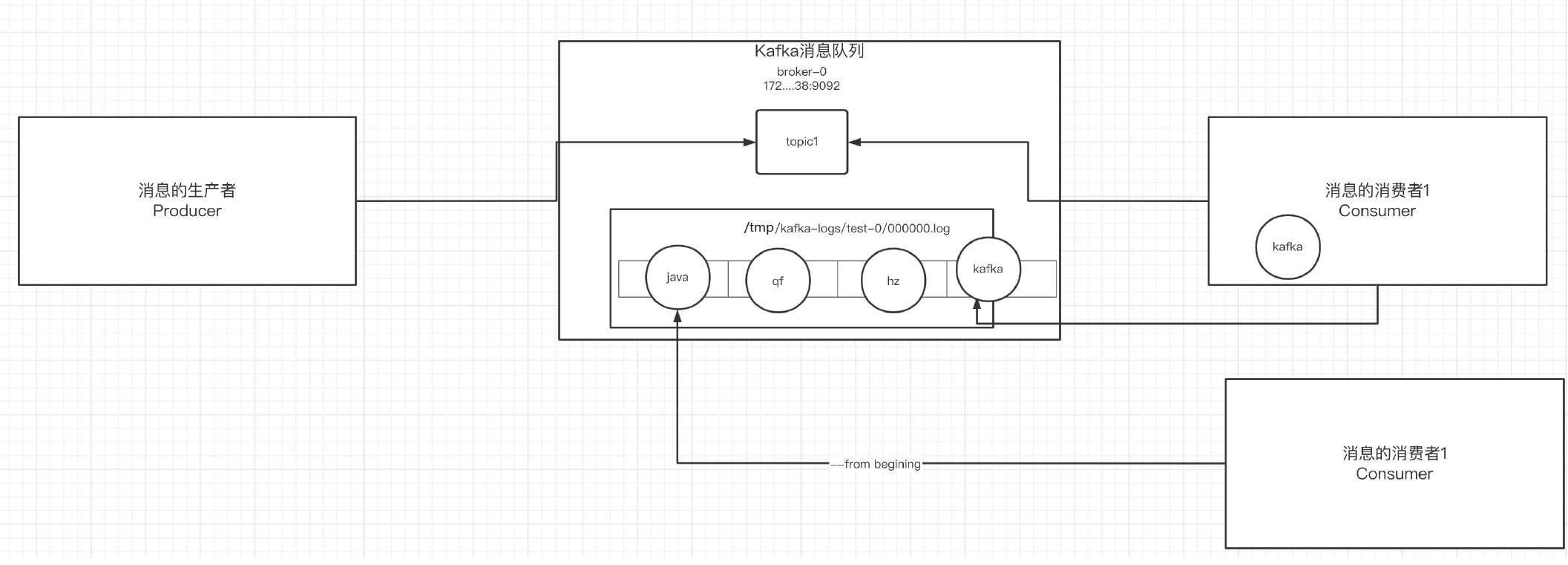
消息队列Kafka-1
1. 概念
| 概念 | 详细说明 |
|---|---|
| Producer(生产者) | 负责发送消息到 Kafka。可以是业务系统、日志系统等 |
| Consumer(消费者) | 从 Kafka 拉取消息进行处理的应用 |
| Topic(主题) | 类似于“消息的分类桶”,消息根据不同业务主题分类 |
| Partition(分区) | 一个 Topic 可被划分为多个分区,消息会落到不同分区中以提高并发能力 |
| Offset(偏移量) | 消息在每个分区中的唯一编号。消费者用 Offset 知道自己读到了哪条消息 |
| Broker | Kafka 集群中的一台服务器,负责存储 Topic 和消息 |
| Consumer Group(消费者组) | 一组消费者,协同消费一个 Topic,每条消息只被组内一个人处理,防止重复处理 |
| Leader & Follower(主副本机制) | 每个 Partition 有一个 Leader 副本负责读写,其它副本(Follower)做备份,用于容错 |
| ZooKeeper(或 KRaft) | Kafka 使用它来管理 Broker 状态、选举 Leader(Kafka 3.0+可选用KRaft替代) |
关系
生产者(Producer)
↓
发送消息
↓
Topic(主题) ← 多个 Topic 用来分类消息
↓
Partition(分区) ← 每个 Topic 可以有多个 Partition,增强并发
↓
Broker(Kafka服务器) ← 存储分区和消息
↓
Offset(编号) ← 用来标记消息在分区中的位置
↓
Consumer Group(消费者组) ← 多个消费者协作消费 Topic,每人消费部分 Partition
↓
每个消费者读消息 ↓
处理业务
↓
存数据库或做其他事
特性:
高吞吐量:Kafka 能处理大量消息,适用于大数据和高并发场景。
分布式架构:Kafka 是一个分布式系统,支持多台服务器处理数据。
高可用性:通过副本机制,即使服务器出现故障,数据也不会丢失。
消息持久化:Kafka 将消息持久化到磁盘,确保数据不会丢失。
支持发布-订阅模式和队列模式:Kafka 既支持发布-订阅模式,也支持队列模式,灵活满足不同需求。
2. 场景
- Producer:App 把“订单信息”发给 Kafka,相当于你把快递寄到物流中心。
- Kafka 的 Topic:order-topic:这个订单被分类到“订单消息”区。
- Partition:订单多了后,这个 Topic 会分成多个窗口处理,比如根据用户 ID 对订单分区
- Broker:Kafka 的服务器节点,每台负责不同的分区。
- Offset:你的这单是这个窗口的第 88 单。
- Consumer Group:后台有多个系统来“收快递”:库存系统、配送系统、营销系统。它们是一个组,互不重复消费。
- Consumer:每个系统是一个消费者,读完这条消息就做对应操作。
3. 易混淆
3.1 消息是“推”还是“拉”?Kafka 是“拉模型”
含义:Kafka 的消费者(Consumer)不是被动接收消息,而是主动去 Kafka 拉(pull)消息
