消息队列Kafka-2
8. kafka的java客户端-黑马2019
8.1 依赖
Kafka自身提供的Java客户端来演示消息的收发,与Kafka的Java客户端相关的Maven依赖如下:
1 | |
8.2 生产者的实现
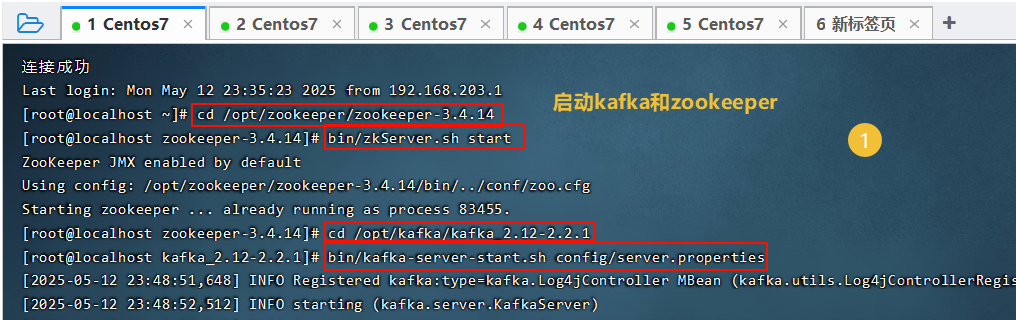
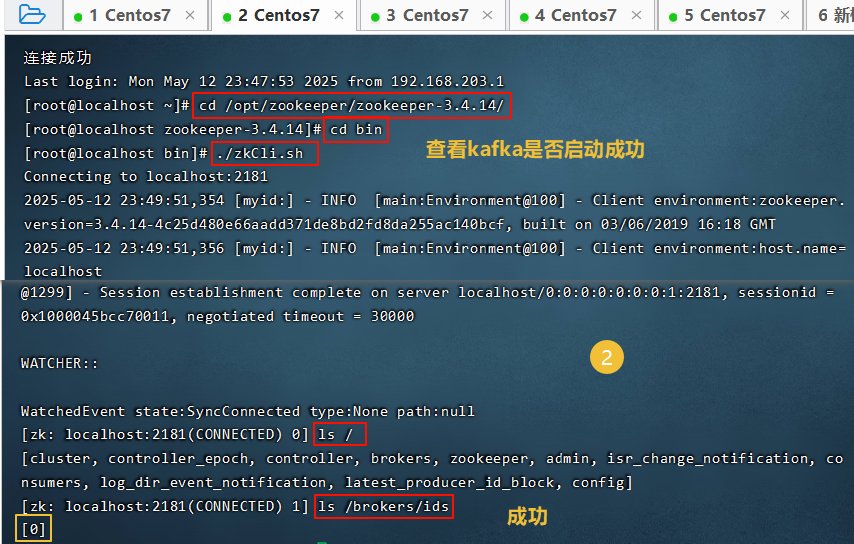
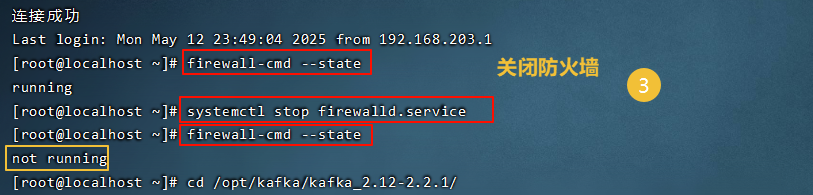
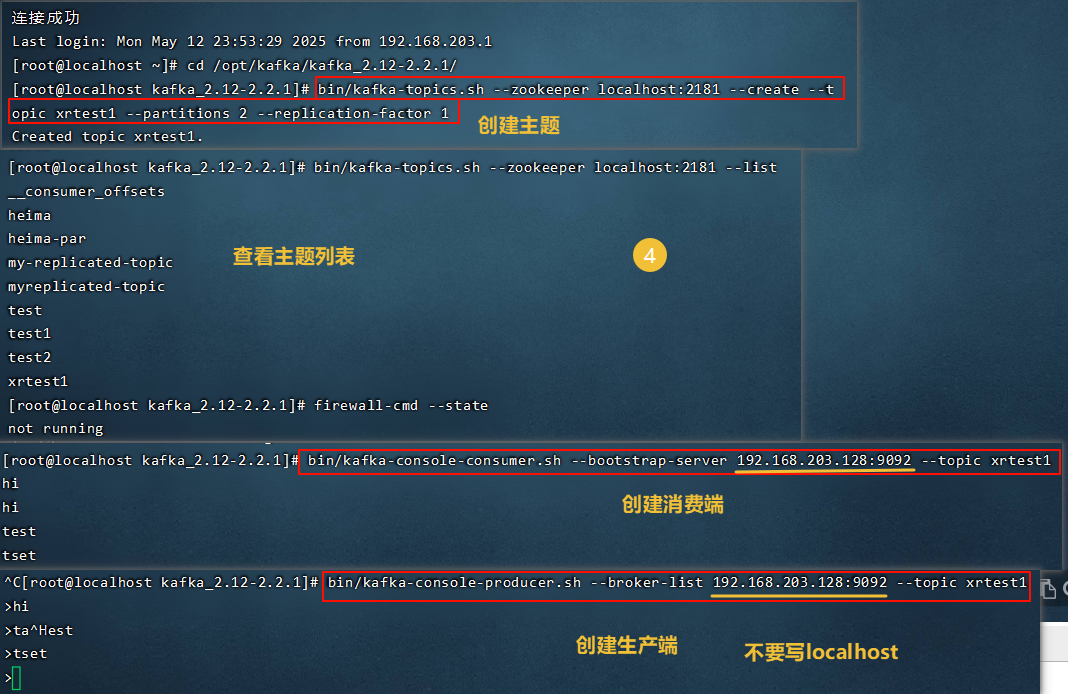
运行java客户端
1 | |


可以修改,防止写错

8.3 消费者的实现
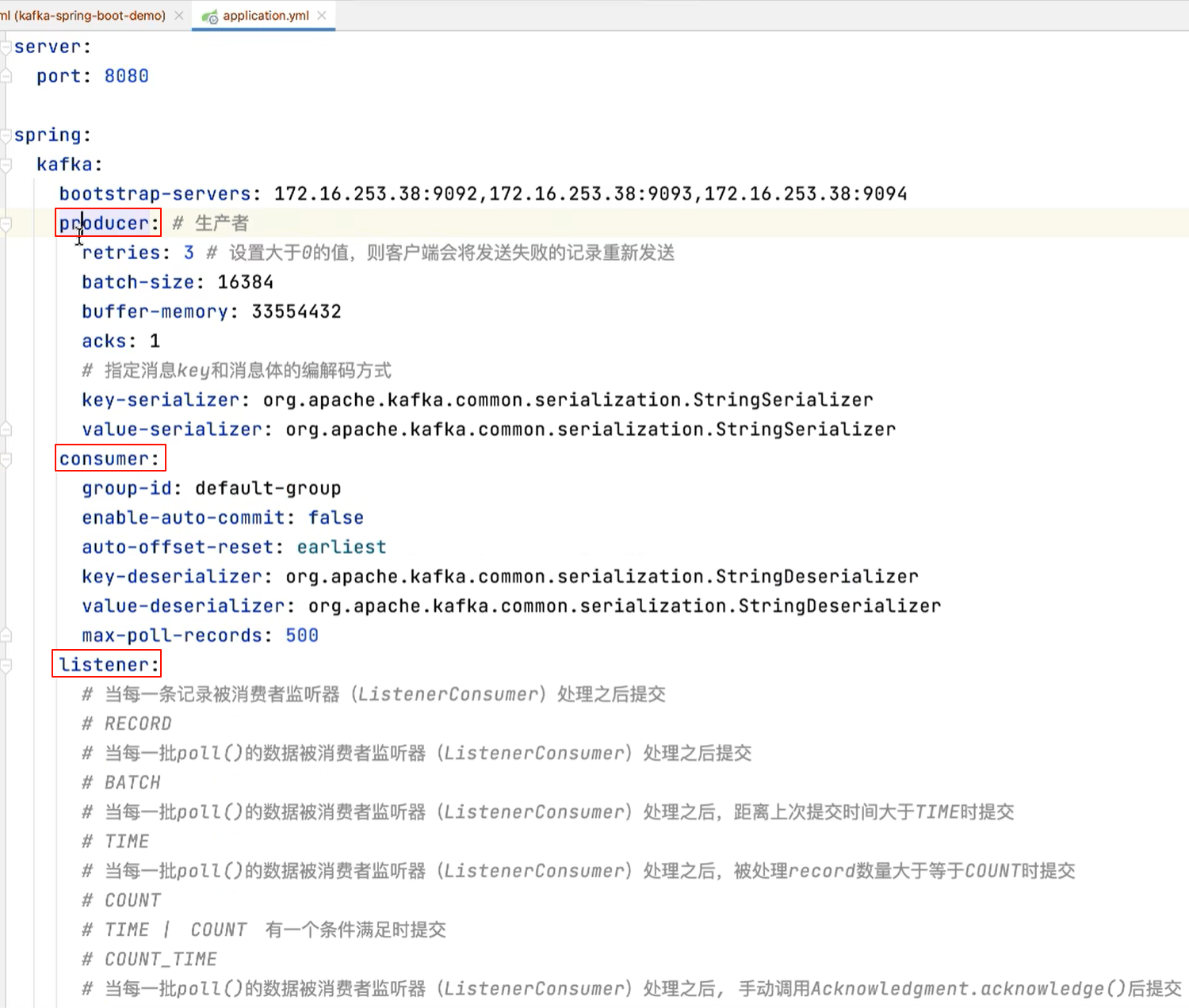
1 | |
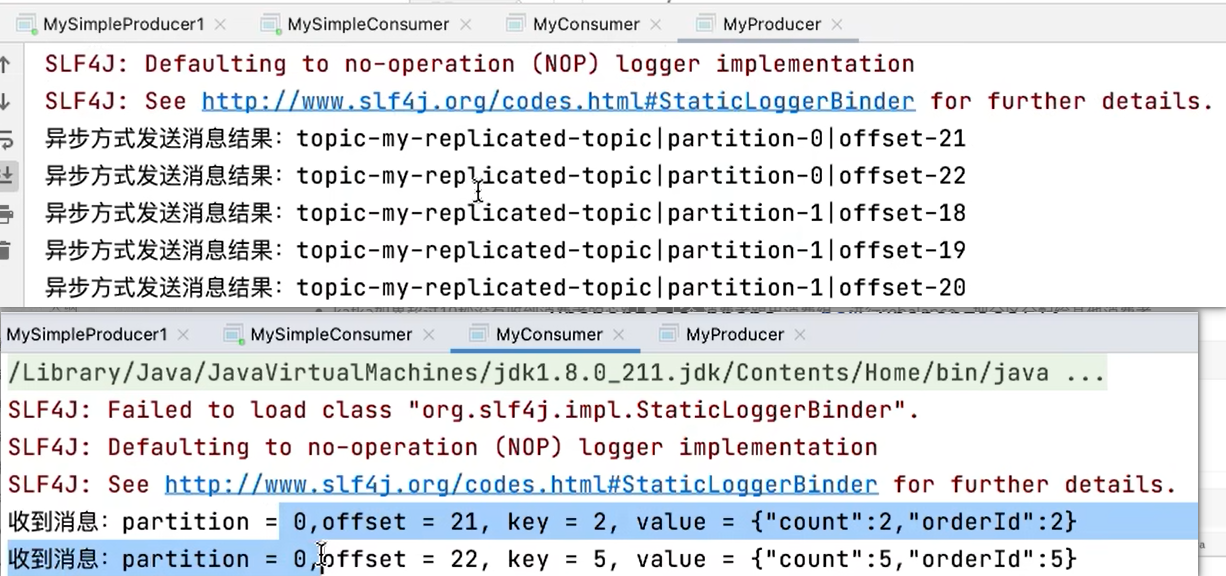
8.4 效果展示
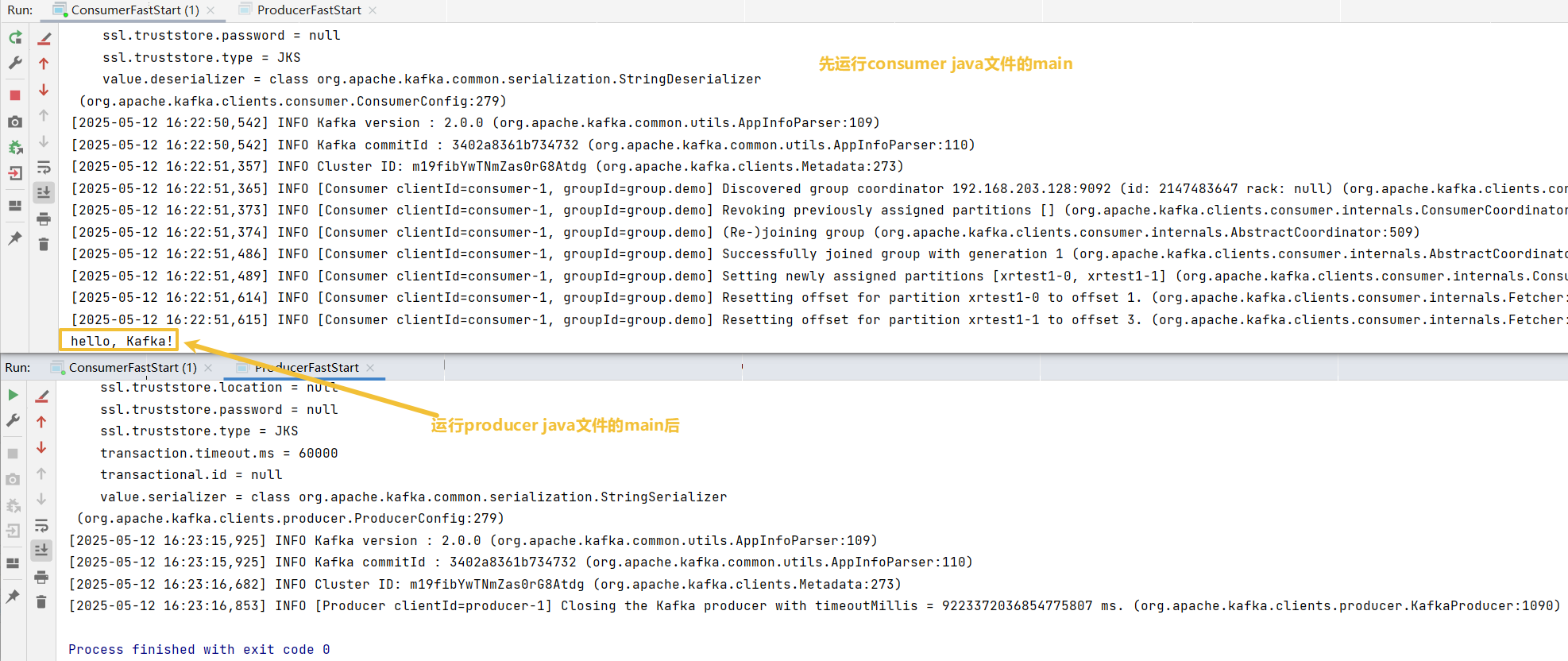
可以修改,防止写错

