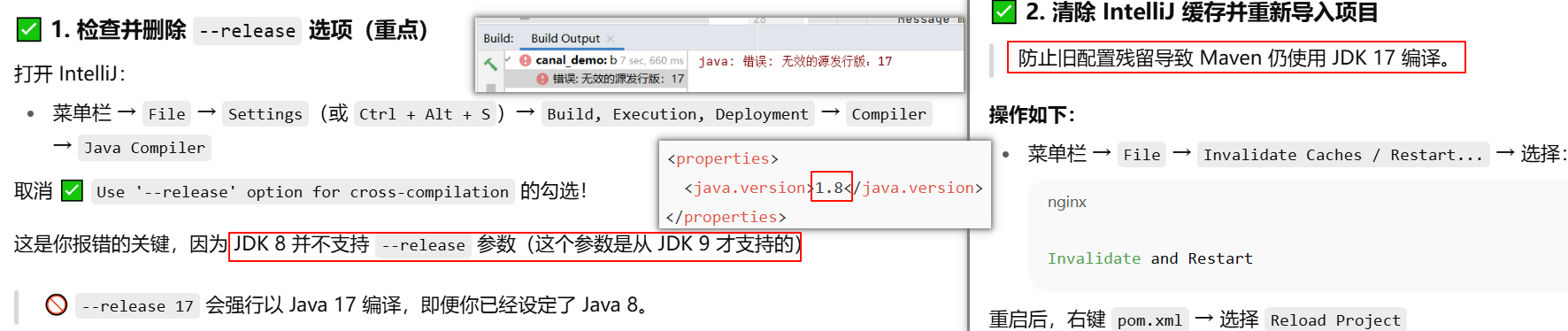
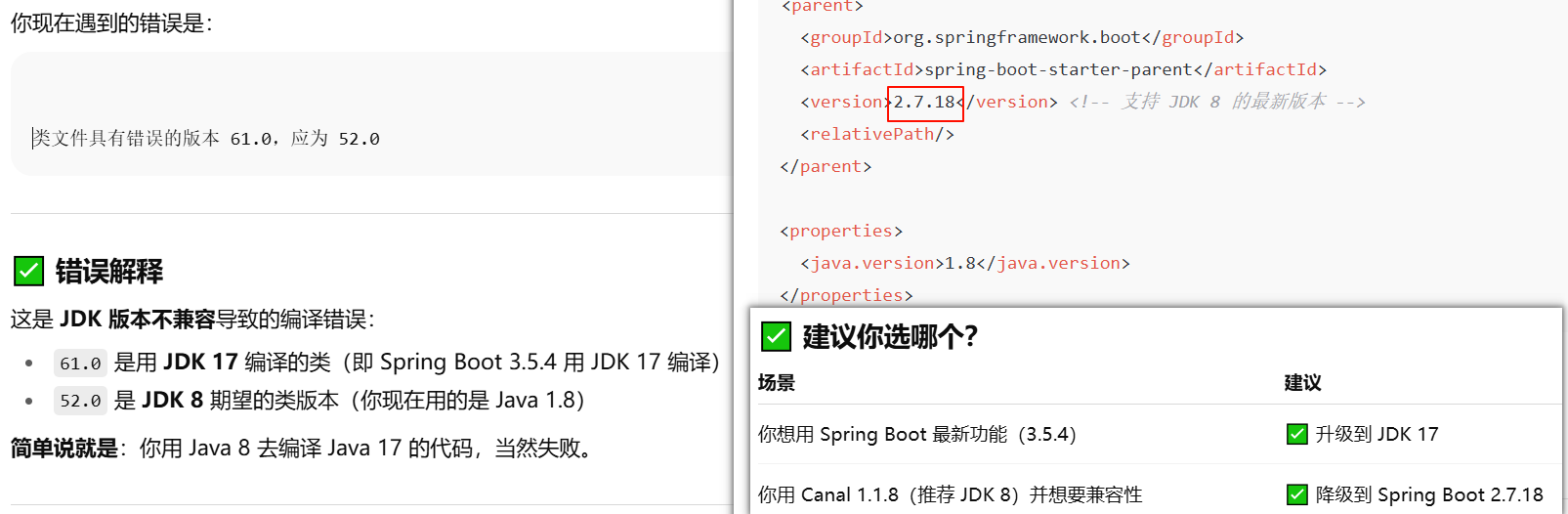
我的程序报错 1️⃣要用JDK8,2️⃣使用的SpringBoot版本要和JDK8能用 上