- Kafka 的“拉模型”:是消费者走到窗口主动要饭(拉消息)。
- RabbitMQ 的“推模型”:是服务端主动把饭端到你面前(推送消息)。
注意:必须写逻辑,让消费者“定期”去拉数据;否则,消息就永远躺在 Kafka 里没人处理。
| 模型 | 定义 |
|---|---|
| 推(Push)模型 | 服务器把消息主动发给消费者 |
| 拉(Pull)模型 | 消费者主动向服务器要消息 |
3.2 Kafka 消息是否会重复?是,有可能
Kafka 默认采用“至少一次”投递保证。
这意味着:一条消息可能被消费者读一次、也可能读两次甚至多次,但不会漏掉。
为什么会重复?比如:你读了消息;处理到一半系统崩了;Kafka 以为你没成功,就又让你读一次。
你需要在消费逻辑中加入“幂等性”处理:
幂等性:同一条消息处理多次,效果一样。
例如:拿订单 ID 做唯一判断;数据库先查有没有记录,有就跳过。
3.3 Kafka 是持久的吗?——是的,非常持久!
含义:Kafka 把消息写入磁盘文件中,不是内存里的临时数据。
- 默认情况下,Kafka 会把消息保留 7 天;
- 你也可以配置成:保留多久、保留多大、甚至永久保存。
举个例子:今天一个系统宕机了,明天才修好;没关系,它可以从 Kafka 中“回头”把几天前的消息重新拉回来处理。
好处:高可靠性;系统故障后能恢复;能做“离线分析”、“重放消息”等操作。
这三点对你今后写 Kafka 消费逻辑很重要,你需要理解它们背后的设计哲学:
高性能 + 高容错 + 自己负责可靠性
| 问题 | Kafka 策略 | 你要注意的地方 |
|---|---|---|
| 消息推还是拉 | 消费者主动拉(Pull) | 消费者自己决定拉的速度和频率 |
| 消息会不会重复 | 会,有可能重复 | 加幂等处理,避免重复消费 |
| 消息会不会丢失 | 不容易丢,写磁盘保留 | 默认 7 天,可配置更久 |
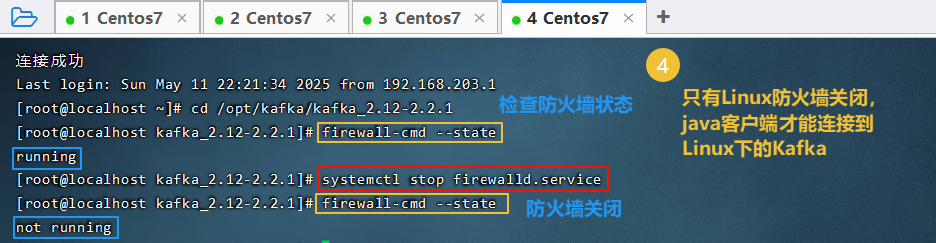
4. 安装
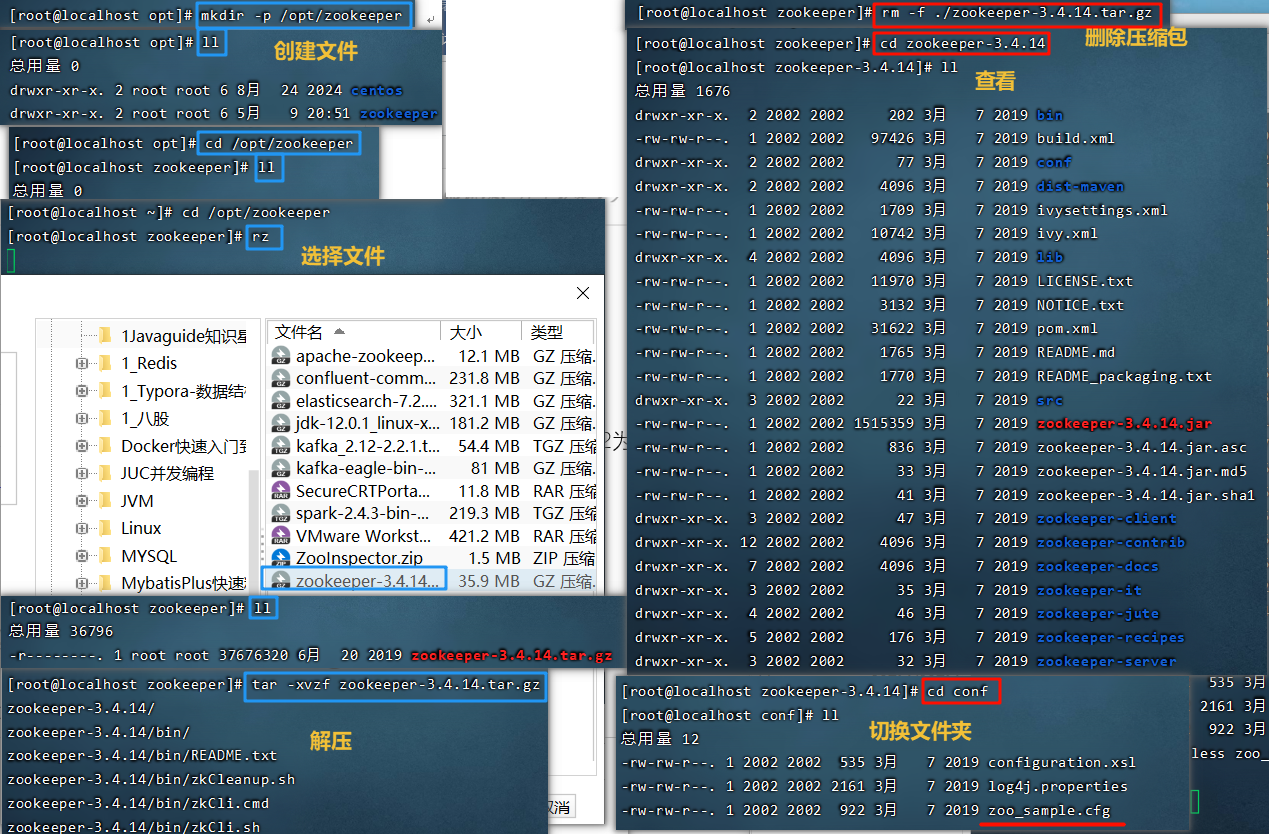
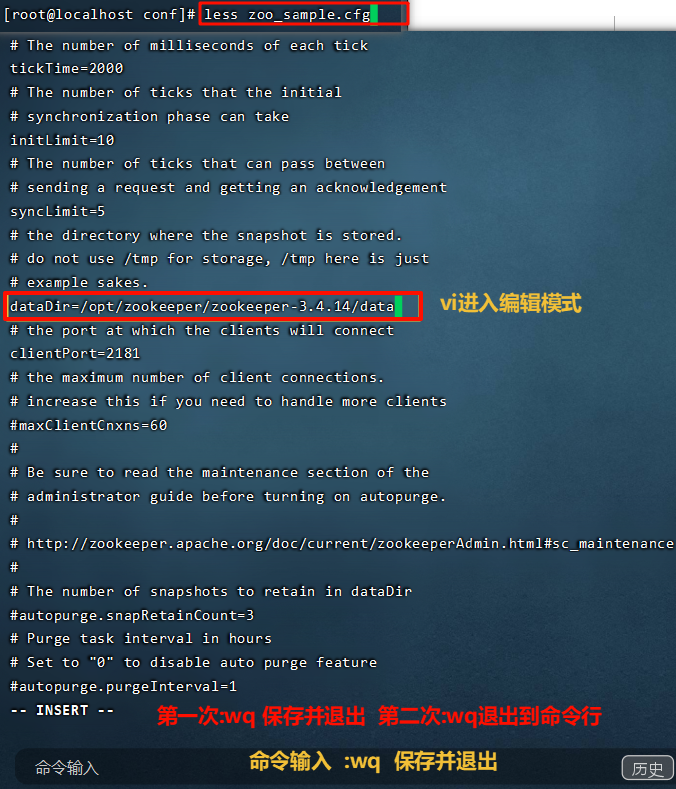
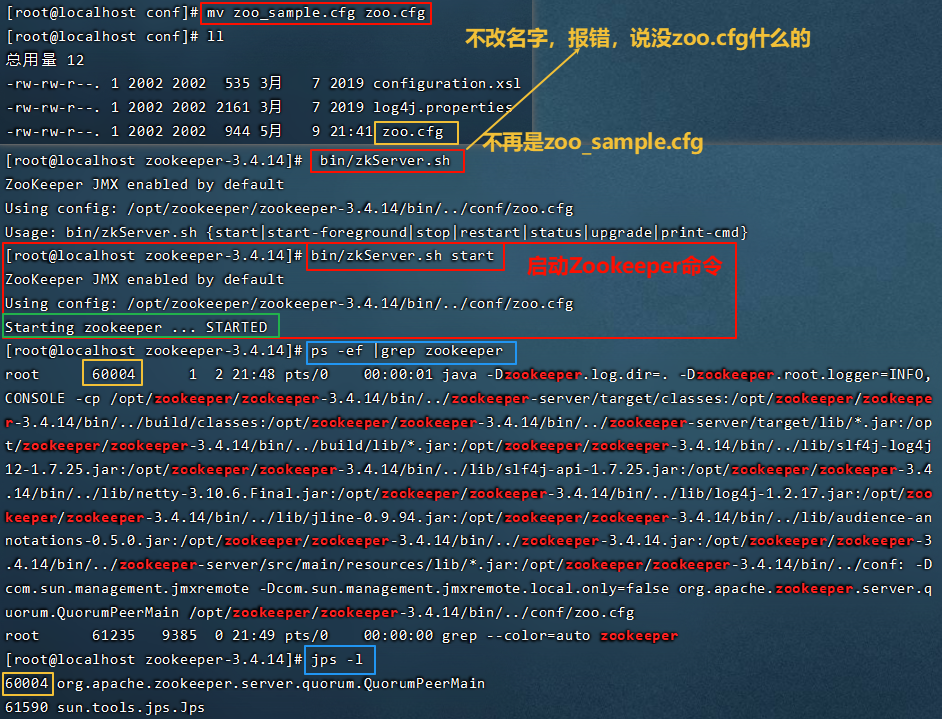
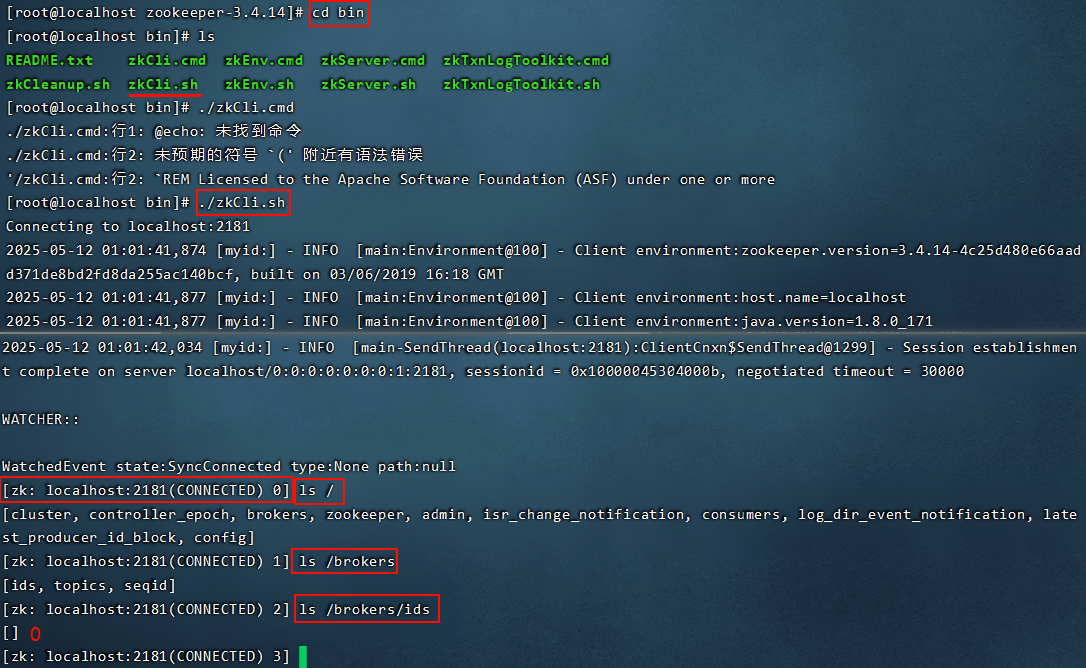
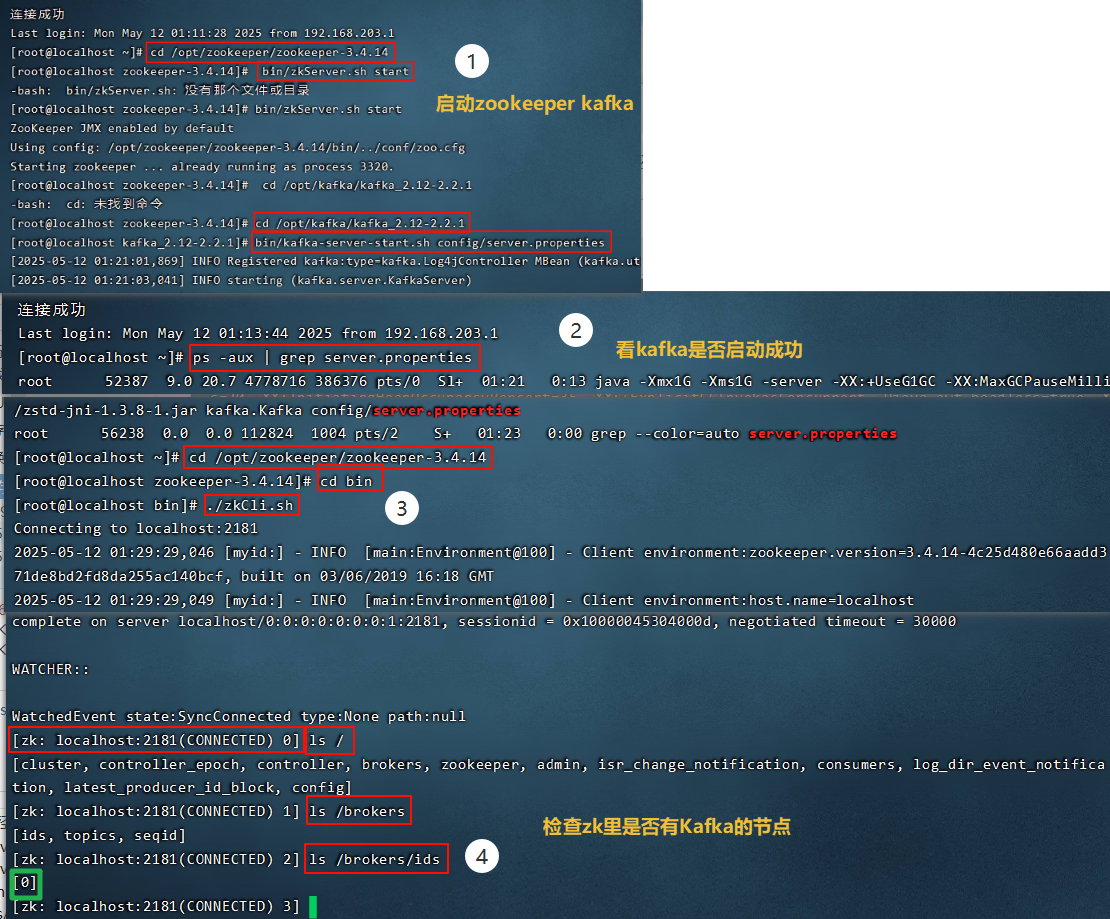
4.1 安装Zookeeper
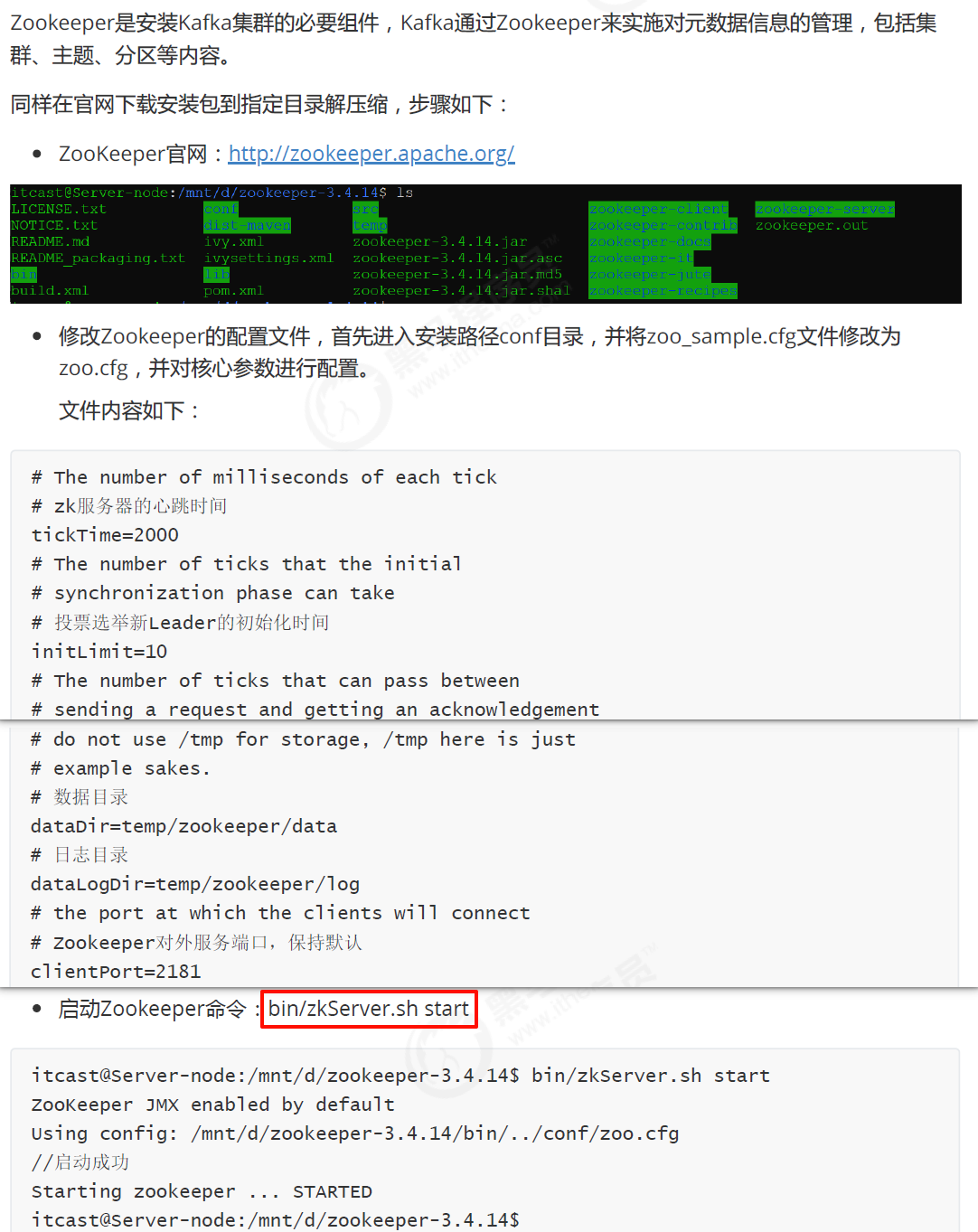
Zookeeper是安装Kafka集群的必要组件,Kafka通过Zookeeper来实施对元数据信息的管理,包括集群、主题、分区等内容。
1 | |
1 | |
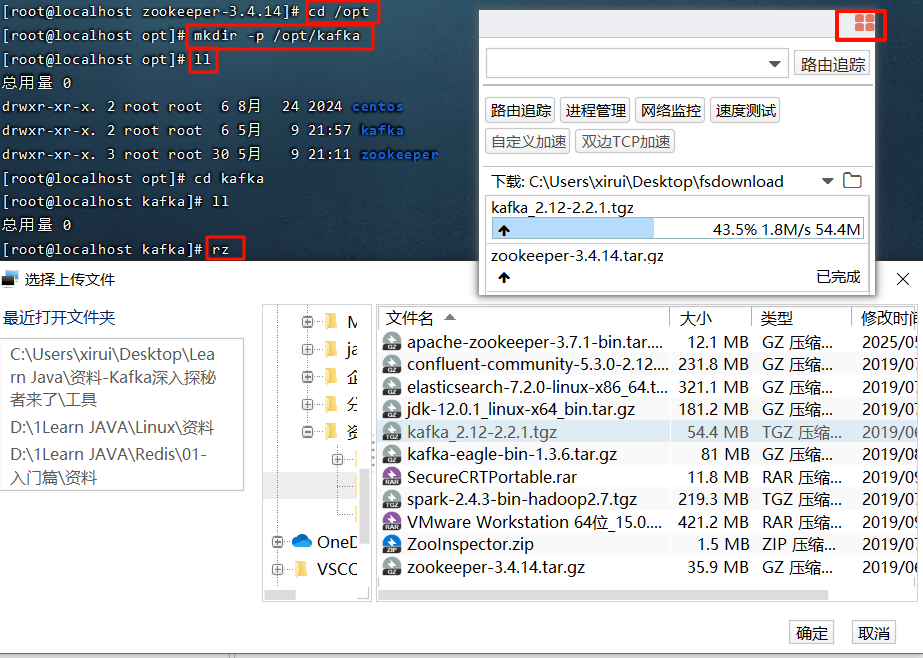
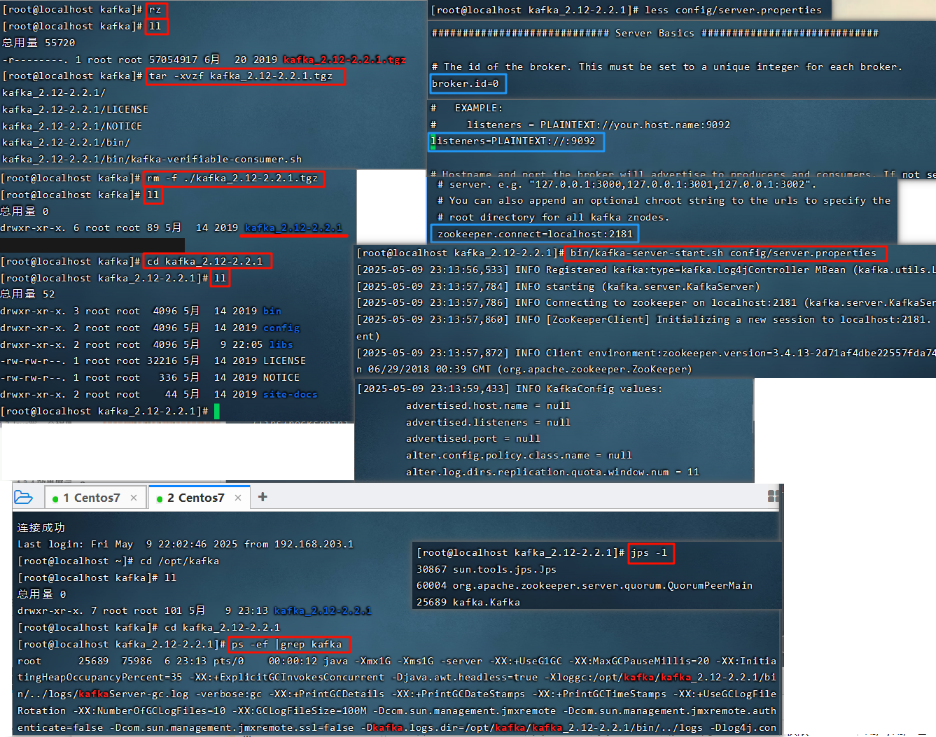
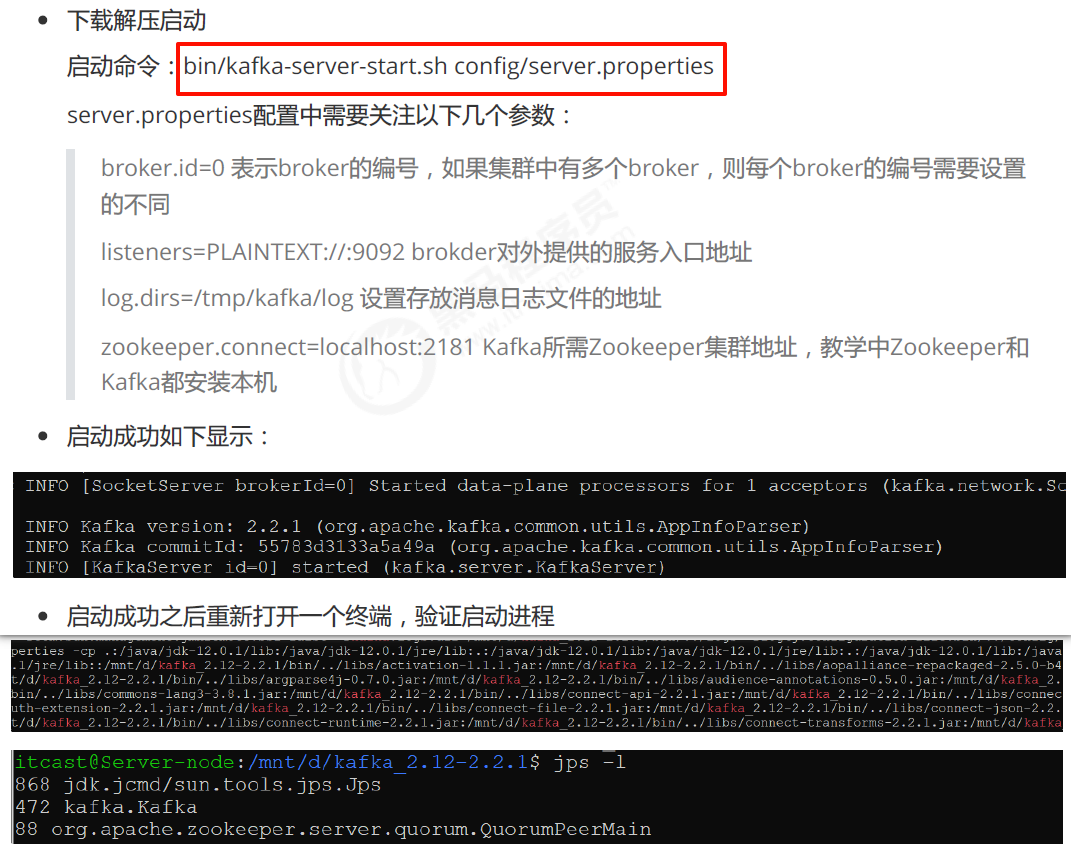
4.2 安装Kafka
1 | |
1 | |
1 | |
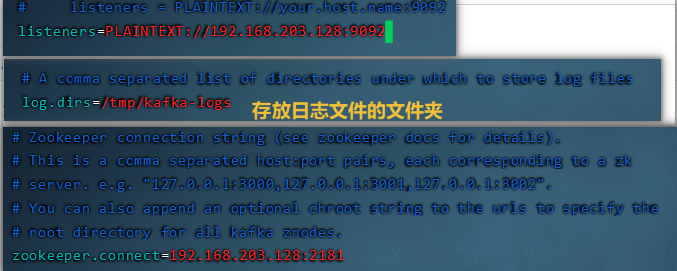
log.dirs= /tmp/kafka-logs