9. kafka的java客户端-千峰教育
9.1 生产者实现
9.1.1 生产者的基本实现
- 引入依赖

- 具体实现



发送消息到指定分区上
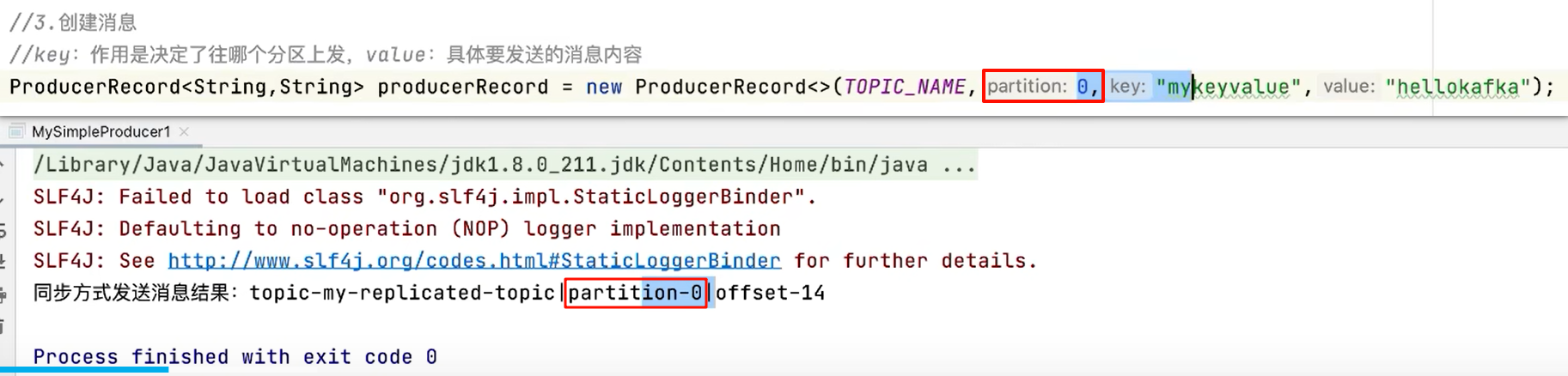


未指定分区,则会通过业务key的hash运算,算出消息往哪个分区上发

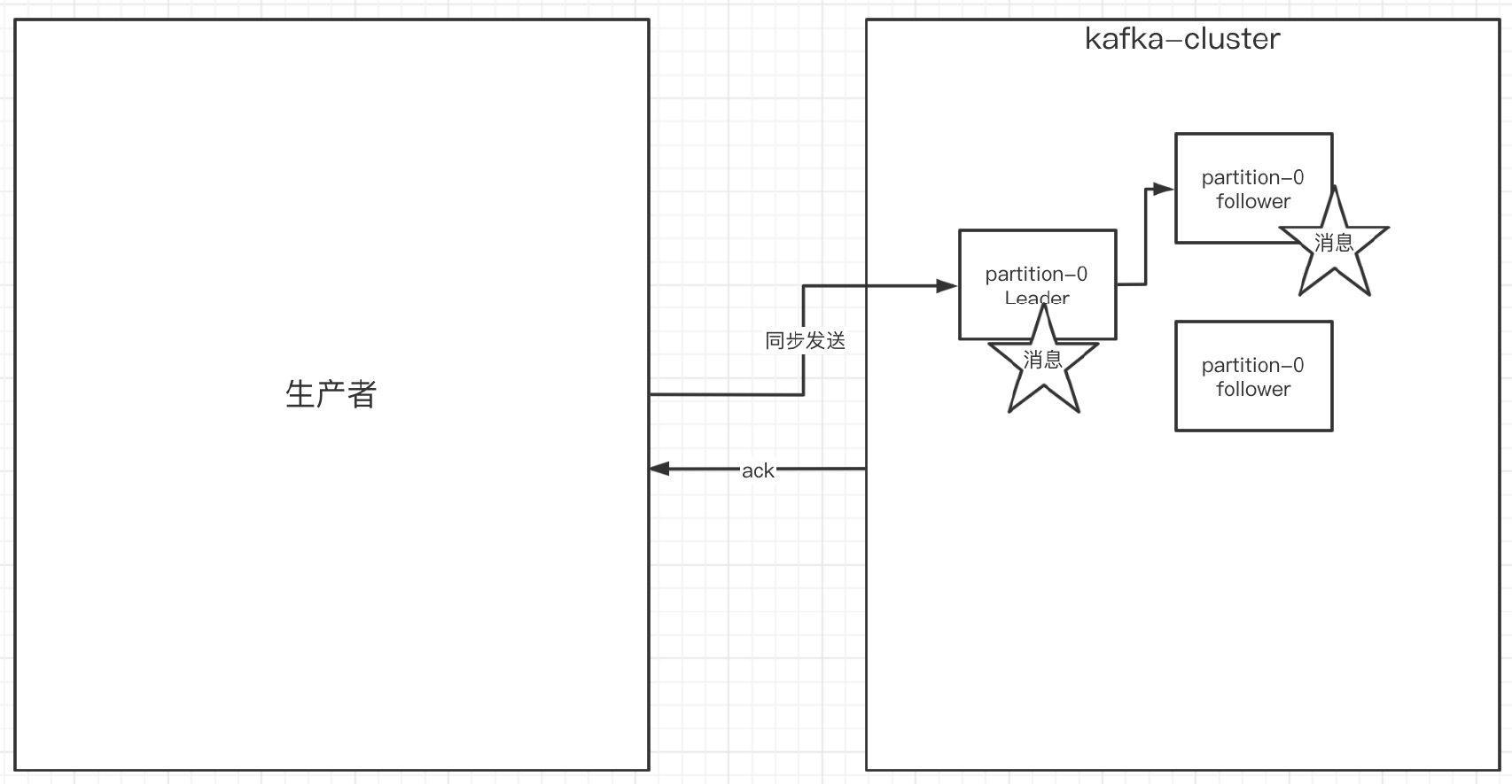
9.1.2 生产者的同步发送消息
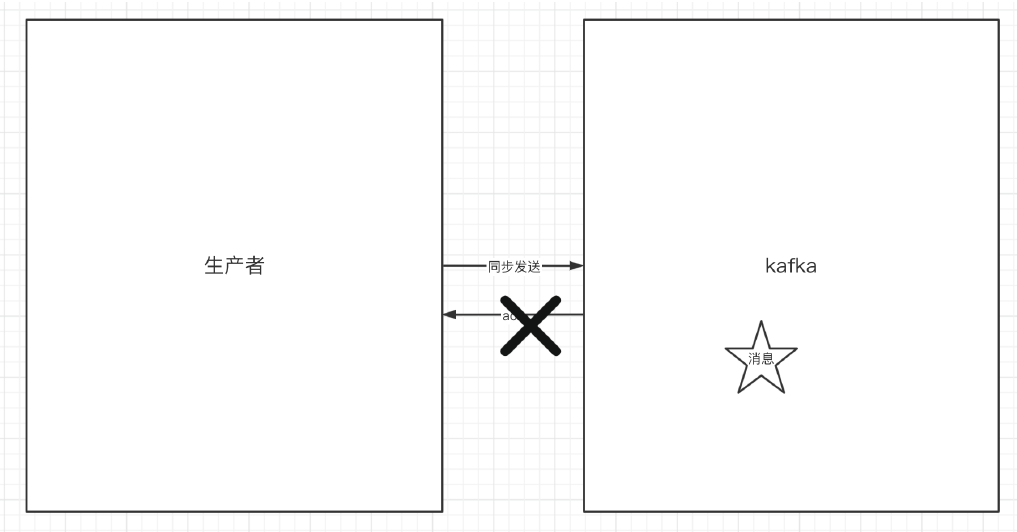
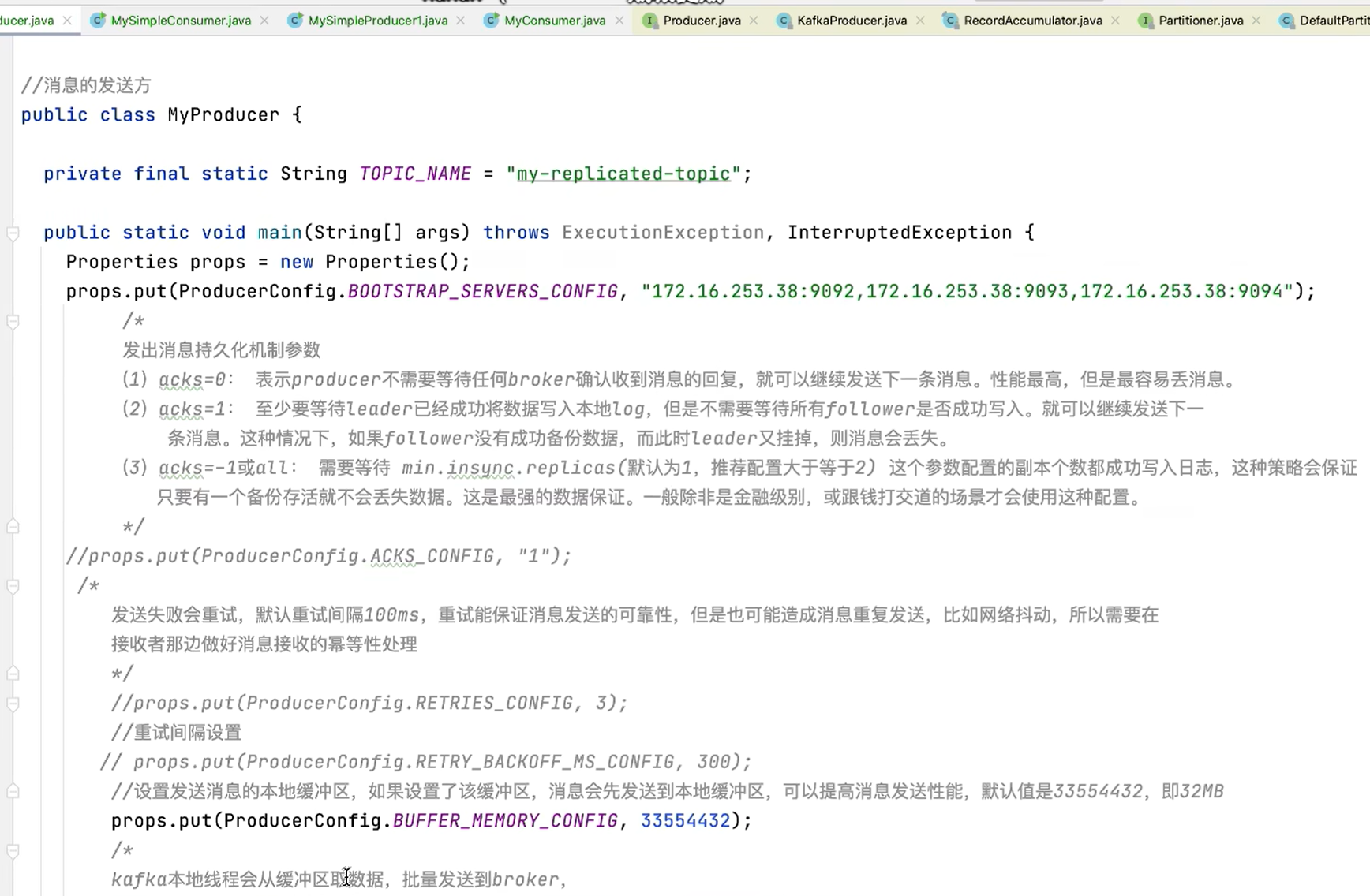
- 如果生产者发送消息没有收到ack,生产者会阻塞,阻塞到3s的时间,
- 如果还没有收到消息,会进行重试,重试的次数3次。

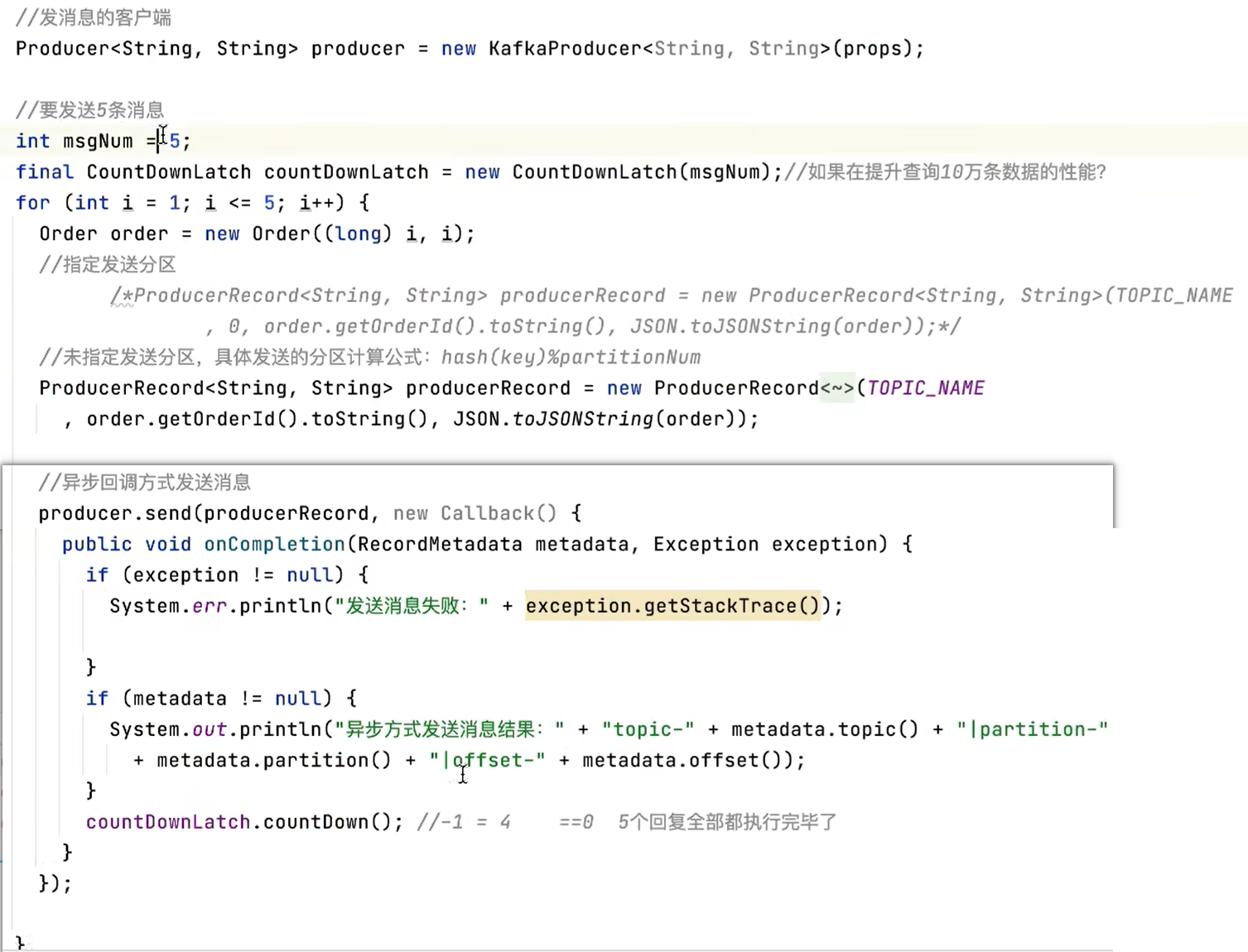
9.1.3 生产者的异步发送消息
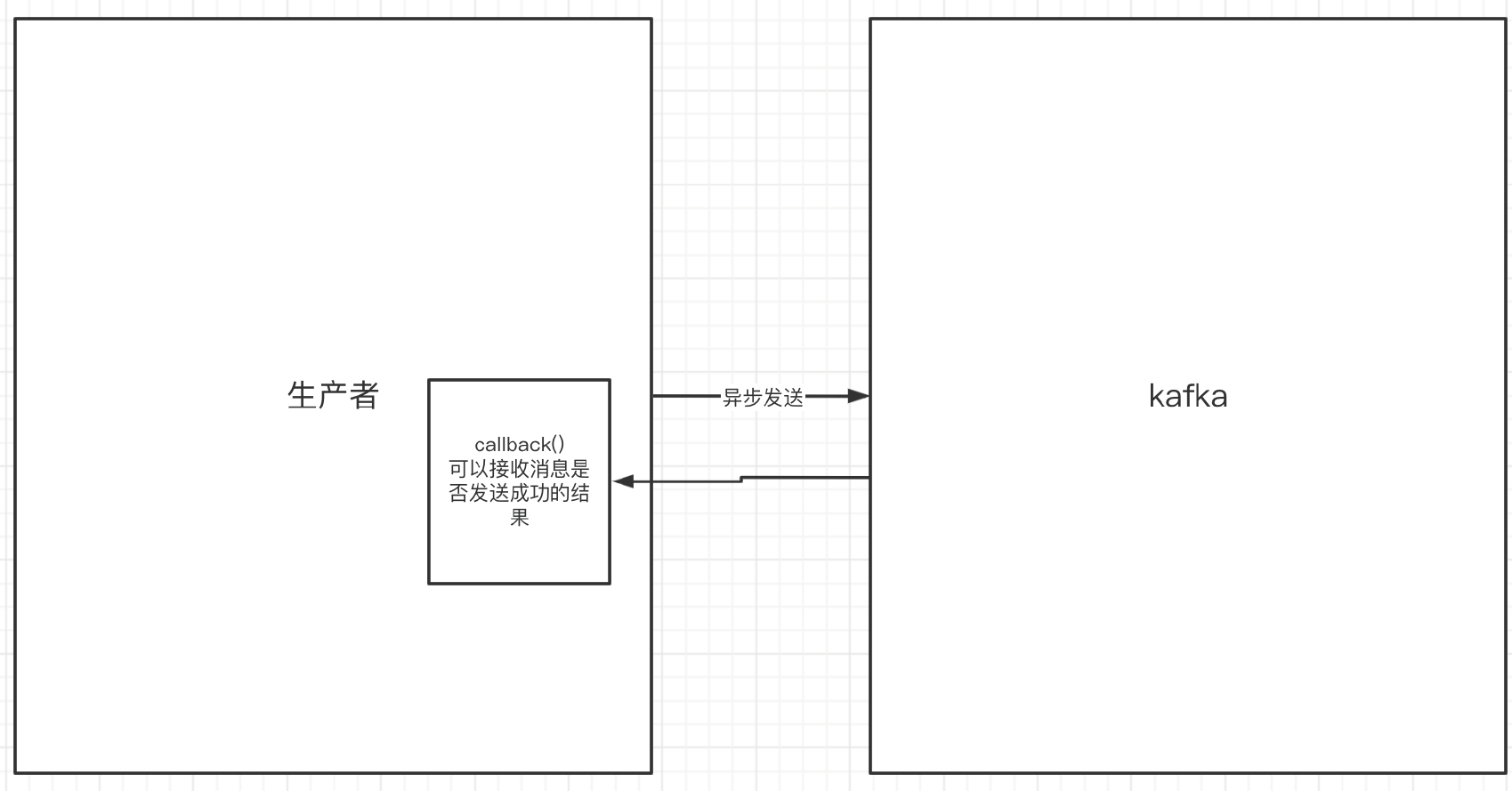
- 异步发送,生产者发送完消息后就可以执行之后的业务,
- broker在收到消息后异步调用生产者提供的callback回调方法。