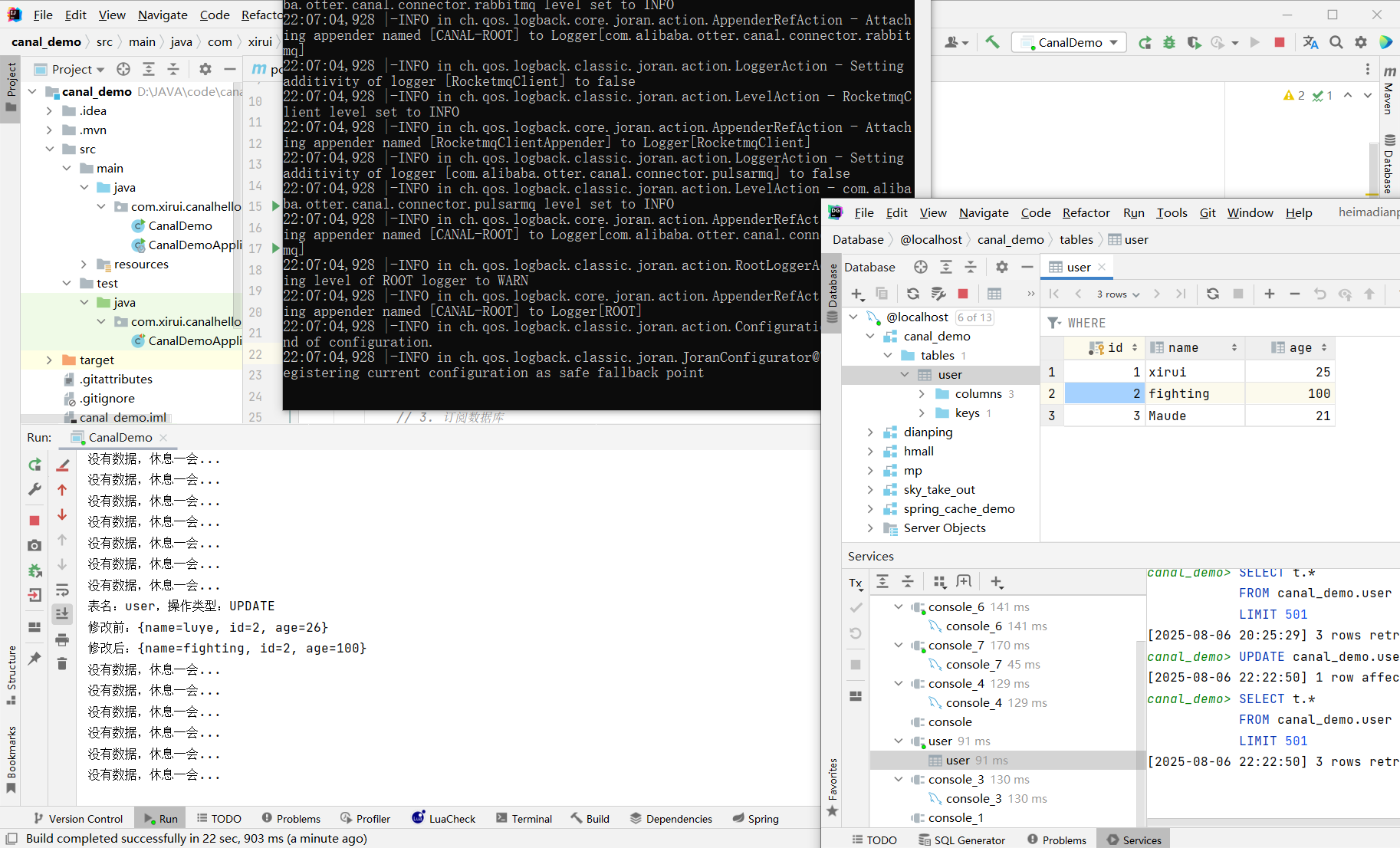
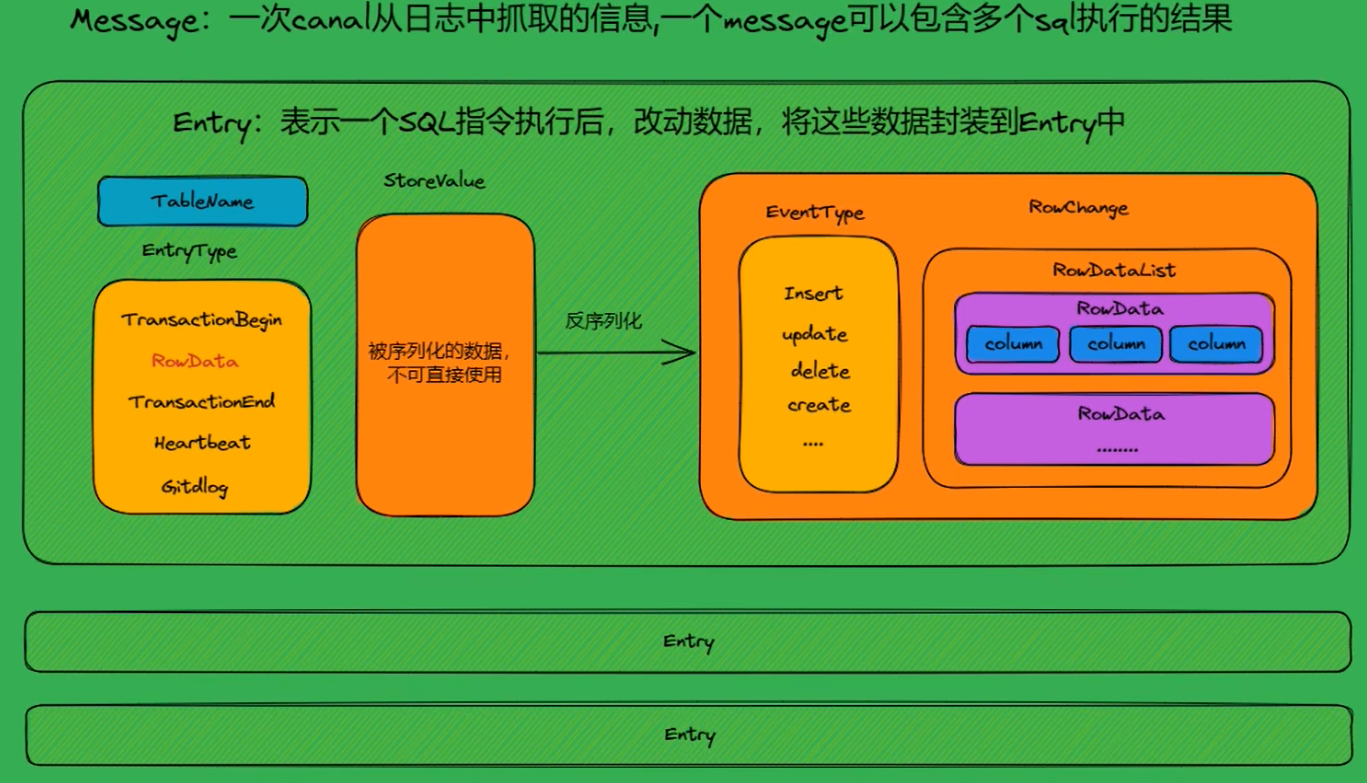
本程序:
- 一次性拿100个SQL语句所变动的数据放在message里。
- 一条SQL对应一个Entry。整个message可以拿一堆SQL,所以有一堆entry
- entry.size()<=0,没有变动,休息一秒钟再循环一次
- 拿到entry对象遍历。
7.2 同类型技术

7.3 常见面试题