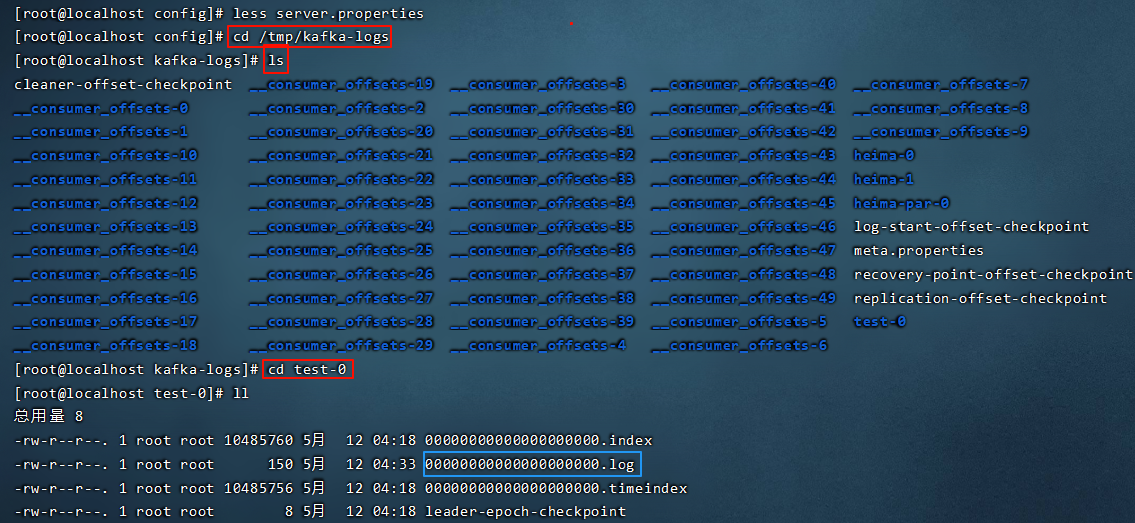
1 | |
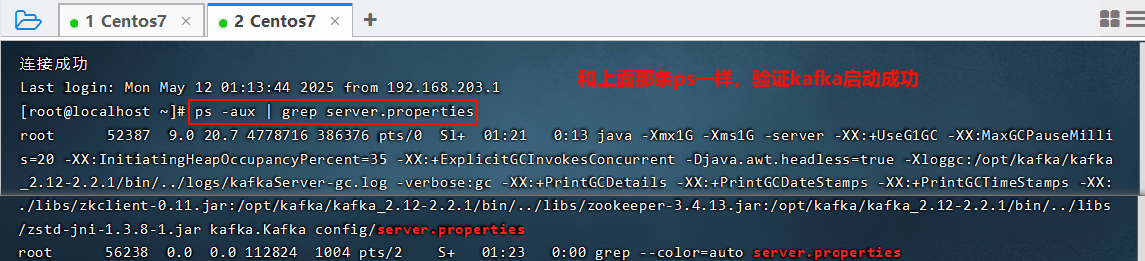
4.3 流程
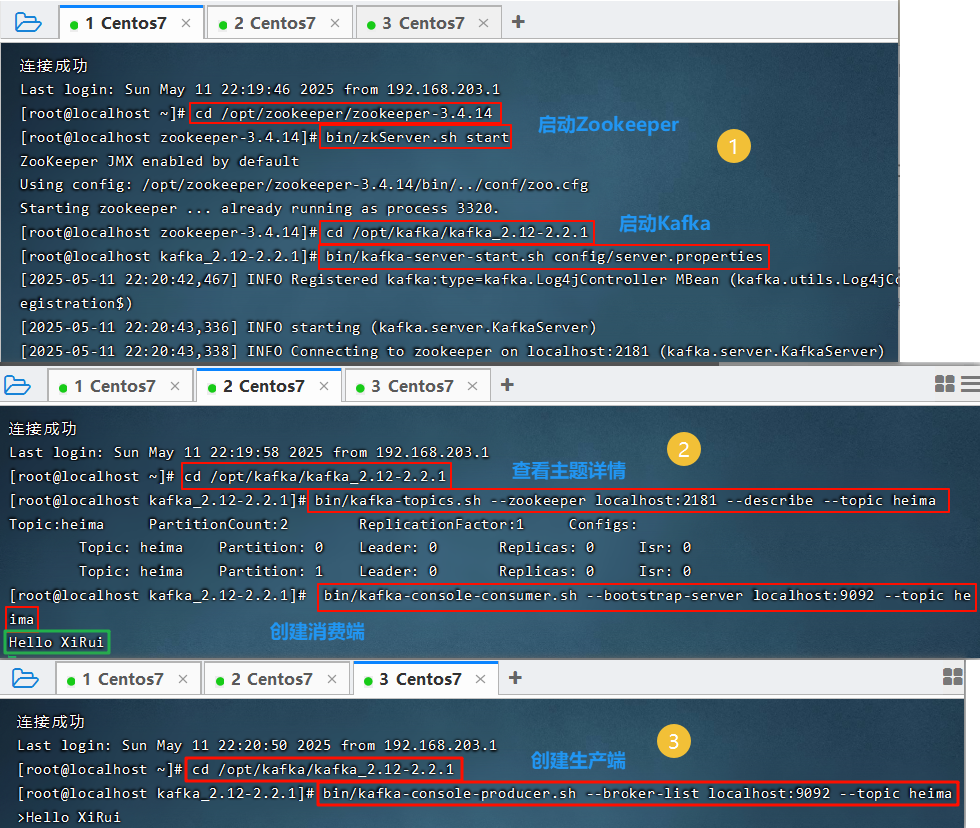
5. Kafka测试消息生产与消费
5.1 黑马2019
5.1.1 首先创建一个主题
1 | |
–zookeeper:指定了Kafka所连接的Zookeeper服务地址
–topic:指定了所要创建主题的名称
–partitions:指定了分区个数
–replication-factor:指定了副本因子
–create:创建主题的动作指令