9.1.4 生产者中的ack的配置
在同步发送的前提下,生产者在获得集群返回的ack之前会⼀直阻塞。那么集群什么时候返回
ack呢?此时ack有3个配置:
- ack = 0
kafka-cluster不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息的,效率是最高的- ack=1(默认)
多副本之间的leader已经收到消息,并把消息写入到本地的log中,才会返回ack给生产者,性能和安全性是最均衡的- ack=-1/all
里面有默认的配置min.insync.replicas=2(默认为1,推荐配置大于等于2),此时就需要leader和⼀个follower同步完后,才会返回ack给生产者(此时集群中有2个broker已完成数据的接收),这种方式最安全,但性能最差。

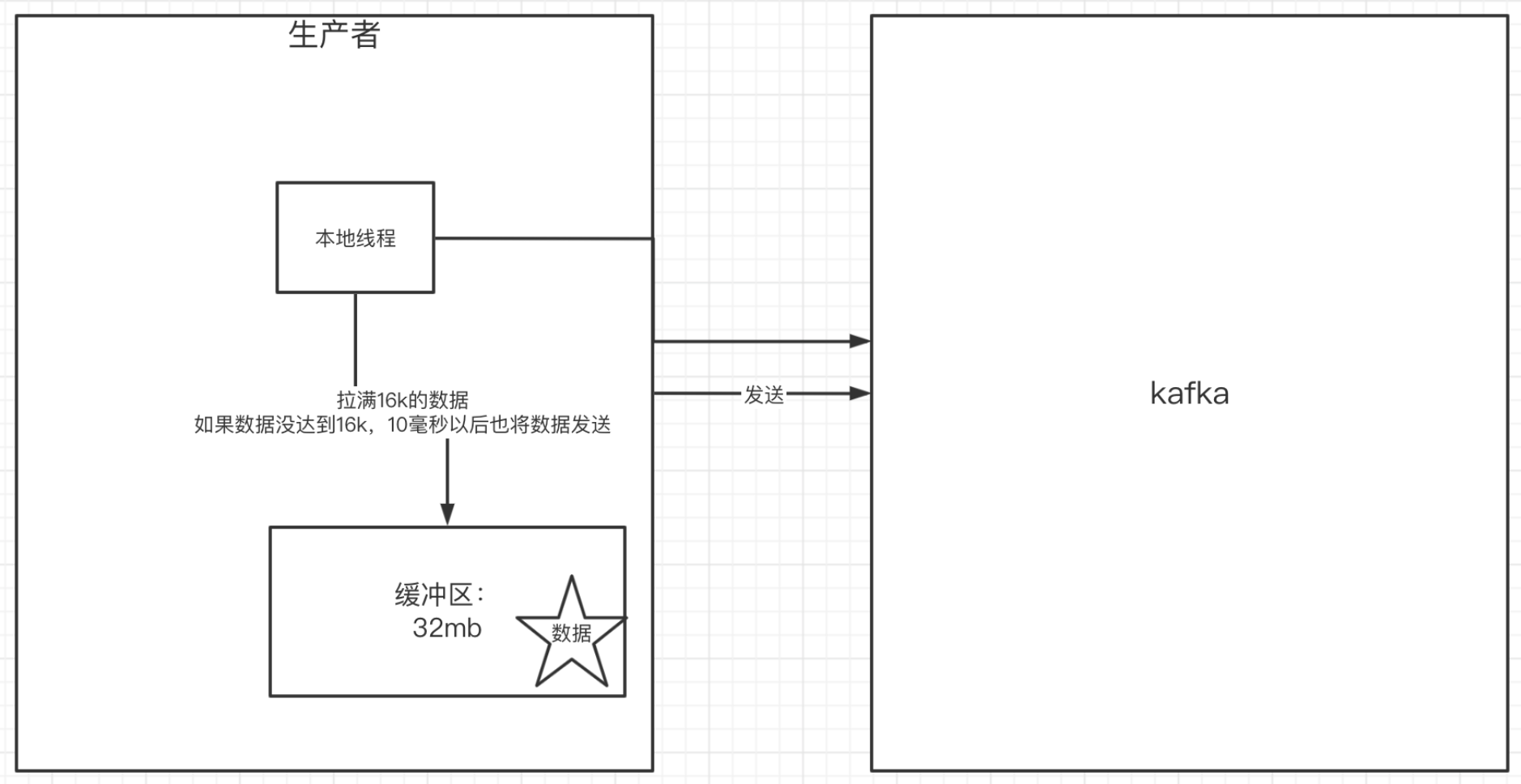
9.1.5 关于消息发送的缓冲区

9.2 消费者实现
9.2.1 消费者消费消息的基本实现

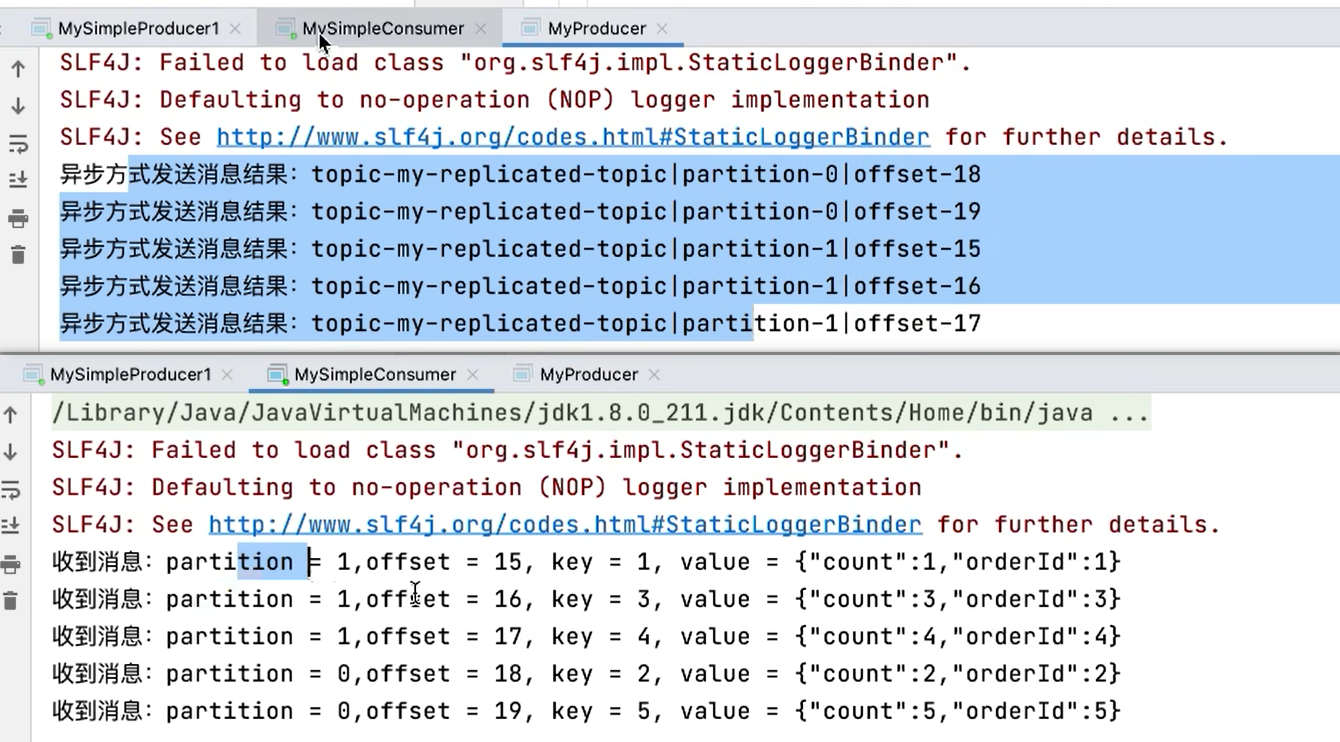
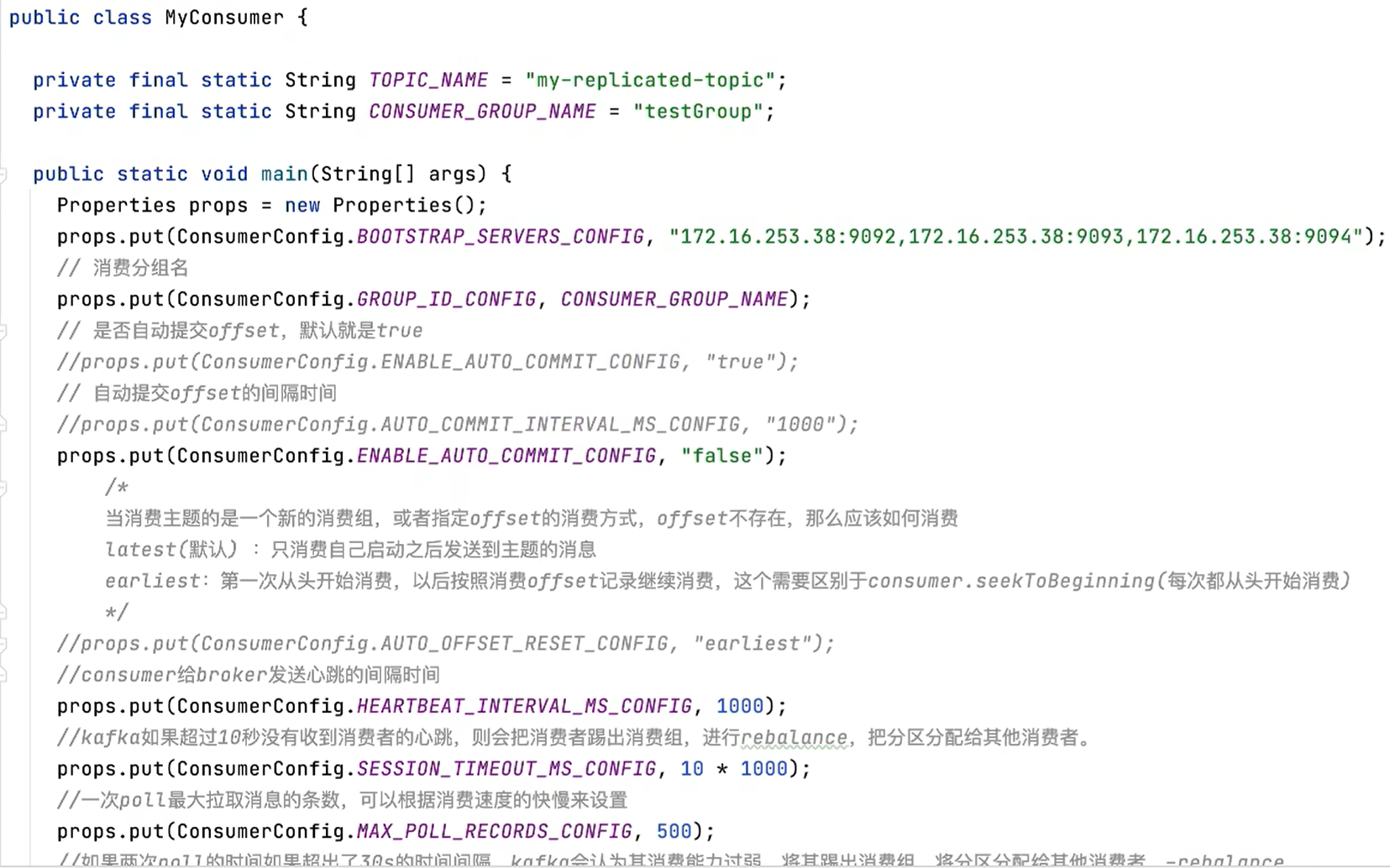
9.2.2 关于消费者自动提交和手动提交offset
提交的内容
消费者无论是自动提交还是手动提交,都需要把所属的消费组+消费的某个主题+消费的某个
分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题里面。
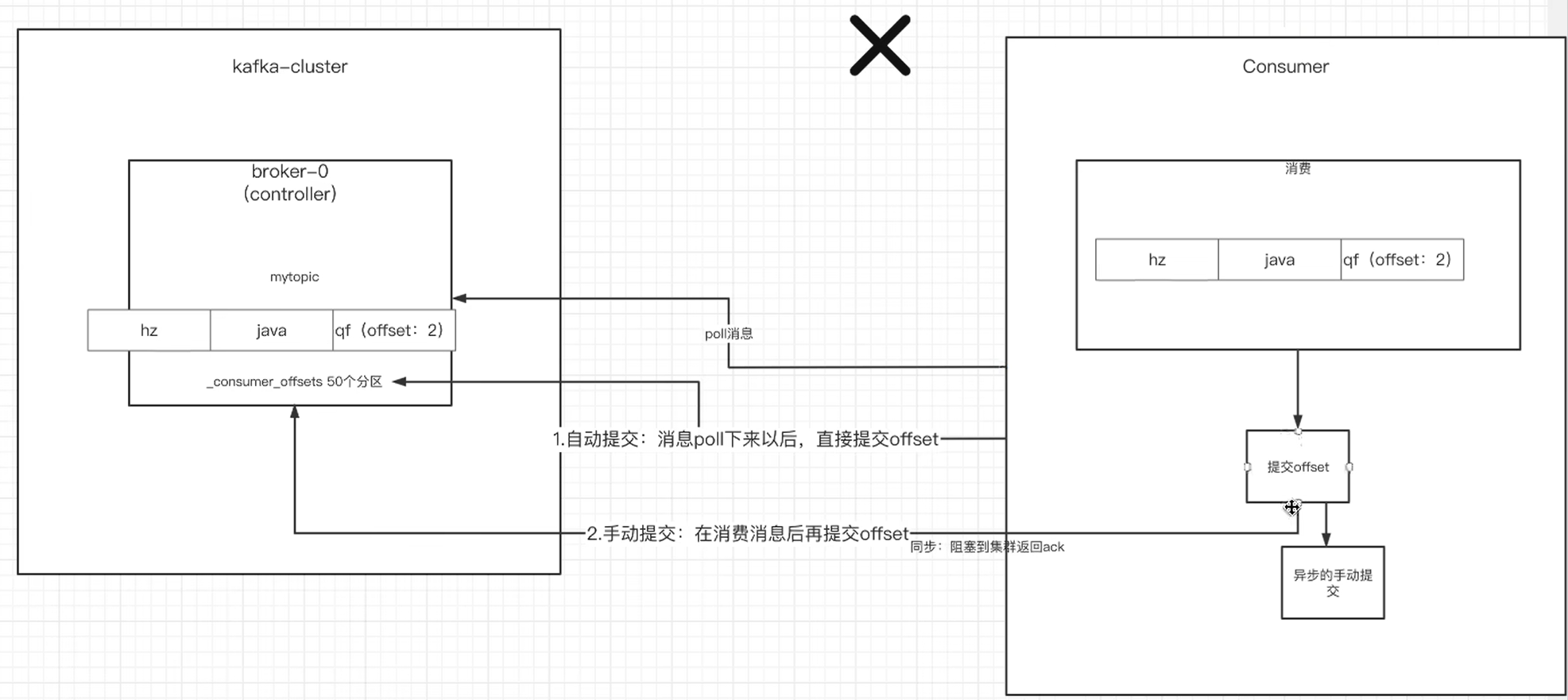
自动提交
消费者poll消息下来以后就会自动提交offset