5.1.2 展示所有主题
1 | |

5.1.3 查看主题详情
1 | |
–describe 查看详情动作指令

5.1.4 启动消费端接收消息
1 | |
–bootstrap-server 指定了连接kafka集群的地址
–topic 指定了发送消息时的主题
5.1.5 生产端发送消息
新开一个窗口 2Centos7
1 | |
–broker-list 指定了连接的Kafka集群的地址 –topic 指定了发送消息时的主题
Producer端

Consumer端

5.2 千峰
5.2.1 创建Topic
通过kafka命令向zk中创建⼀个主题
1 | |

查看当前zk中所有的主题
1 | |

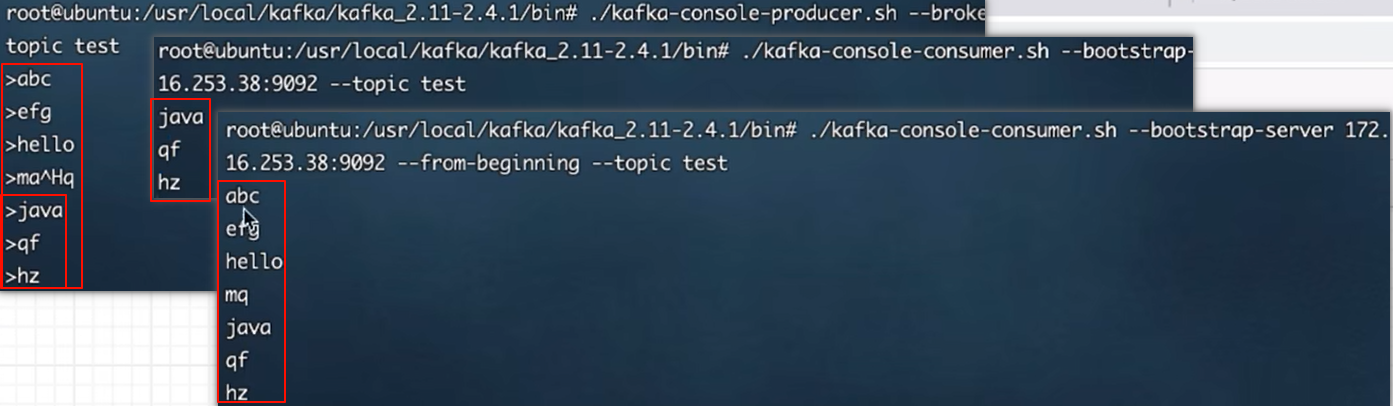
5.2.2 发送消息(producer)
把消息发送给broker中的某个topic,打开⼀个kafka发送消息的客户端,然后开始⽤客户端向
kafka服务器发送消息
1 | |

5.2.3 消费消息(consumer)
打开⼀个消费消息的客户端,向kafka服务器的某个主题消费消息
- ⽅式⼀:从当前主题中的最后⼀条消息的offset(偏移量位置)+1开始消费
1 | |

- ⽅式⼆:从当前主题中的第⼀条消息开始消费
1 | |
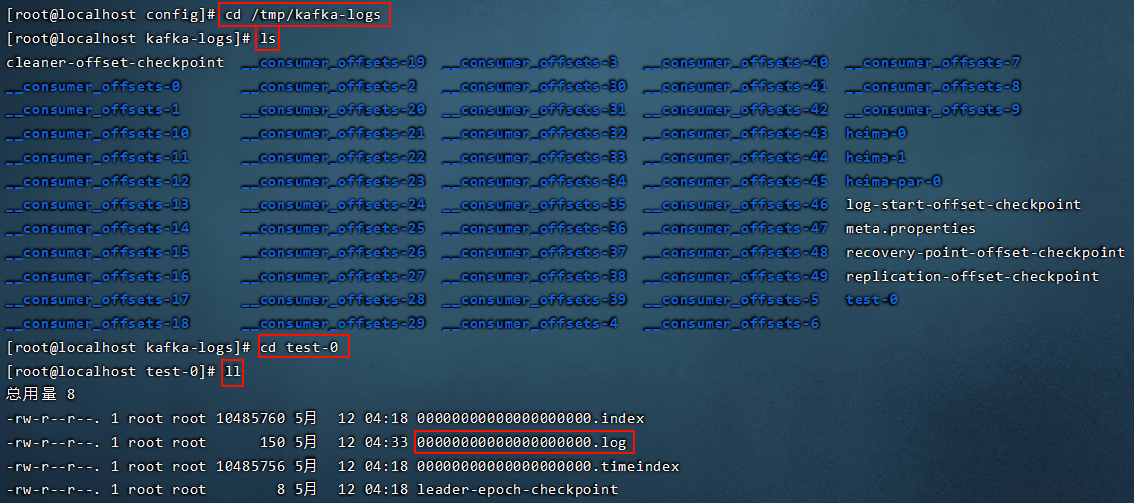

tmp是临时路径会定期清理
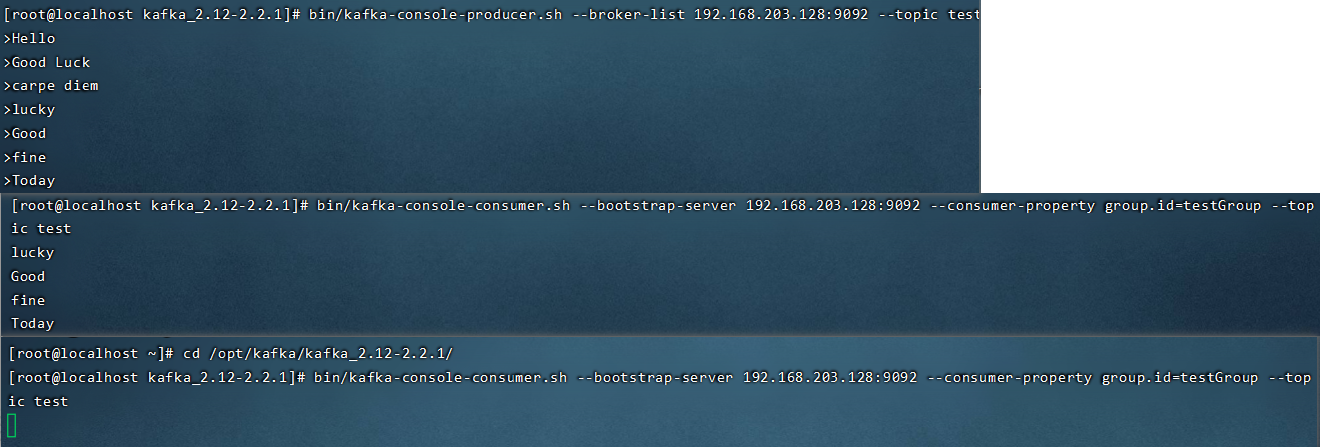
5.2.4 单播消息(消费者组)
单播消息:一个消费者组里只会有一个消费者能消费到某一个topic中的消息。于是可以创建多个消费者,这些消费者在同一个消费者组中。
在⼀个kafka的topic中,启动两个消费者,⼀个生产者,问:生产者发送消息,这条消息是否同时会被两个消费者消费?
如果多个消费者在同⼀个消费组,那么只有⼀个消费者可以收到订阅的topic中的消息。换言之,同⼀个消费组中只能有⼀个消费者收到⼀个topic中的消息。
配一个消费者组:
1 | |
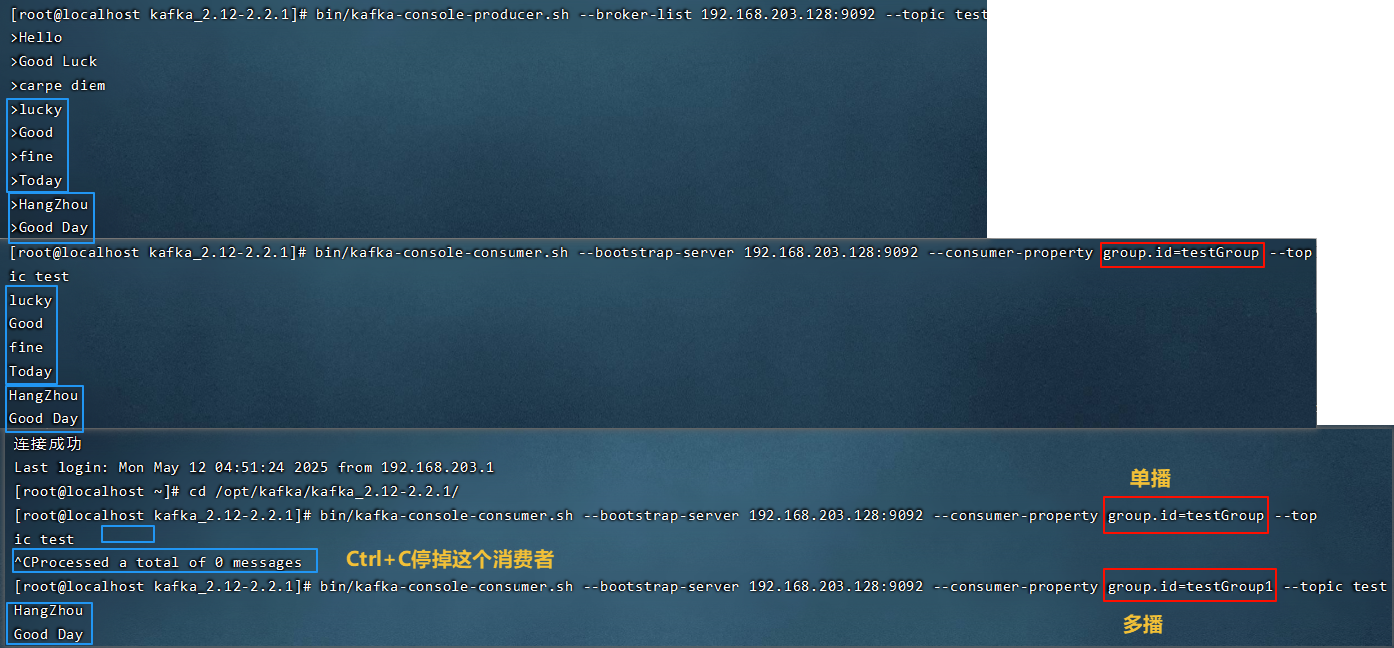
5.2.5 多播消息(多个消费组)
在一些业务场景中需要让一条消息被多个消费者消费,那么就可以使用多播模式。
不同的消费组订阅同⼀个topic,那么不同的消费组中只有⼀个消费者能收到消息。实际上也
是多个消费组中的多个消费者收到了同⼀个消息。
1 | |
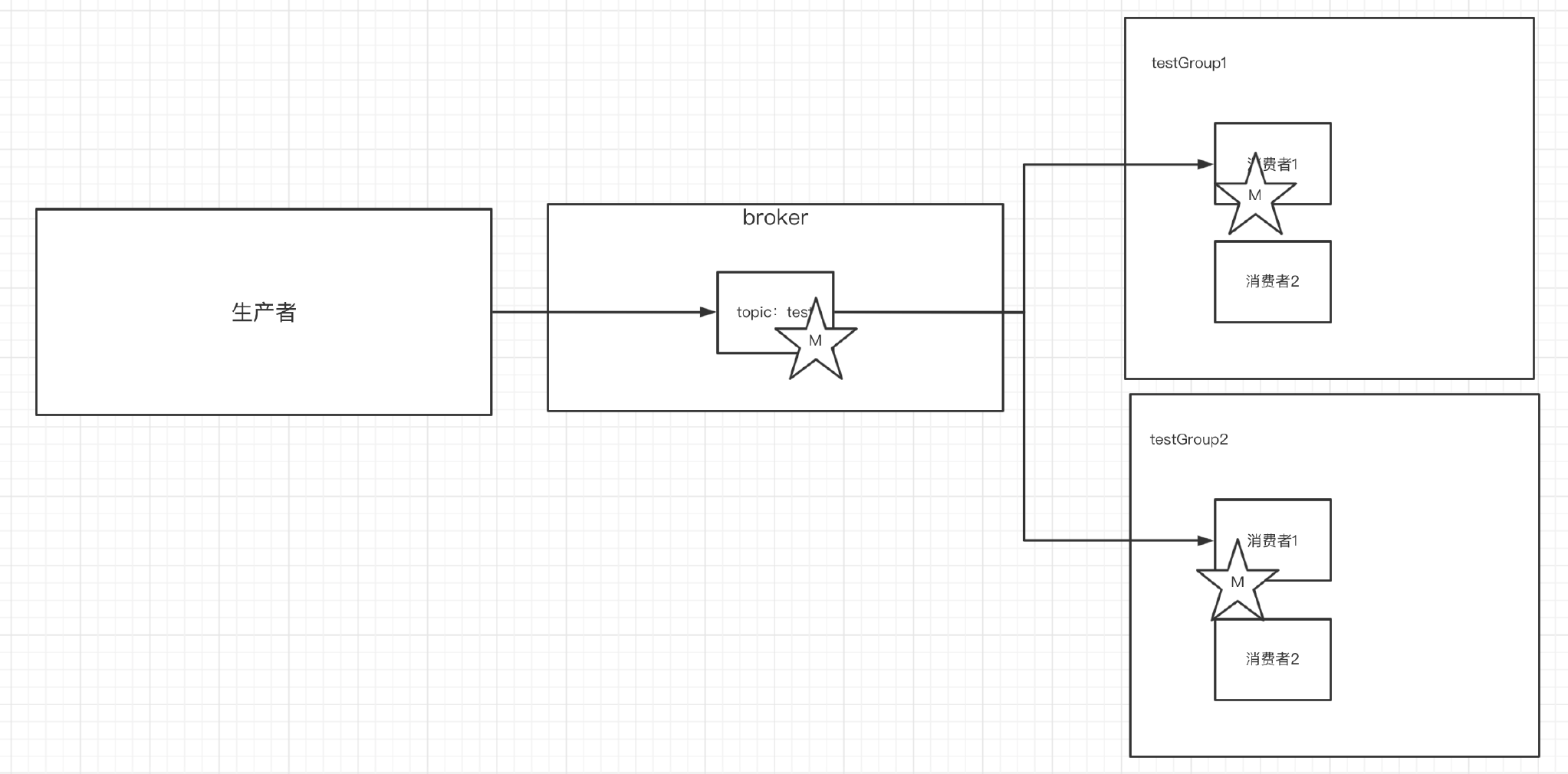
下图就是描述多播和单播消息的区别:
不同Group里的消费者能收到消息,但一个Group里只有一个消费者能收到。
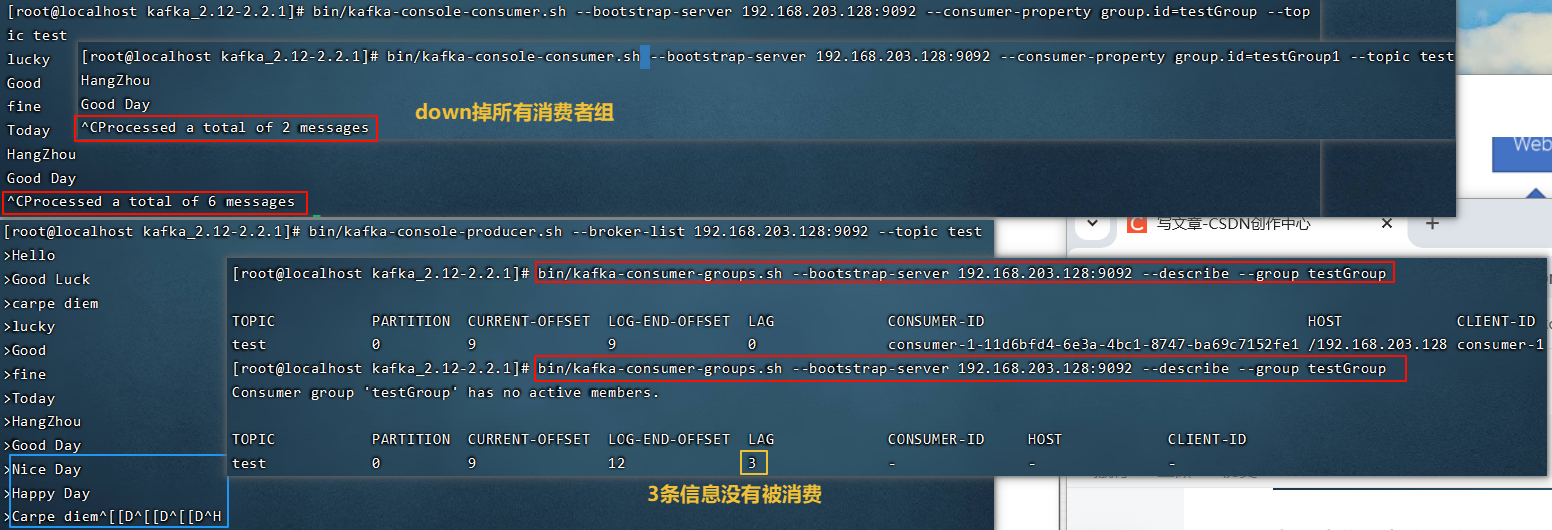
5.2.6 查看消费者组的详细信息
查看当前主题下有哪些消费者组:
1 | |