- 消费者poll到消息后,默认情况下,会自动向broker的_consumer_offsets主题提交当前主题-分区消费的偏移量。
- 自动提交会丢消息:因为如果消费者还没消费完poll下来的消息就自动提交了偏移量,那么此时消费者挂了,于是下一个消费者会从已提交的offset的下一个位置开始消费消息,之前未被消费的消息就丢失掉了。
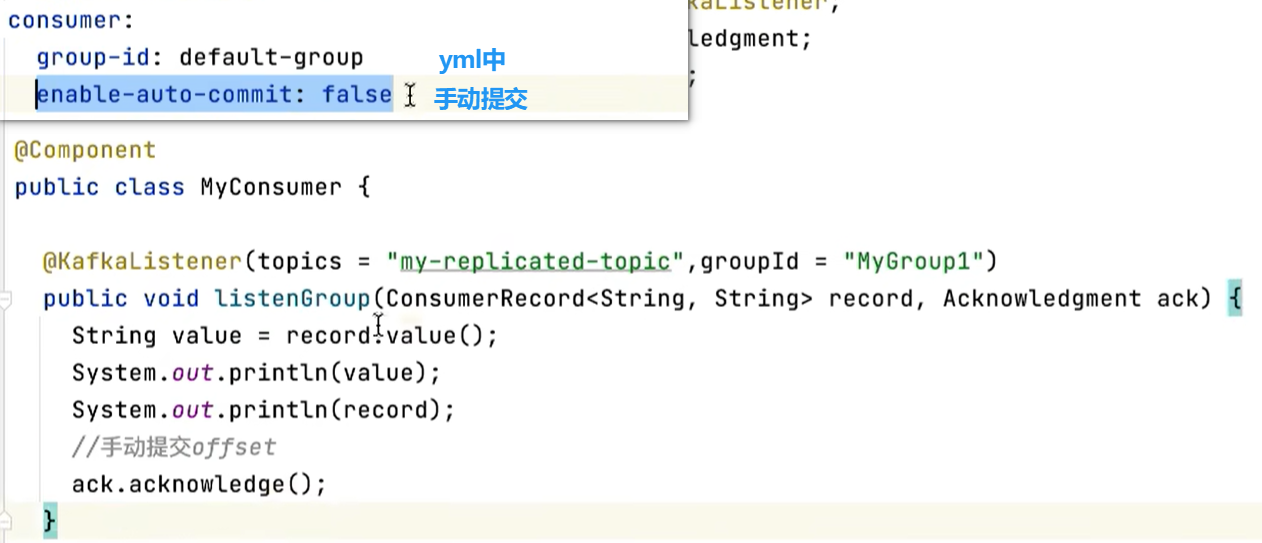
手动提交
需要把自动提交的配置改成false

在消费完消息后进行手动提交。手动提交又分成了两种:
- 手动同步提交
在消费完消息后调用同步提交的方法,当集群返回ack前⼀直阻塞,返回ack后表示提交
成功,执行之后的逻辑。

- 手动异步提交
在消息消费完后提交,不需要等到集群ack,直接执行之后的逻辑,可以设置⼀个回调方法,供集群调用。

9.2.3 长轮询poll消息
- 消费者建立了与broker之间的长连接,开始poll消息。
- 默认情况下,消费者⼀次会poll500条消息。

可以根据消费速度的快慢来设置,因为如果两次poll的时间如果超出了30s的时间间隔,kafka
会认为其消费能力过弱,将其踢出消费组。将分区分配给其他消费者。

- 如果每隔1s内没有poll到任何消息,则继续去poll消息,循环往复,直到poll到消息。如
果超出了1s,则此次长轮询结束。

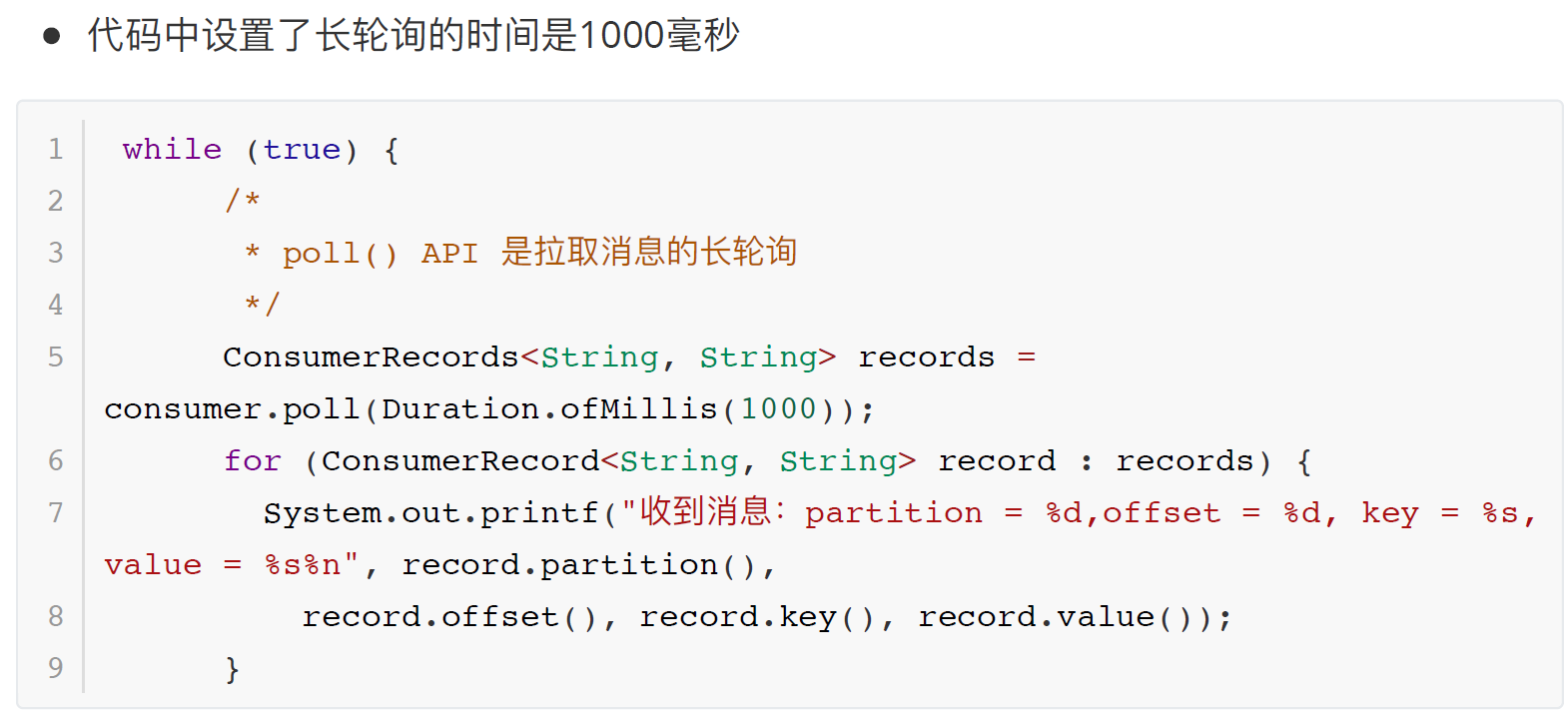
意味着:
- 如果一次poll到500条,就直接执行for循环;
- 如果这一次没有poll到500条,且时间在1秒内,那么长轮询继续poll,要么到500条,要么到1s;
- 如果多次poll都没达到500条,且1秒时间到了,那么直接执行for循环。
如果两次poll的间隔超过30s,集群会认为该消费者的消费能力过弱,该消费者被踢出消费组,触发rebalance机制,rebalance机制会造成性能开销。可以通过设置这个参数,让一次poll的消息条数少一点。
9.2.4 消费者的健康状态检查
消费者每隔1s向kafka集群发送心跳,集群发现如果有超过10s没有续约的消费者,将被踢出
消费组,触发该消费组的rebalance机制,将该分区交给消费组里的其他消费者进行消费。
- 消费者发送心跳的时间间隔

- kafka如果超过10秒没有收到消费者的心跳,则会把消费者踢出消费组,进行rebalance,把分区分配给其他消费者

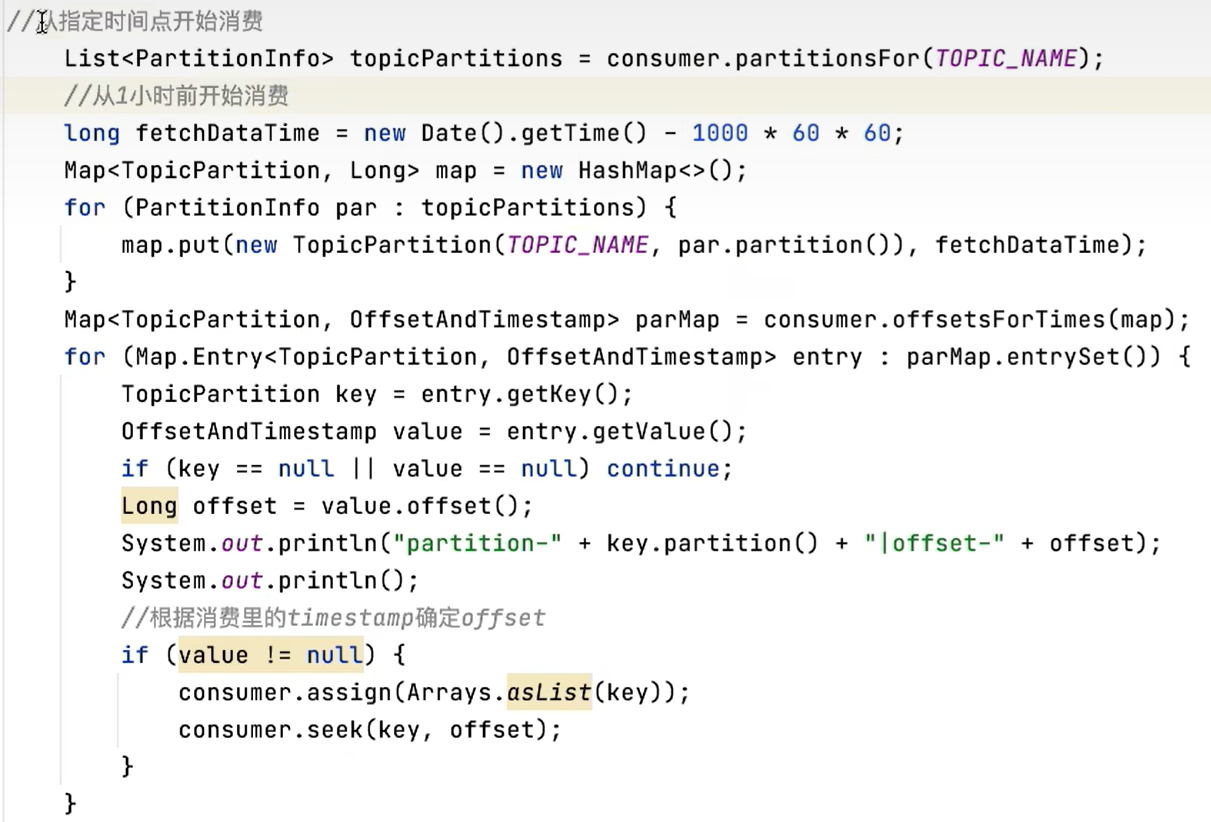
9.2.5 指定分区和偏移量、时间消费
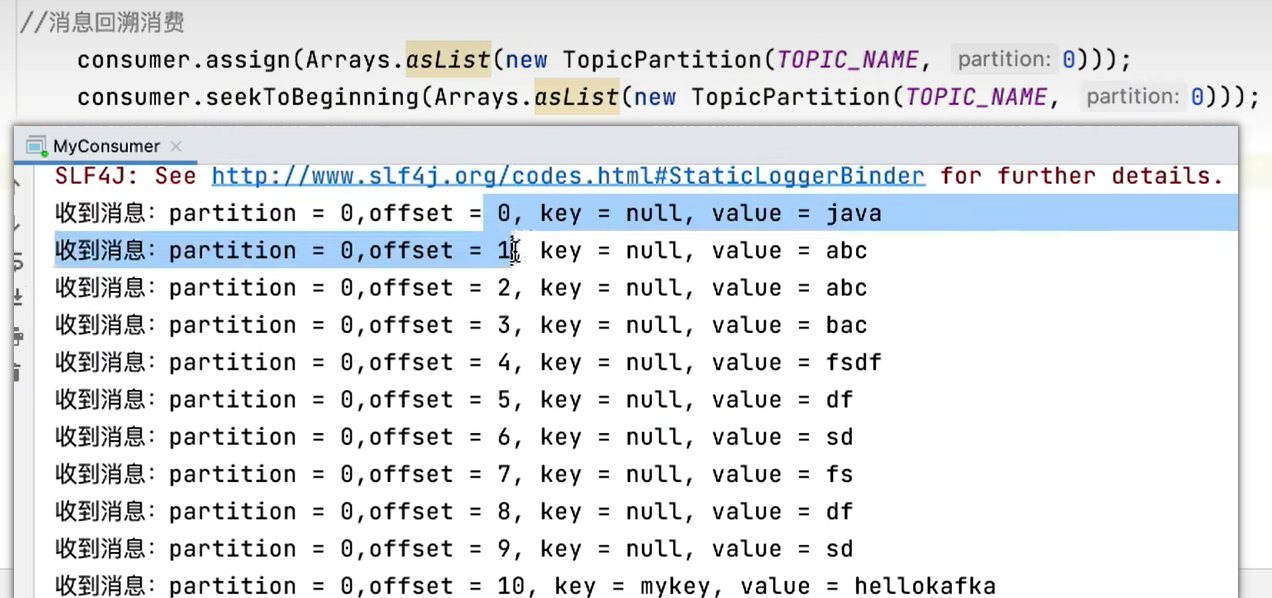
- 指定分区消费