查看消费组中的具体信息:
比如当前偏移量、最后⼀条消息的偏移量、堆积的消息数量:
1 | |

Currennt-offset: 当前消费组的已消费偏移量(最后被消费的消息的偏移量)
Log-end-offset: 主题对应分区消息的结束偏移量(最后⼀条消息的偏移量)
Lag: 当前消费组未消费的消息数(积压了多少条消息)
6. Kafka中主题和分区的概念
6.1 主题Topic
- kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费。
- 但有⼀个问题,如果这个topic中的消息非常非常多,消息又会被保存到log日志文件中。
- 为了解决这个文件过大的问题,kafka提出了Partition分区的概念。
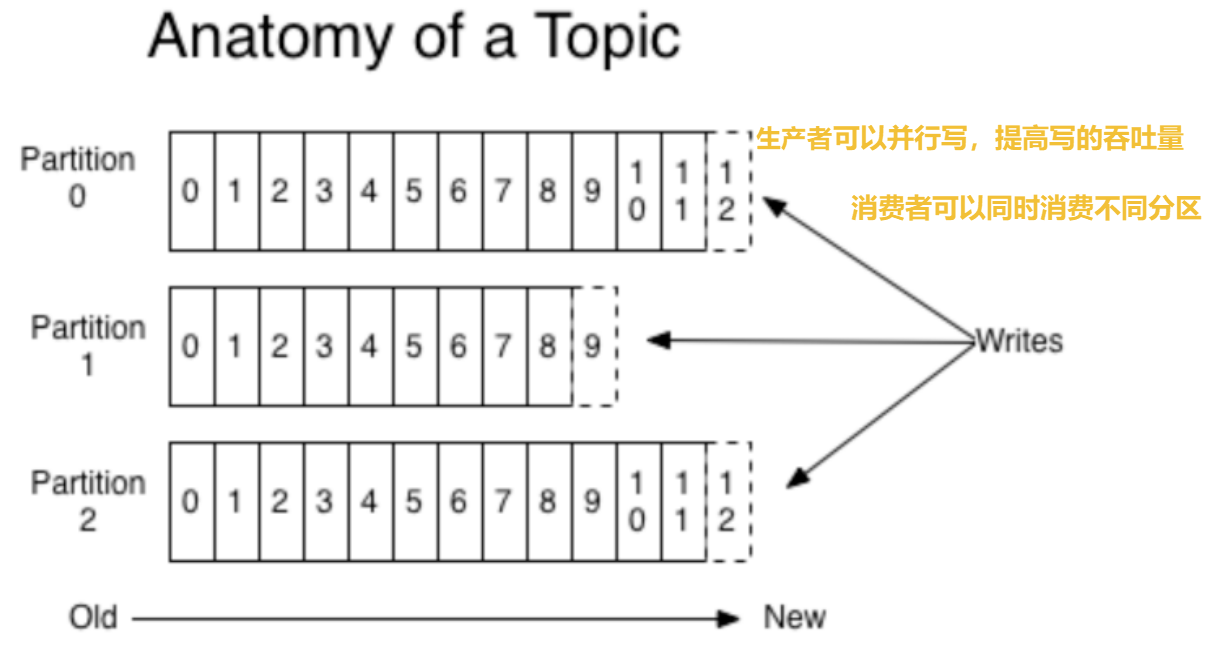
6.2 分区Partition
6.2.1 分区的概念
通过partition将⼀个topic中的消息分区来存储。这样的好处有多个:
- 分区存储,可以解决统⼀存储文件过大的问题
- 提供了读写的吞吐量:读和写可以同时在多个分区中进行
比如⼀个topic创建了3个分区。那么topic中的消息就会分别存放在这三个分区中。
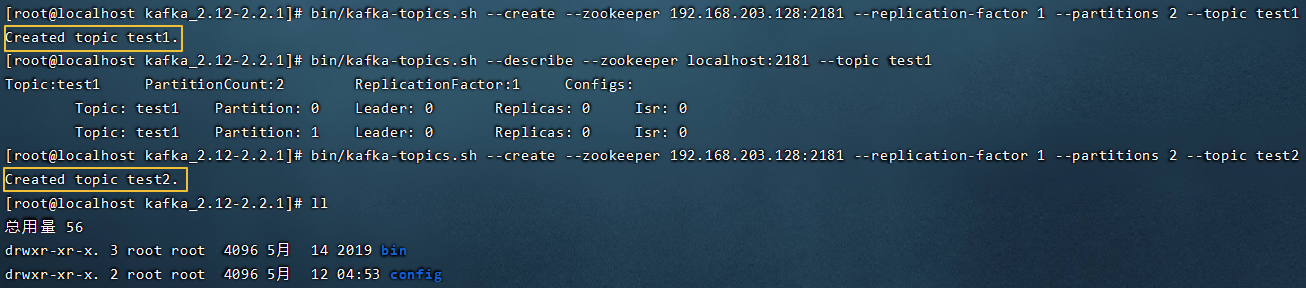
6.2.2 创建多分区的主题
1 | |

查看topic的分区信息
1 | |

6.3 kafka中消息日志文件中保存的内容
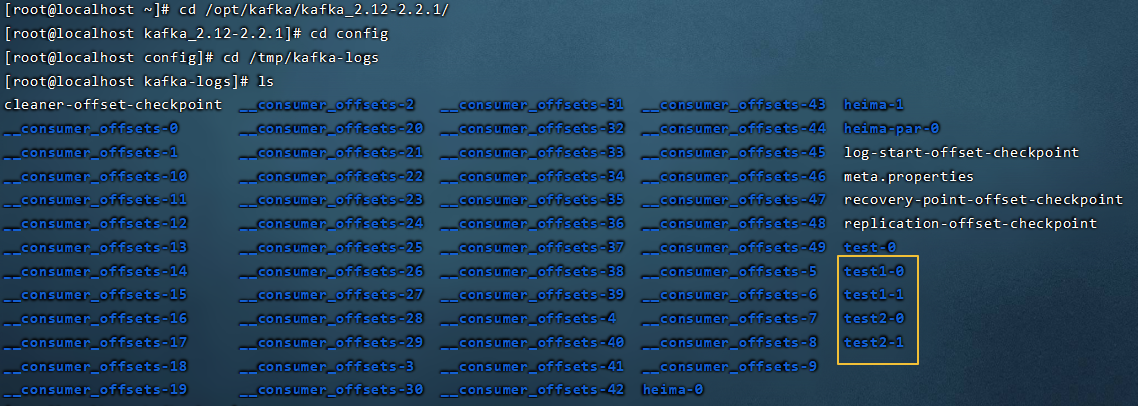
实际上是存在/tmp/kafka-logs/test-1 和 test-2中的0000000.log文件中
00000000.log: 这个文件中保存的就是消息。
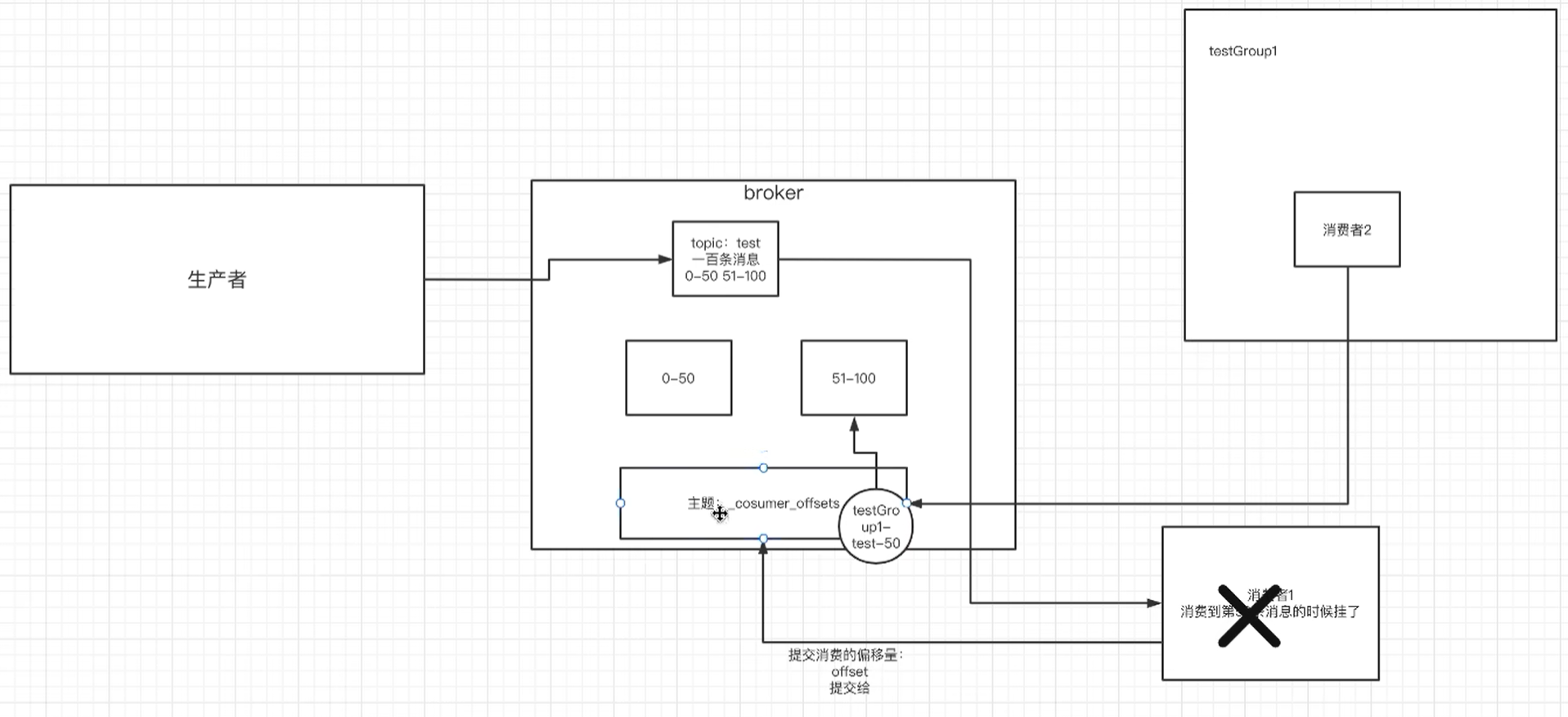
__consumer_offsets-49:
- kafka内部自己创建了**_consumer_offsets主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量**。
- 每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区。
- 提交到哪个分区:通过hash函数:hash(consumerGroupId) % _consumer_offsets
- 主题的分区数
提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前offset的值文件中保存的消息,默认保存7天。七天到后消息会被删除。
7. Kafka集群操作
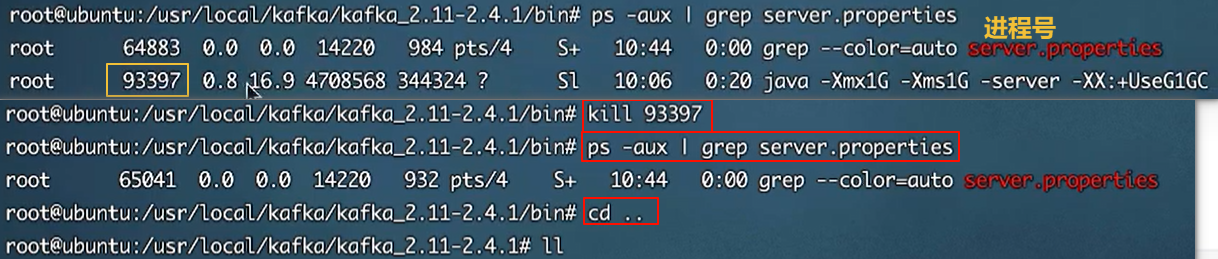
7.1 搭建kafka集群(三个broker)
关闭(kafka)