- 从头消费(消息回溯消费)

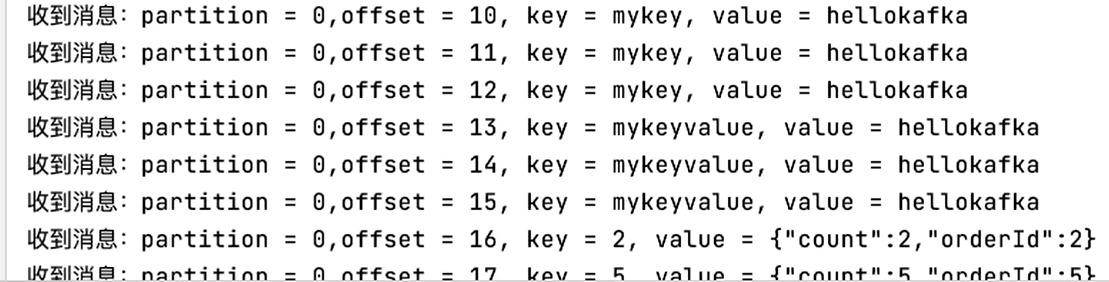
- 指定offset消费


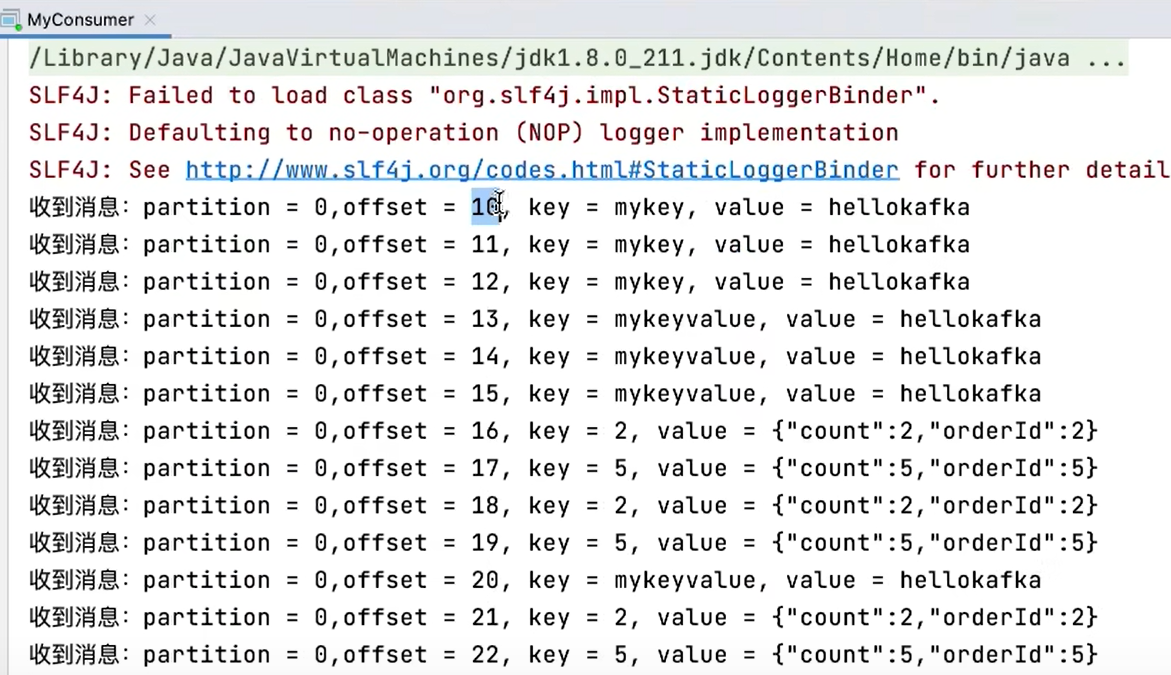
- 指定时间消费
根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition中找到该offset之后的消息开始消费。
(partition-0被覆盖)
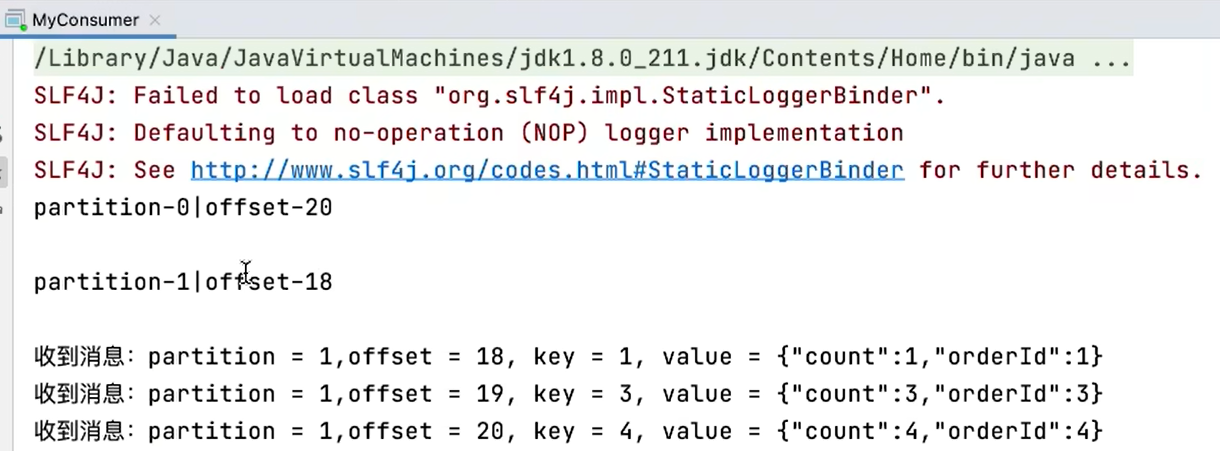
9.2.6 新消费组的消费offset规则
新消费组中的消费者在启动以后,默认会从当前分区的最后一条消息的offset+1开始消费(消费新消息)。可以通过以下的设置,让新的消费者第一次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)
- Latest:默认的,消费新消息
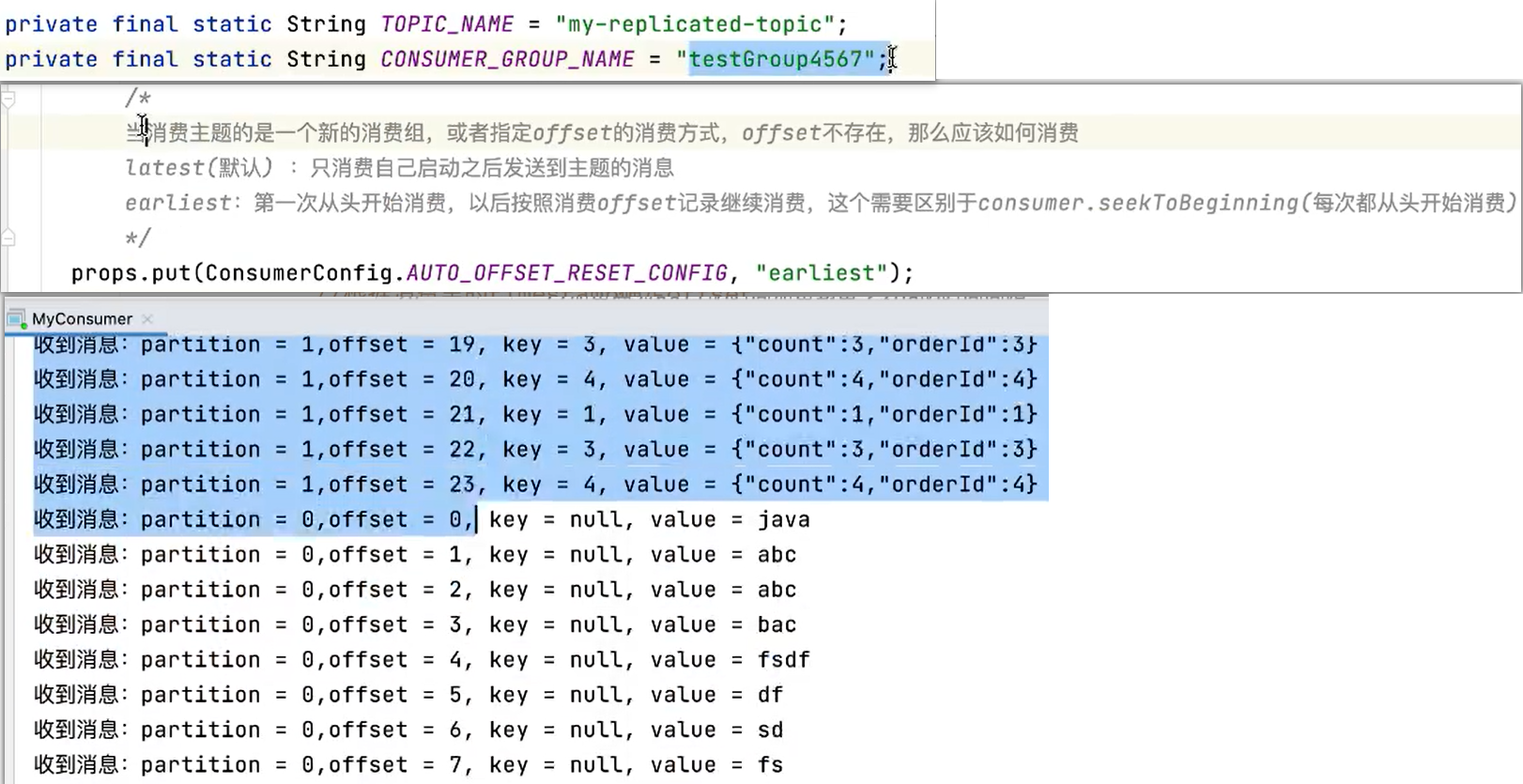
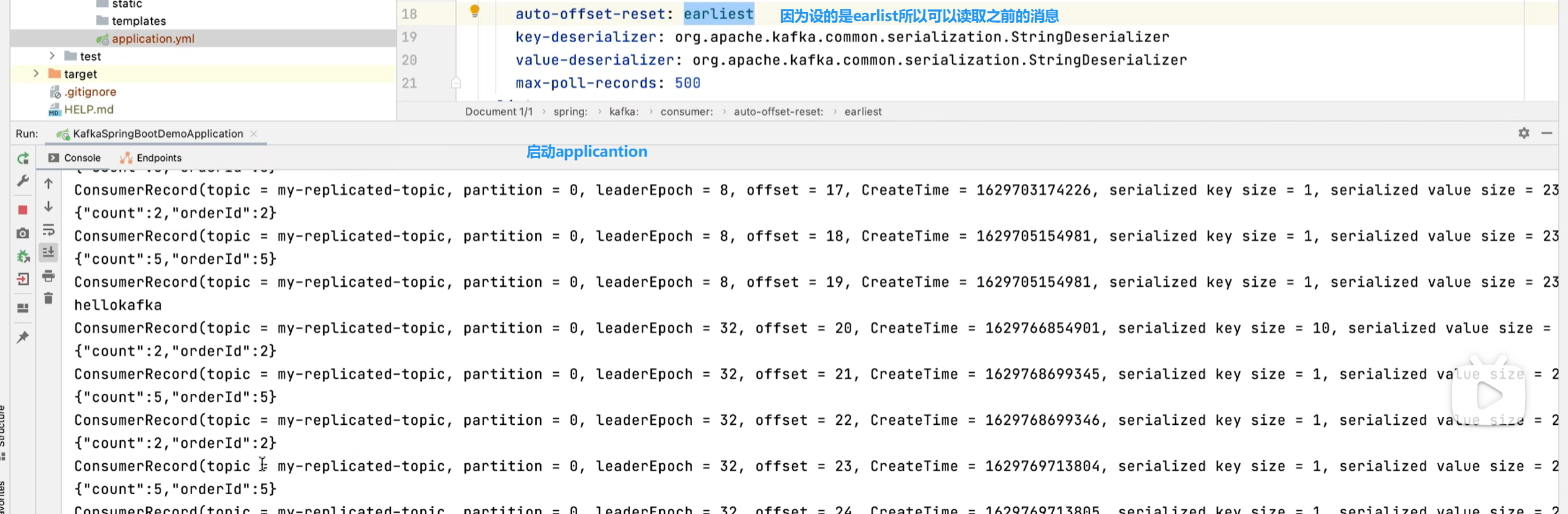
- earliest:第一次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)

默认方式(Latest)
启动后没有拿到任何消息。
生产者再发消息,消费者可以拿到消息。

earliest,启动后就可以拿到消息
MyProducer


MyConsumer



10. Springboot中使用Kafka
10.1 引入依赖

10.2 编写配置文件

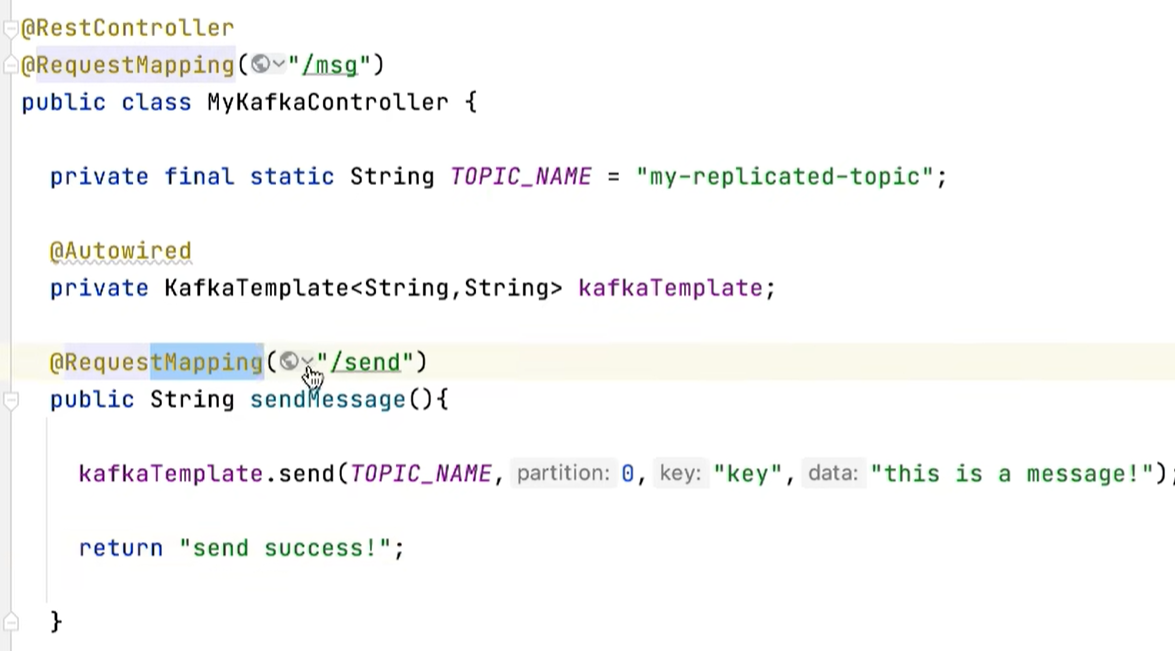
10.3 编写消息生产者
10.4 编写消费者
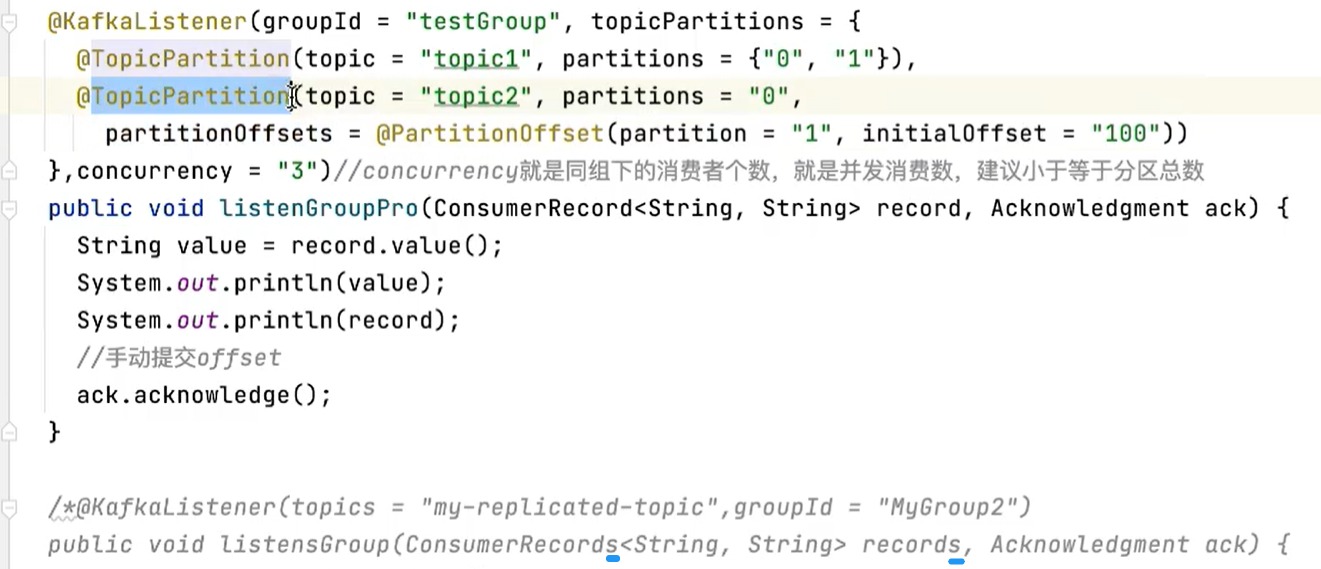
10.5 消费者中配置消费主题、分区和偏移量

11. kafka集群中的controller、reblance、HW
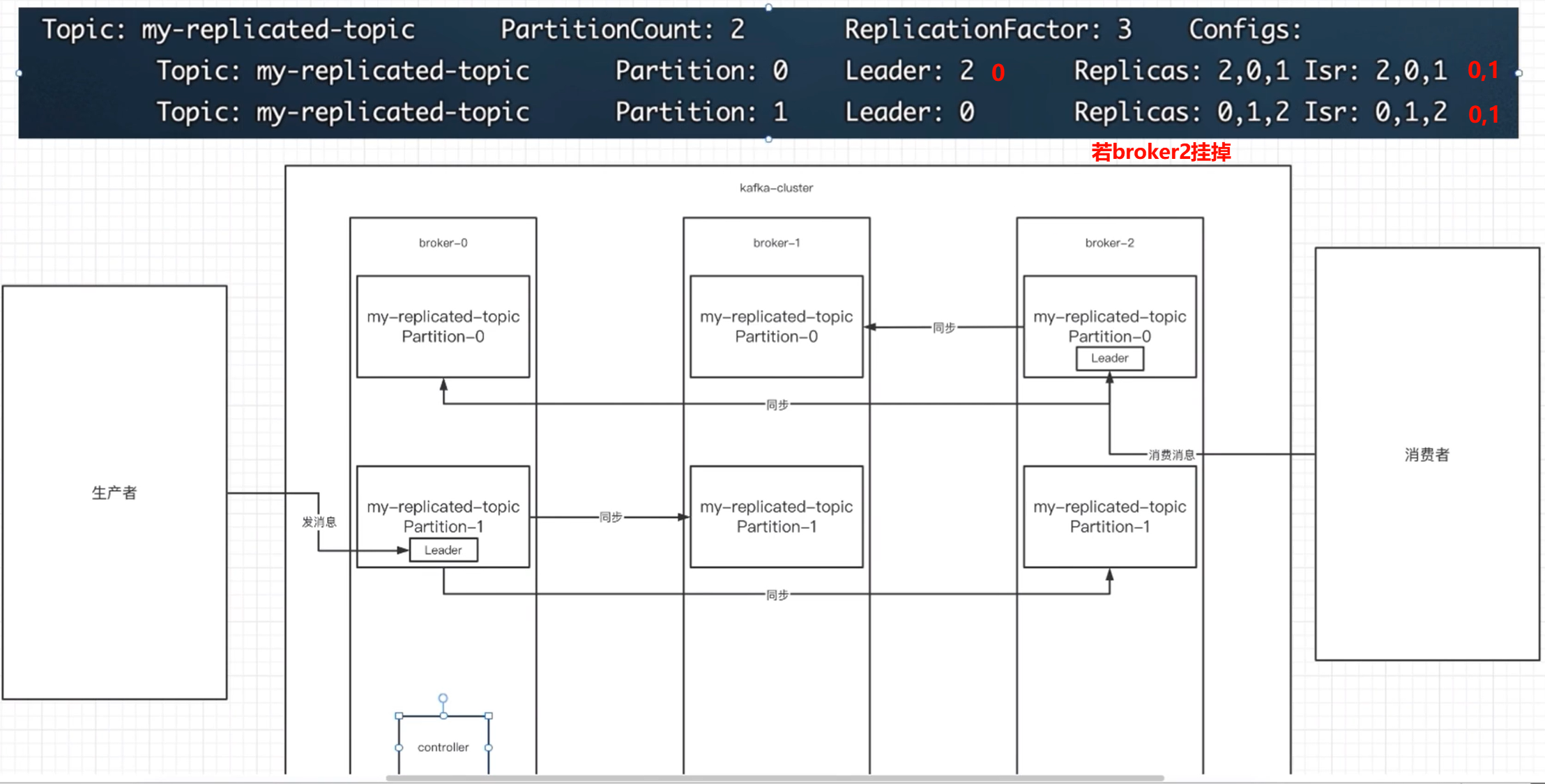
11.1 controller
集群中谁来充当controller
每个broker启动时会向zk创建一个临时序号节点,获得的序号最小的那个broker将会作为群中的controller,负责这么几件事:
- 当集群中有一个副本的leader挂掉,需要在集群中选举出一个新的leader,选举的规则是从isr集合中最左边获得。
- 当集群中有broker新增或减少,controller会同步信息给其他broker。
- 当集群中有分区新增或减少,controller会同步信息给其他broker。
11.2 rebalance机制
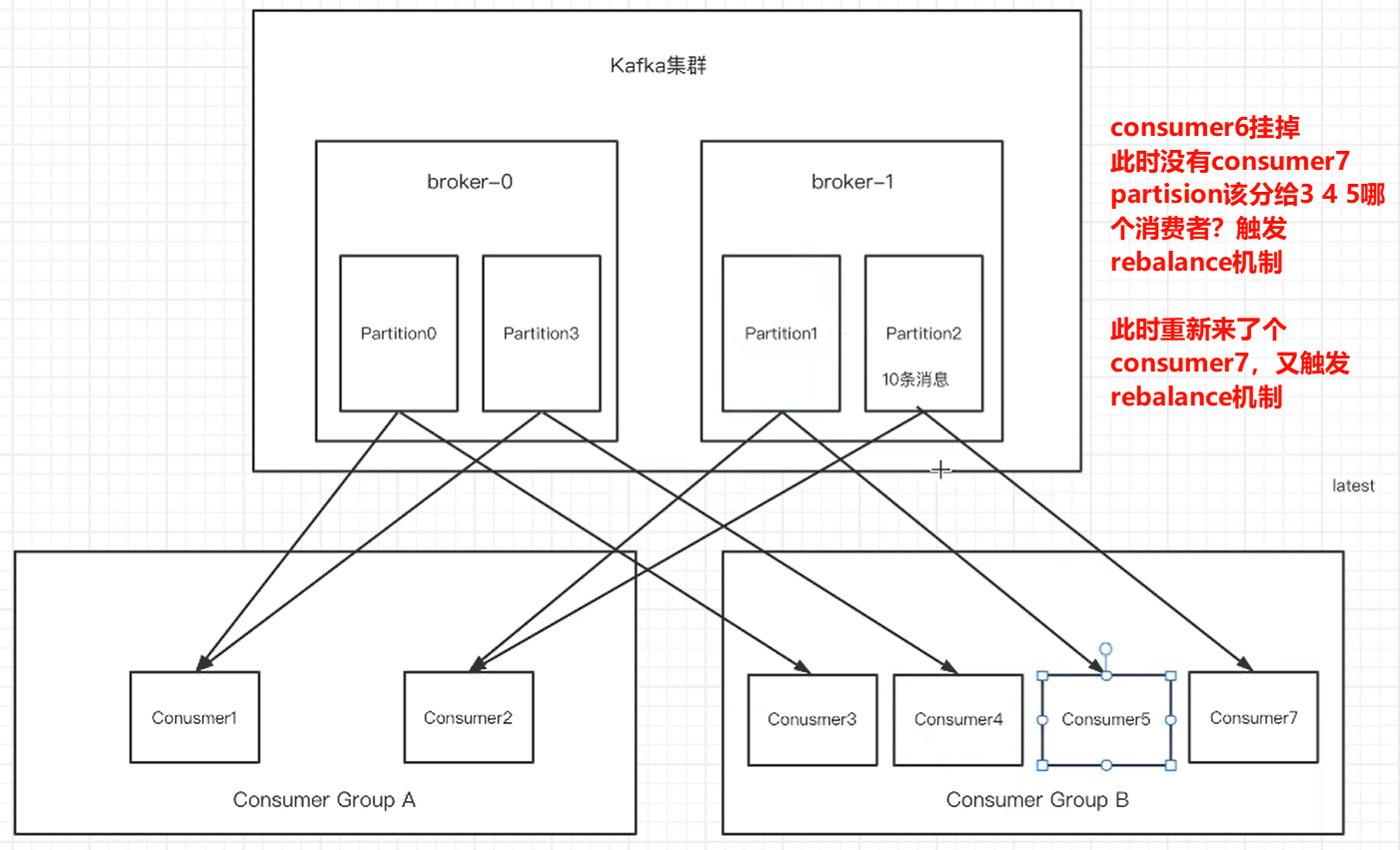
- 前提:消费组中的消费者没有指明分区来消费
- 触发的条件:当消费组中的消费者和分区的关系发生变化的时候.
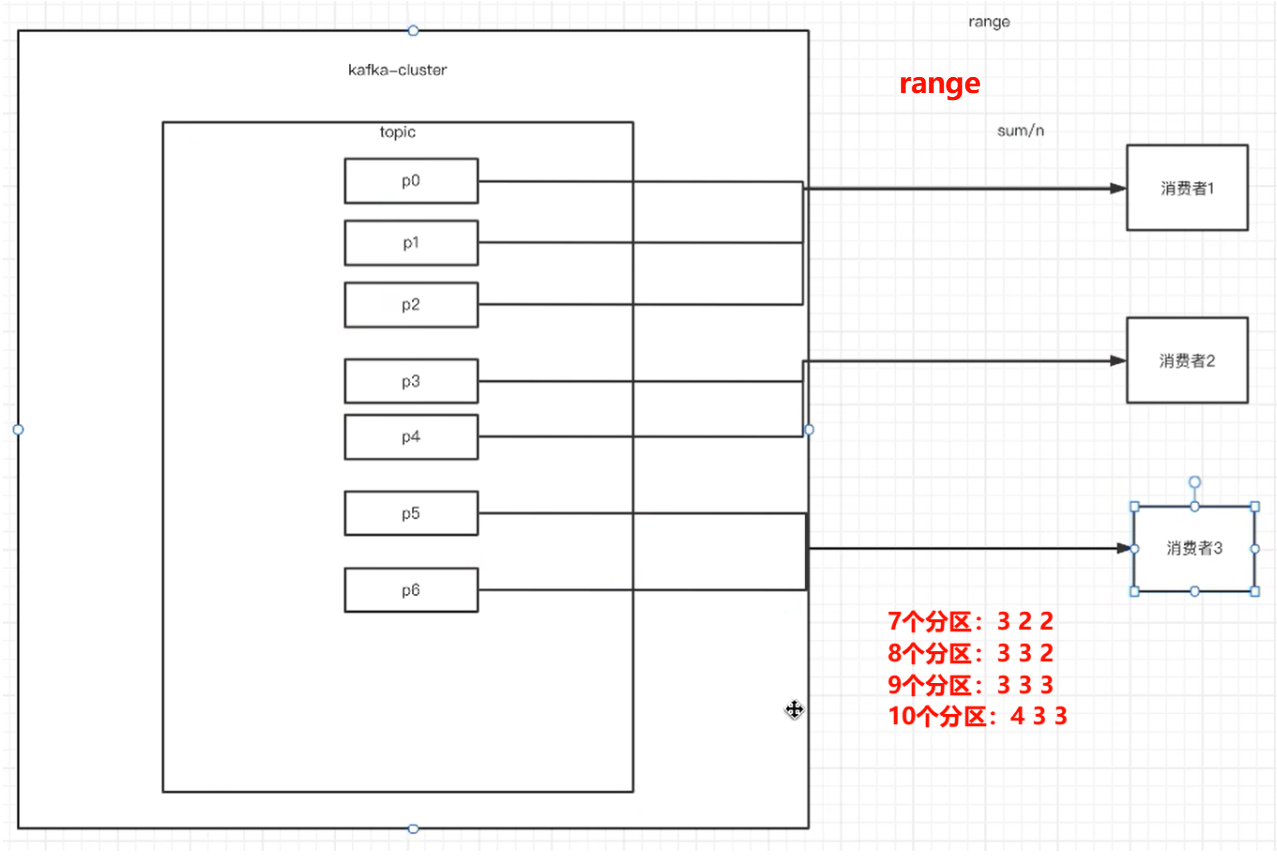
- 分区分配的策略:在rebalance之前,分区怎么分配会有这么三种策略