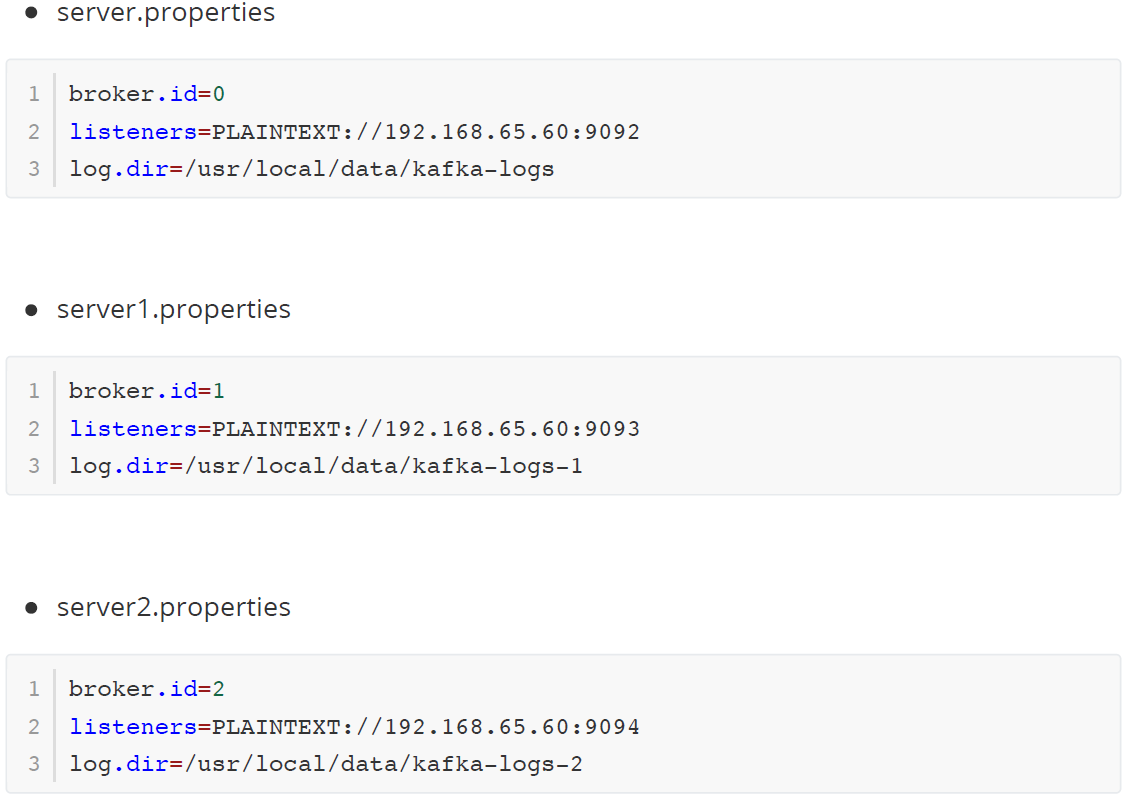
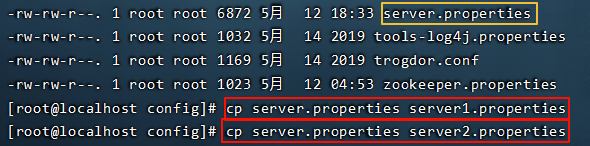
准备3个server.properties文件,每个文件中的这些内容要调整
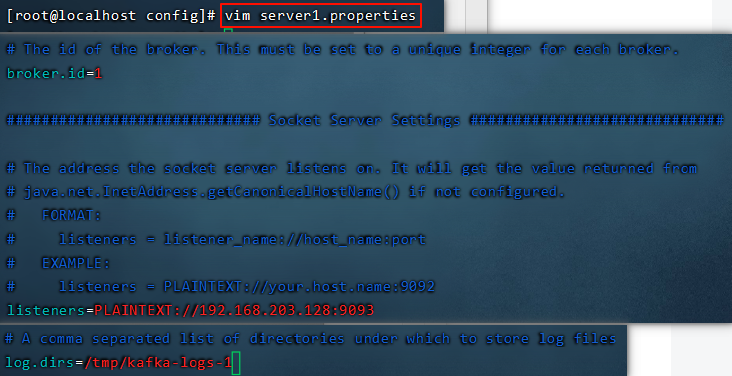
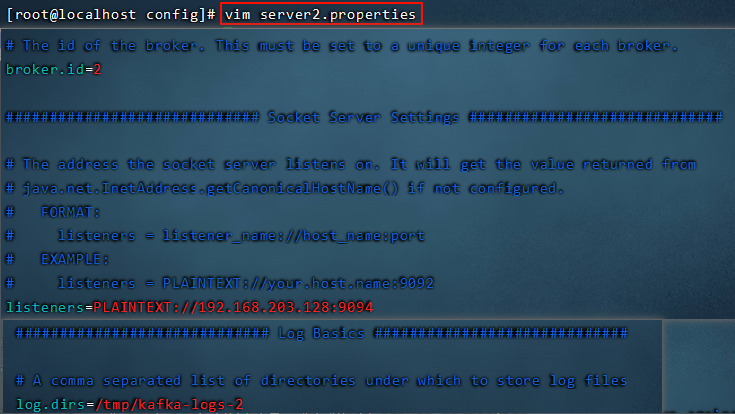
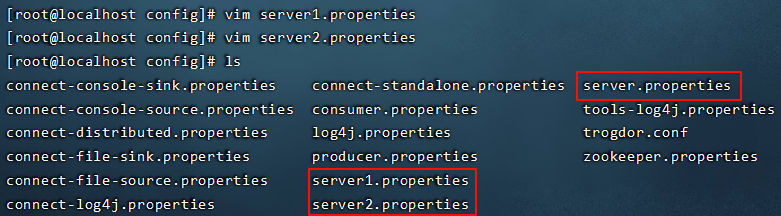
使用如下命令来启动3台服务器
1 | |
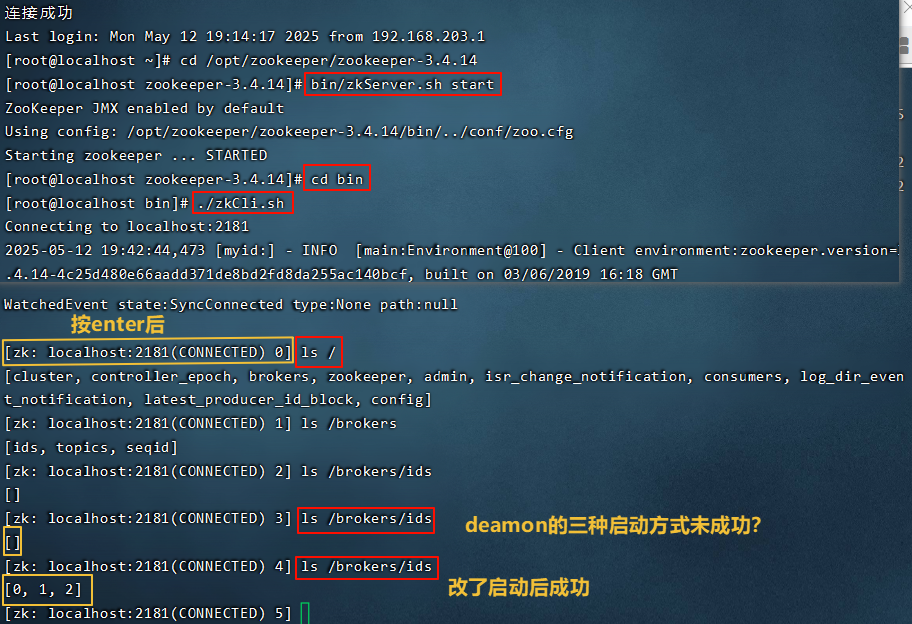
不知道为什么用下面这种方式启动不行,可能是没启动成功?
bin/kafka-server-start.sh -daemon ../config/server.properties
bin/kafka-server-start.sh -daemon ../config/server1.properties
bin/kafka-server-start.sh -daemon ../config/server2.properties
启动服务器
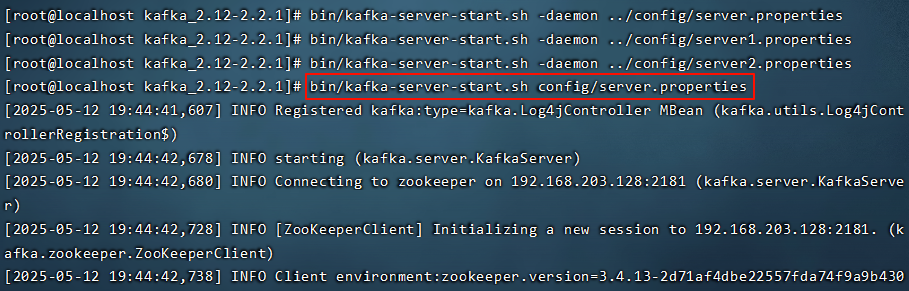
搭建完后通过查看zk中的/brokers/ids 看是否启动成功
7.2 副本的概念
副本是对分区的备份。在集群中,不同的副本会被部署在不同的broker上。
- 集群中有多个broker,
- 创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),
- 可以为分区创建多个副本,不同的副本存放在不同的broker里。
下面例子:创建1个主题,2个分区、3个副本。
1 | |
查看主题topic的详细信息
1 | |
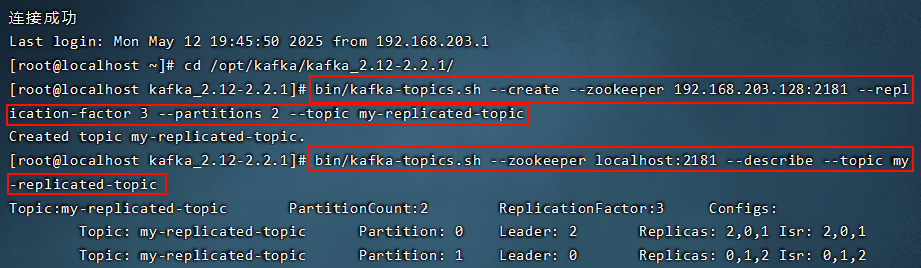
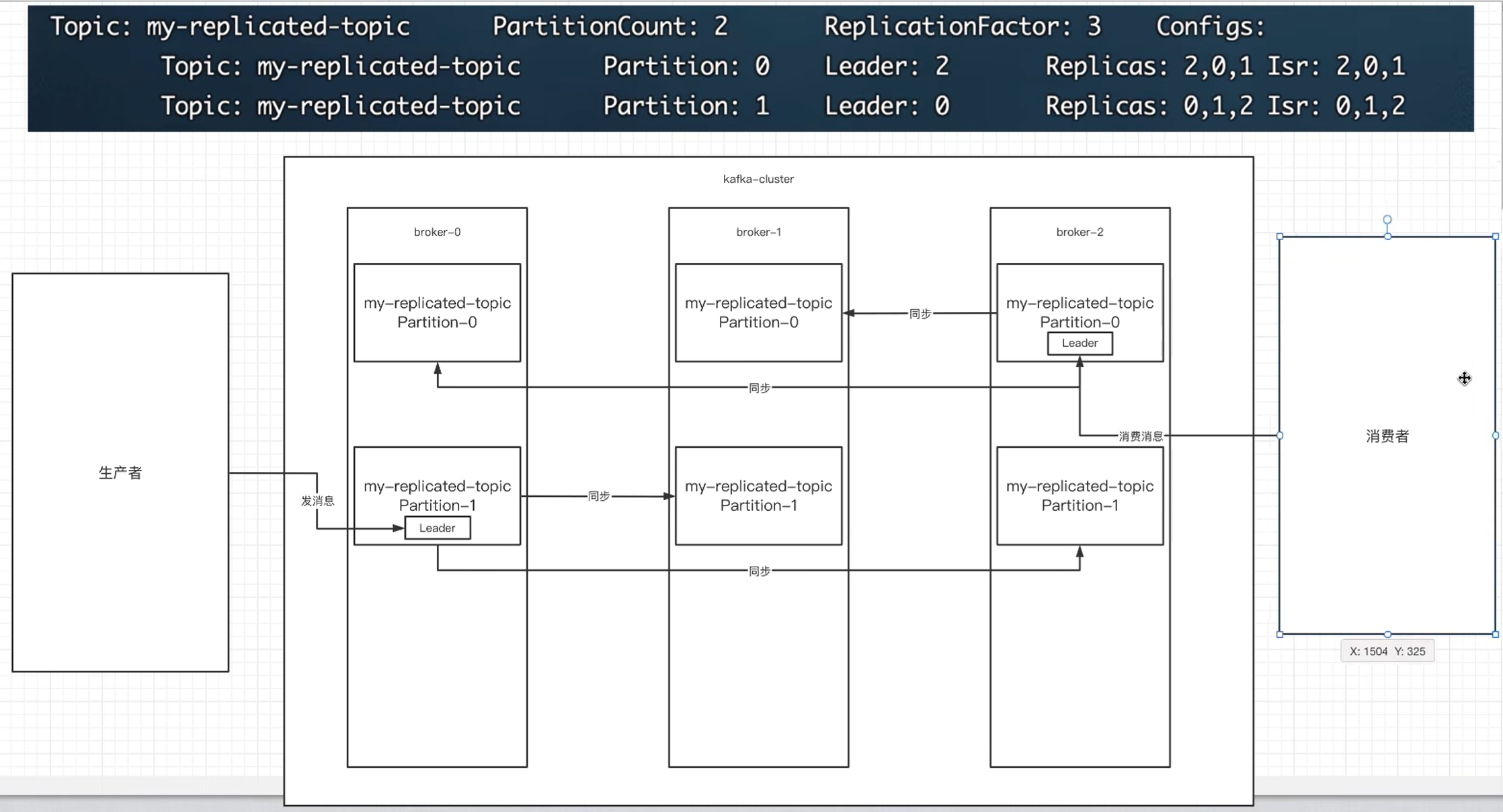
通过查看主题信息,其中的关键数据:
- leader:副本里的概念
每个 partition 都有⼀个 broker 作为 leader。
leader处理所有针对这个partition的读写请求。
leader负责把数据同步给follower。
当leader挂了,经过主从选举,从多个 follower 中选举产生⼀个新的 leader。- follower
follower通过 poll 的方式接收leader的同步的数据。不提供读写。- replicas:
当前副本存在的broker节点。- isr:
可以同步和已同步的节点会被存入 isr 集合中。这里有⼀个细节:如果isr中的节点性能较差,会被提出isr集合。
7.3 向集群发送消息
1 | |