①range:根据公式计算得到每个消费者消费哪几个分区:
前 <分区数%消费者数量> 的消费者分配 <分区数/消费者数量+1>个分区,
其余的消费者分配 <分区数/消费者数量> 个分区。
②轮询:大家轮着来
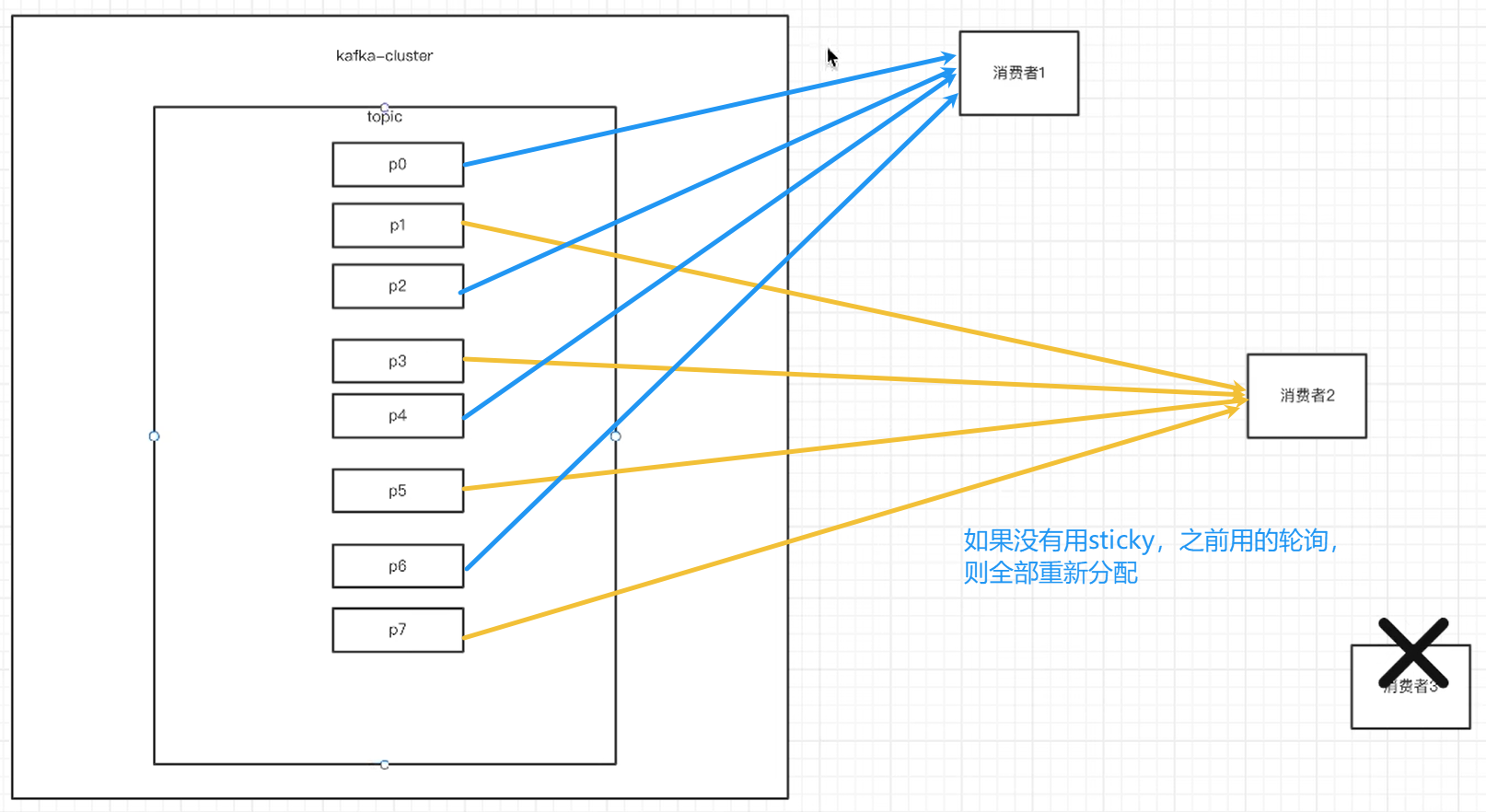
③sticky:粘合策略,如果需要rebalance,会在之前已分配的基础上调整,不会改变之前的分配情况。如果这个策略没有开,那么就要进行全部的重新分配。建议开启。
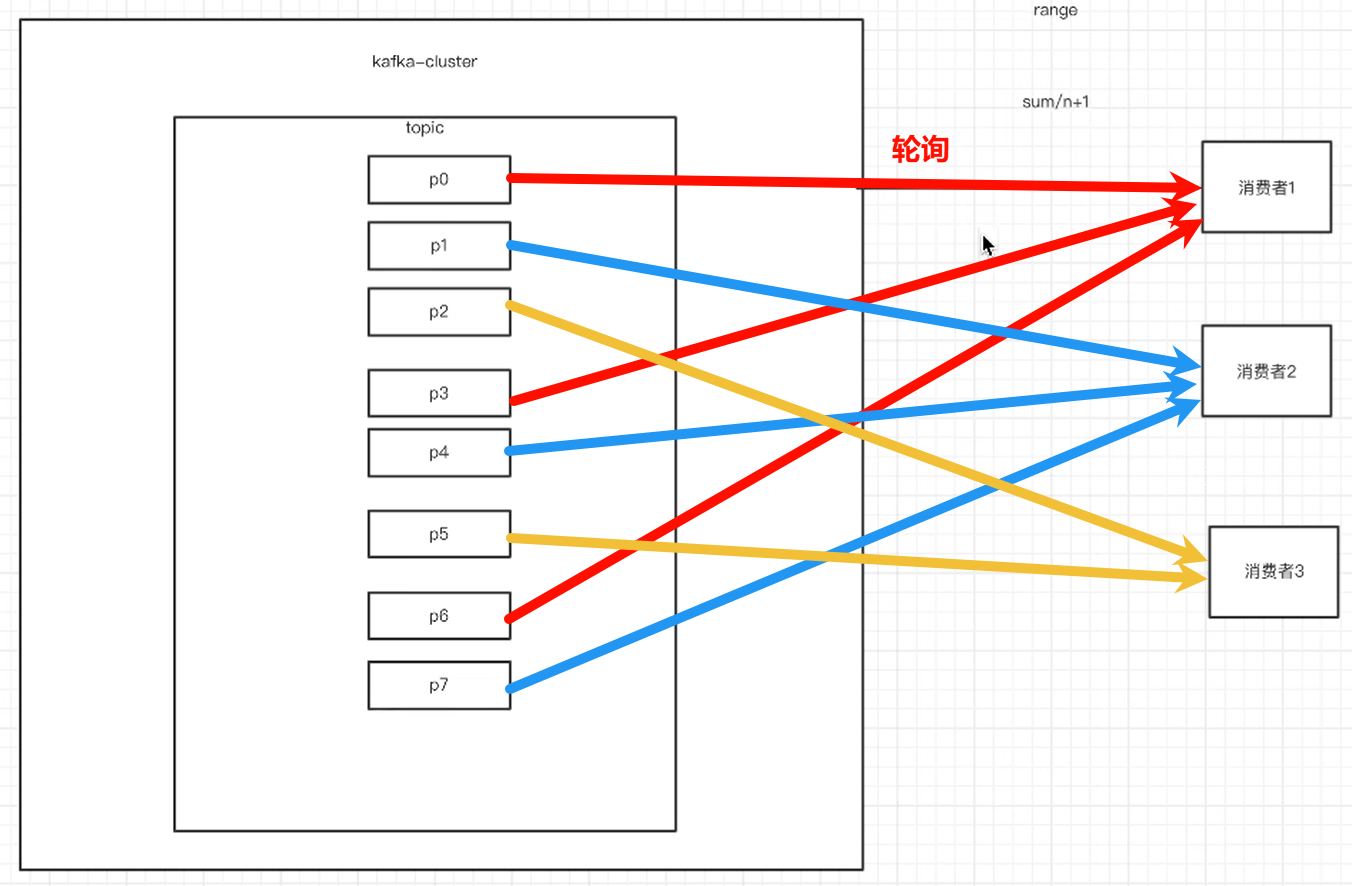
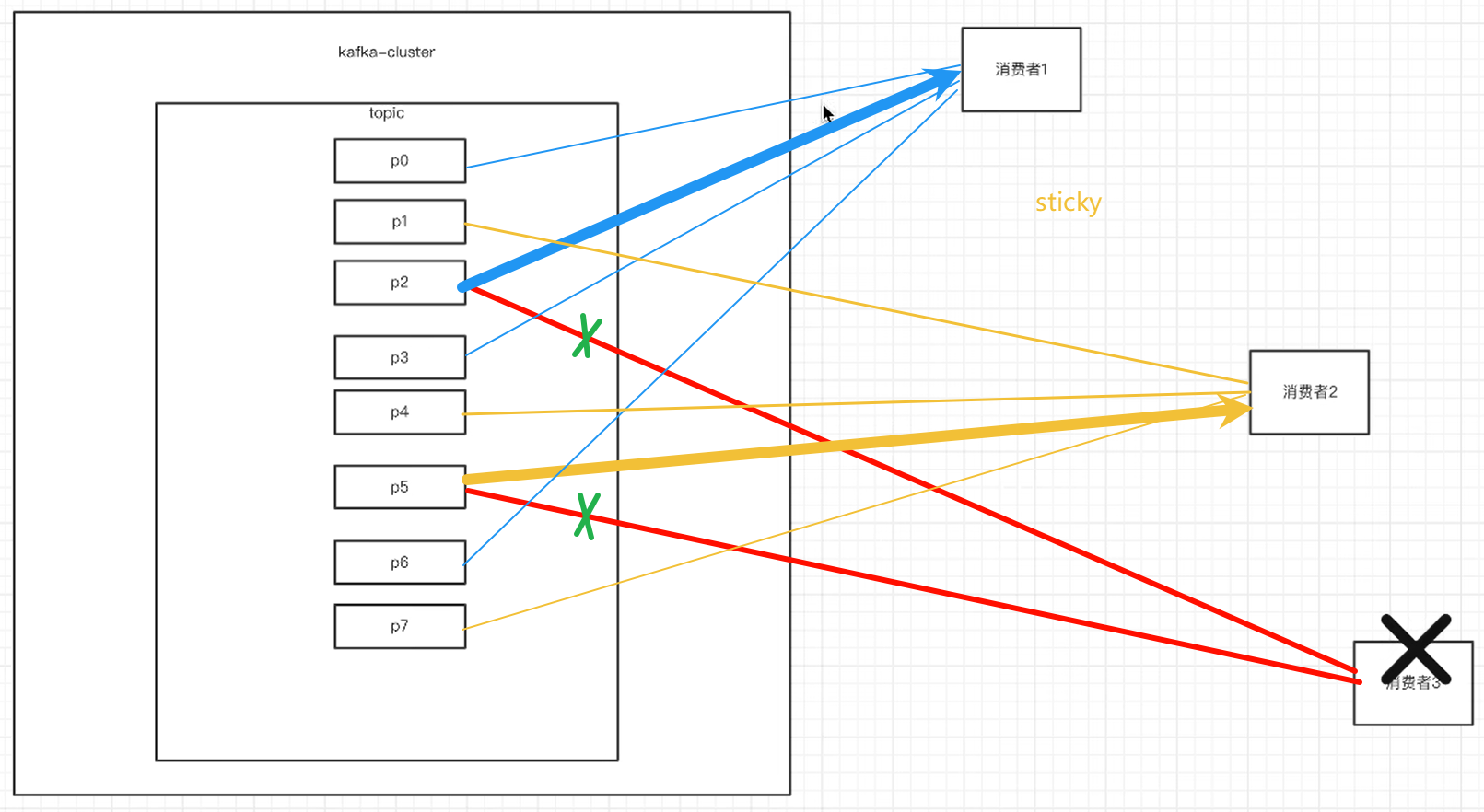
如果没有用sticky策略,那消费者挂掉触发rebalance,那之前如果用的是轮询,都要重新来一遍。
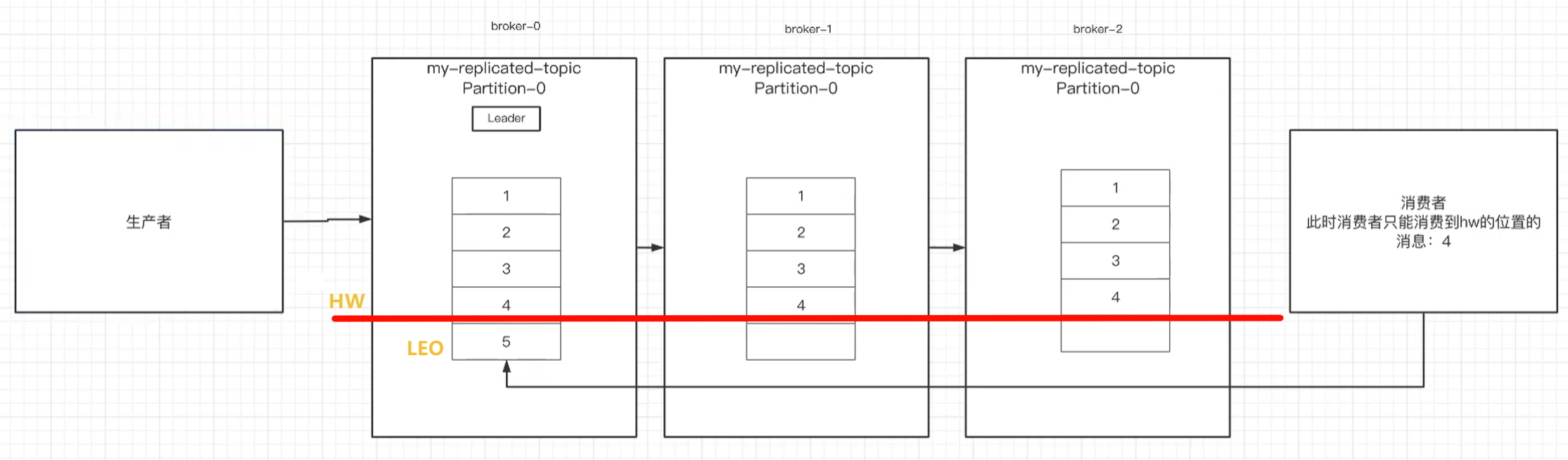
11.3 HW和LEO
- LEO:某个副本最后消息的消息位置(log-end-offset)
- HW(HighWatermark 高水位):
已完成同步的位置。