7.4 从集群中消费消息
1 | |

7.5 指定消费组来消费消息
1 | |
7.6 关于分区消费者组消费者的细节
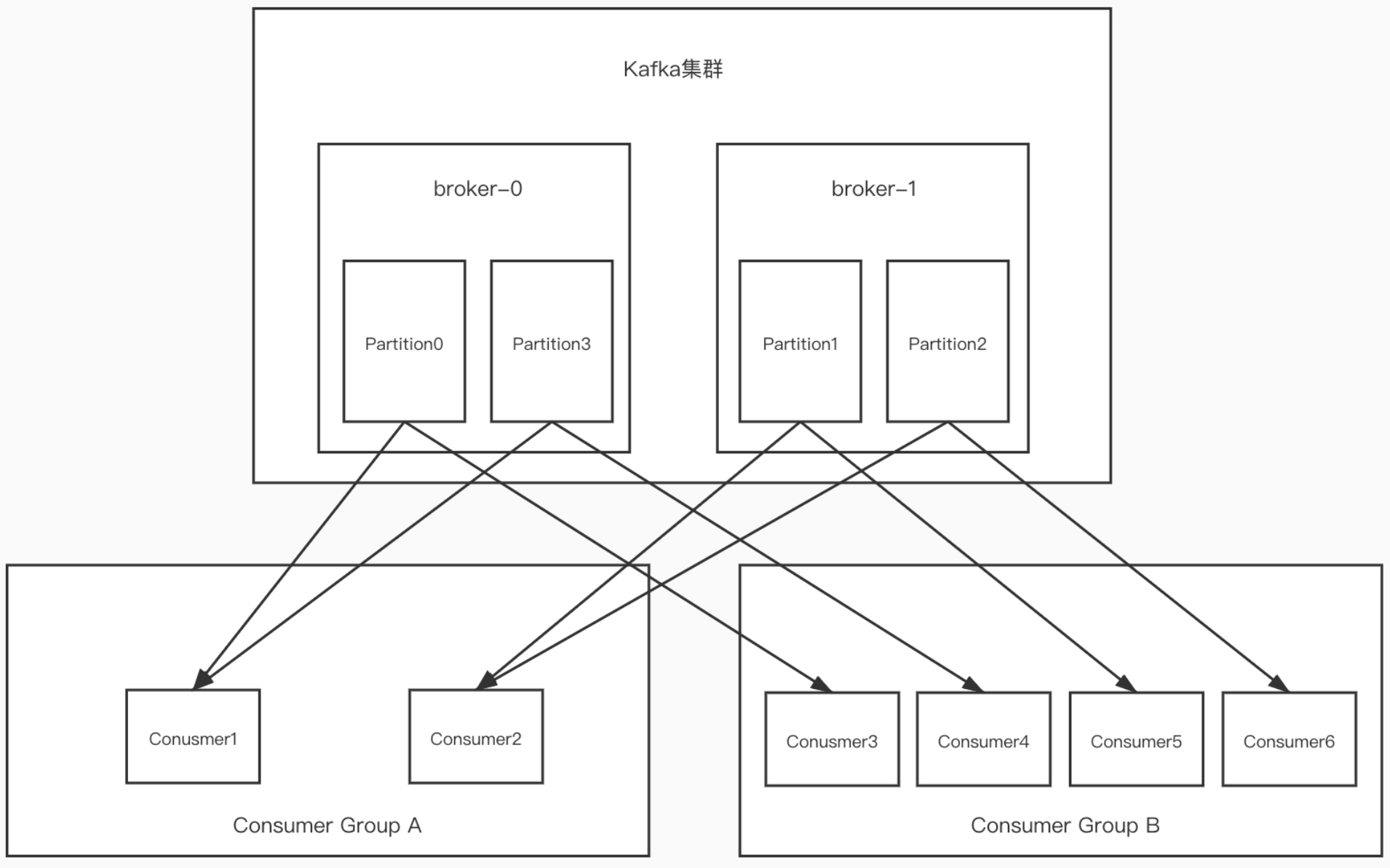
- 一个partition只能被一个消费组中的一个消费者消费,目的是为了保证消费的顺序性,但是多个partion的多个消费者消费的总的顺序性是得不到保证的。
- partition的数量决定了消费组中消费者的数量,建议同⼀个消费组中消费者的数量不要超
过partition的数量,否则多的消费者消费不到消息。- 如果消费者挂了,那么会触发rebalance机制(后面介绍),会让其他消费者来消费该分
区。