消息在写入broker时,且每个broker完成这条消息的同步后,hw才会变化。在这之前消费者是消费不到这条消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的目的是防止消息的丢失。
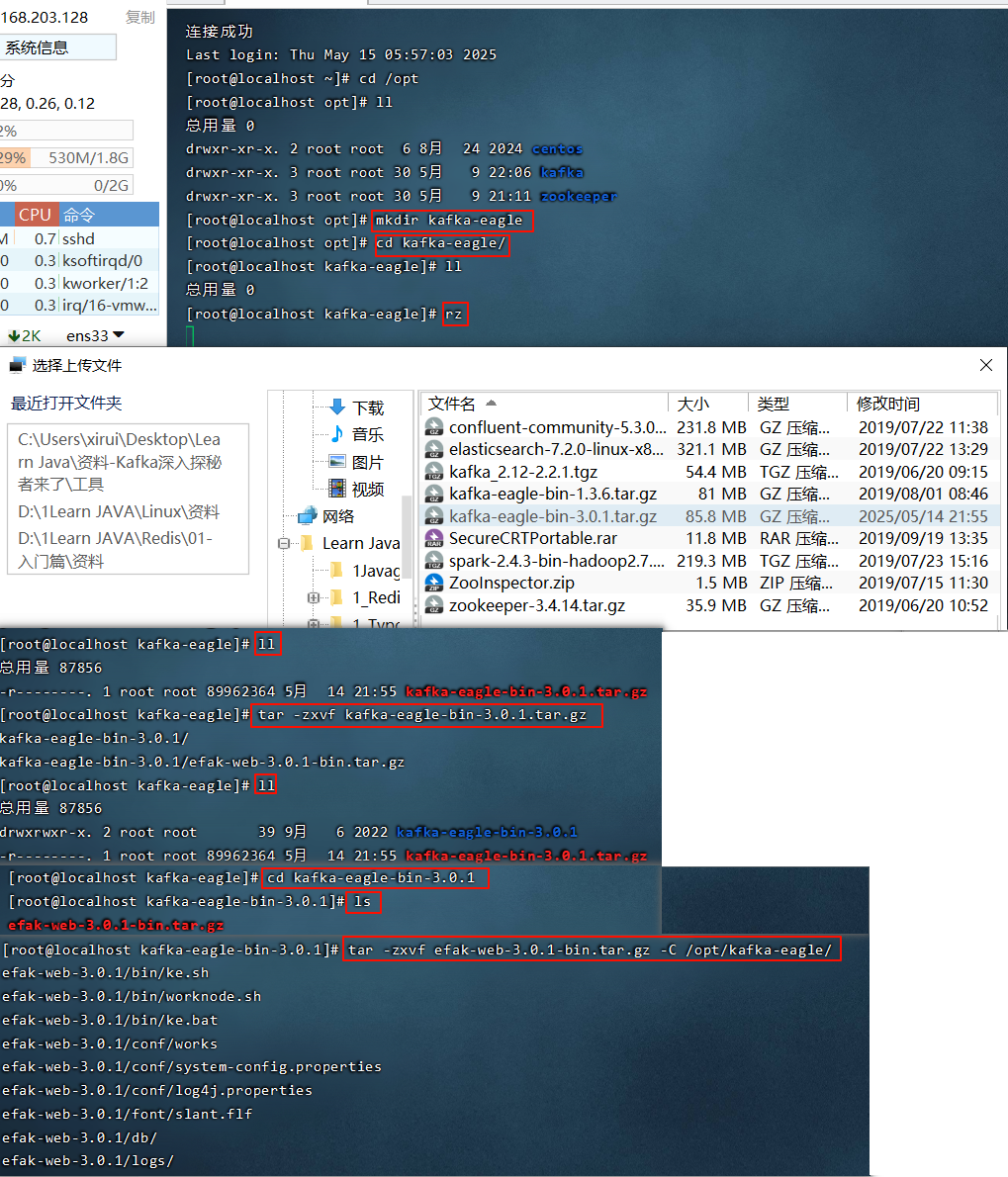
12. Kafka-eagle监控平台
12.1 搭建
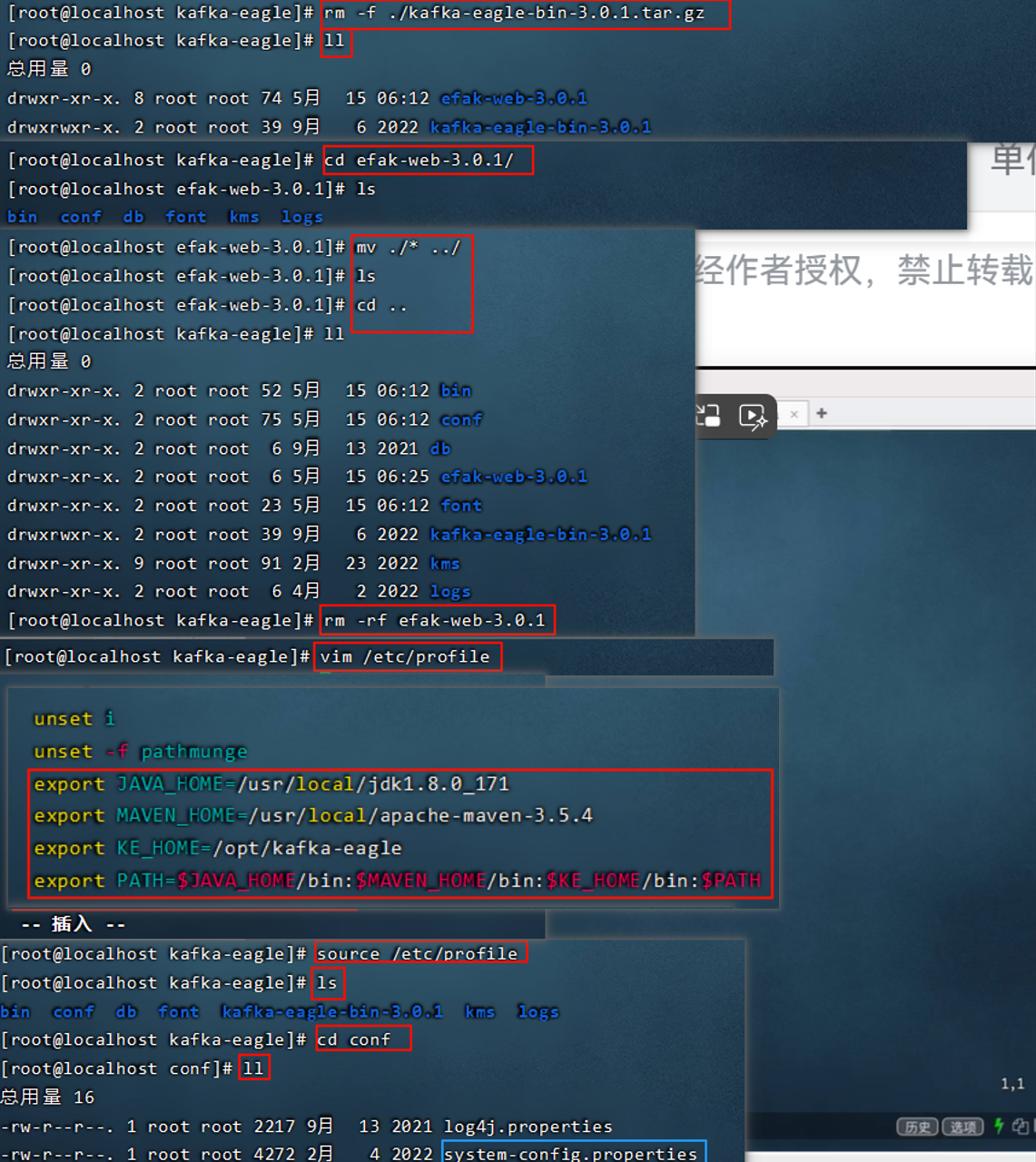
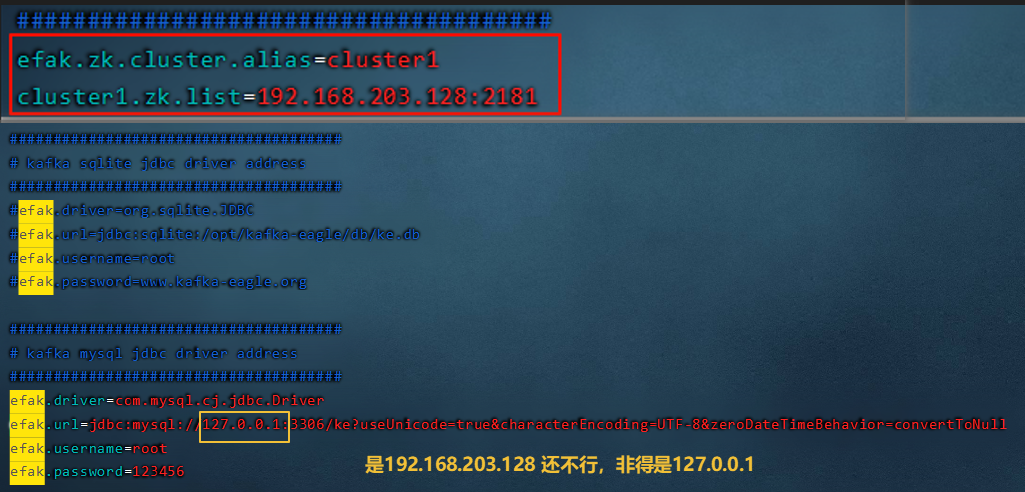
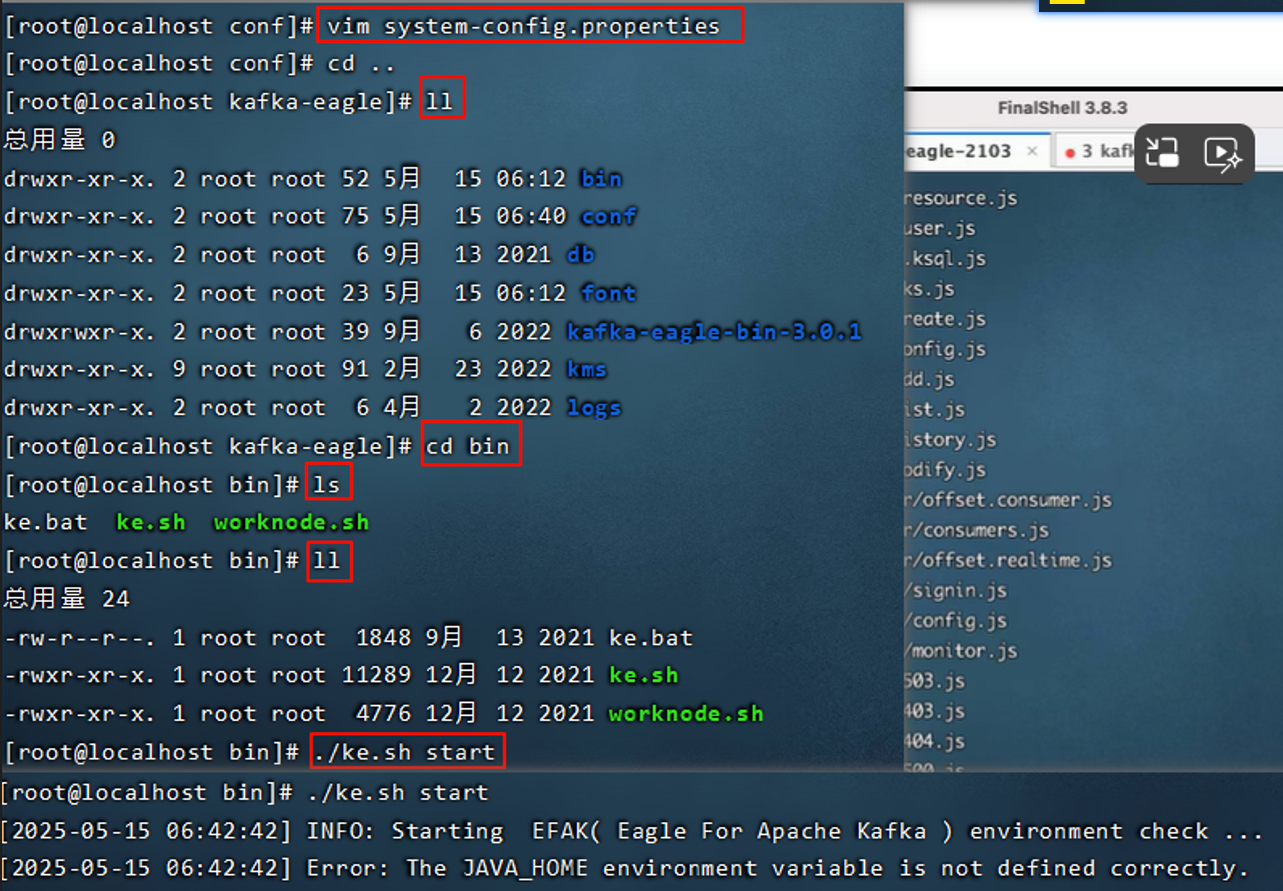
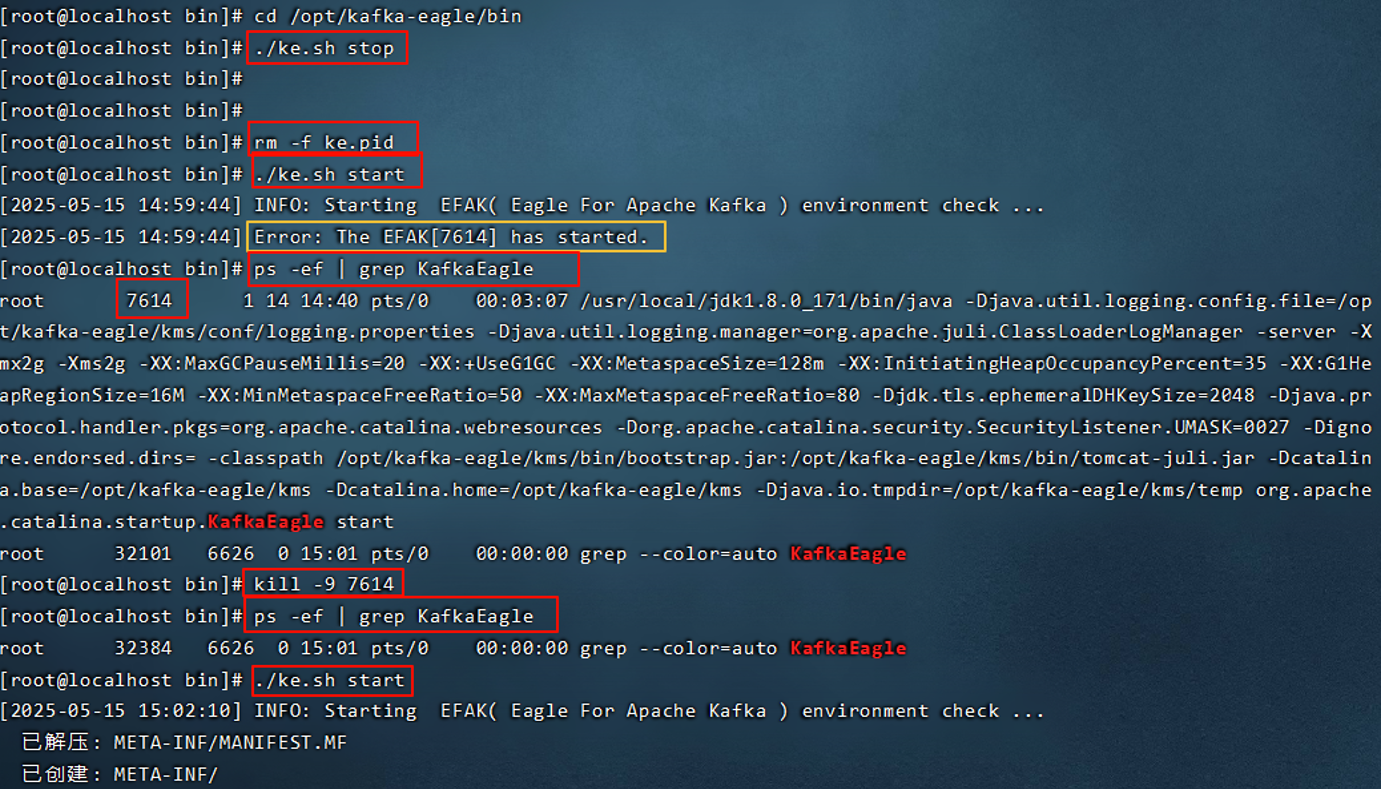
12.2 平台的使用
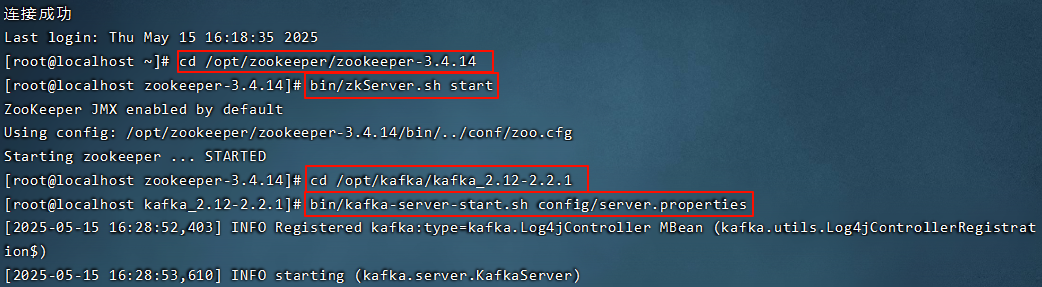
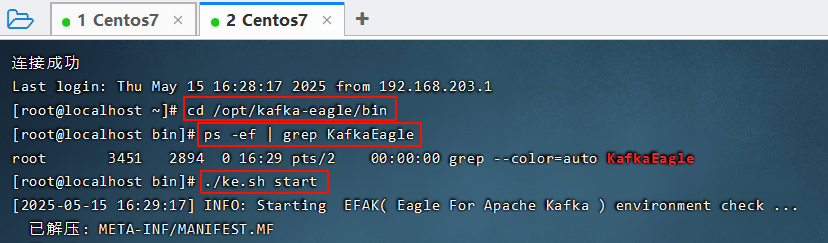
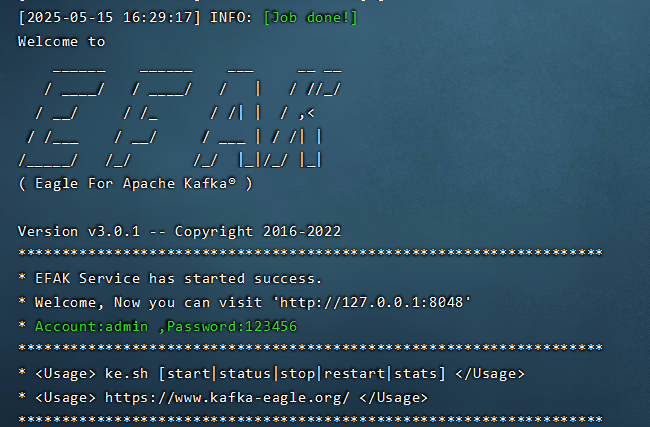
浏览器输入192.168.203.128.8040/ke