并发编程JUC
1. 线程的基础知识
1.0⭐️多线程的应用
- 异步处理,提高响应速度
比如用户下订单后,主线程返回结果,而用子线程异步发送短信、写日志、更新库存。- 并行任务,加快处理速度
比如大数据处理、批量计算时,将任务拆成多份交给多个线程并行处理,比串行快很多- 定时/后台任务调度
比如定时刷新缓存、定期拉取消息、后台数据清洗等。
1.1⭐️线程和进程的区别?
线程和进程的主要区别在于资源和调度方式。
- 进程是资源分配的最小单位,每个进程都有自己独立的内存空间。比如我们运行一个程序时,系统会创建一个进程来加载程序的代码、数据,并管理内存、IO等资源。
- 线程是CPU调度的最小单位,线程是在进程内部执行指令的。一个进程可以有多个线程,这些线程共享进程的内存和资源,通信效率高,但也容易出现线程安全问题。
1.2⭐️⭐️并行和并发区别?
- 并发是指同一时间段内,有多个任务在交替执行,看起来是同时进行的。比如单核 CPU 上的多任务,就是通过时间片切换实现的。
- 并行是真正的同时执行,依赖多核 CPU。比如一个四核 CPU,可以同时跑四个线程。
1.2⭐️⭐️同步异步区别?
- 同步:一个任务执行完,才能继续下一个任务。就像排队取快递,你要等前面的人办完事。
- 异步:任务可以发起后,不必等待立即返回,等完成了再通知。比如点外卖,下单后不用等,可以去做别的事,送达时会提醒你。
区别:
- 同步是阻塞式的,调用方需要等待任务完成才能继续;
而异步是非阻塞式的,调用方无需等待任务完成即可继续执行。- 同步直接返回任务的结果,调用方可以直接使用;
而异步通常通过回调函数、事件通知或 Future 对象等方式传递结果。- 同步适合简单、短时间的任务,或者需要立即获取结果的场景;
而异步适合需要提高系统吞吐量的场景,或者用于耗时较长的任务,如网络请求、文件读写等。
1.2⭐️什么是线程上下文切换?
- 上下文切换是指 CPU 从一个线程转到另一个线程时,需要保存当前线程的上下文状态,恢复另一个线程的上下文状态,以便于下一次恢复执行该线程时能够正确地运行。
- 这些状态包括程序计数器、寄存器、变量等,操作系统会把它们保存到线程的上下文中,所以叫“上下文切换”。
- 多线程的上下文切换的开销比直接用单线程大,因为在多线程中,需要保存和恢复更多的上下文信息。过多的上下文切换会降低系统的运行效率,因此需要尽可能减少上下文切换的次数。
1.2⭐️什么时候会发生线程上下文切换?
- 时间片耗尽:CPU 为每个线程分配时间片,时间用完后,操作系统调度器会强制切换到其他线程;
- 主动让出 CPU:线程调用
sleep()、wait()等方法放弃CPU使用权- 加锁/解锁:线程获取不到锁就会被挂起,切换给别的线程;
- 高优先级任务抢占:当高优先级线程就绪时,低优先级线程会被中断并切换。
1.2⭐️如何减少上下文切换?
- 减少线程数量:线程过多会增加切换频率;
- 减少锁竞争:尽量使用无锁数据结构、CAS 操作,或者减小锁粒度;减少线程在加锁过程中的挂起和唤醒;
- 使用线程池:避免频繁创建和销毁线程,复用线程;
- 避免频繁阻塞/唤醒:比如不要频繁用 wait/notify,少用 sleep() 模拟;
1.3⭐️⭐️⭐️创建线程的四种方式
在java中一共有四种常见的创建方式,分别是:继承Thread类、实现runnable接口、实现Callable接口、线程池创建线程。通常情况下,我们项目中都会采用线程池的方式创建线程。
继承Thread类
- 创建类继承Thread,重写其 run() 方法
- 调用 start() 方法启动线程。
- 由于 Java 不支持多重继承,因此限制了类的扩展性。
实现runnable接口
- 创建一个类实现Runnable接口,重写run()方法。
- 将该对象传入Thread构造器,调用start()方法启动线程。
- 不受继承限制,灵活,推荐使用。
实现Callable接口 + FutureTask
- 实现 Callable 接口,重写 call() 方法(有返回值,可以抛异常)。
- 使用 FutureTask 包装 Callable 对象,再交给 Thread 执行。
- 可以通过 FutureTask.get() 获取执行结果或异常。
线程池创建线程
- 通过 ExecutorService 创建线程池。
- 通过 submit() 或 execute() 方法提交任务,避免频繁创建和销毁线程的开销。
- 避免频繁创建和销毁线程,资源可控,最常用。
详细创建方式参考下面代码:
① 继承Thread类
1 | |
② 实现runnable接口
1 | |
③ 实现Callable接口
1 | |
④ 线程池创建线程
1 | |

1.4 runnable 和 callable 有什么区别
参考回答
返回值:
- Runnable 的
run()没有返回值。- Callable 的
call()有返回值。异常处理:
- Runnable 里的异常必须 try-catch 处理,不能抛出。
- Callable 的
call()可以throws Exception,抛出给调用者处理。配合类:
- Runnable 直接交给 Thread 执行。
- Callable 需要
FutureTask或线程池的submit()才能执行,并能拿到返回结果。向上抛异常就是throws exception,内部消化指的是可以用try catch
1.5 线程的 run()和 start()有什么区别?
- 调用start()方法会启动一个新的线程,由Java虚拟机调用run()方法,线程开始异步执行
- 如果直接调用run()方法,它就像是一个普通方法调用,不会启动新线程,而是由当前线程顺序执行。
- 所以,要启动线程,一定要用start()方法,不能直接调用run(),否则就失去了多线程的意义。
1.6 ⭐️⭐️⭐️线程包括哪些状态,状态之间是如何变化的?

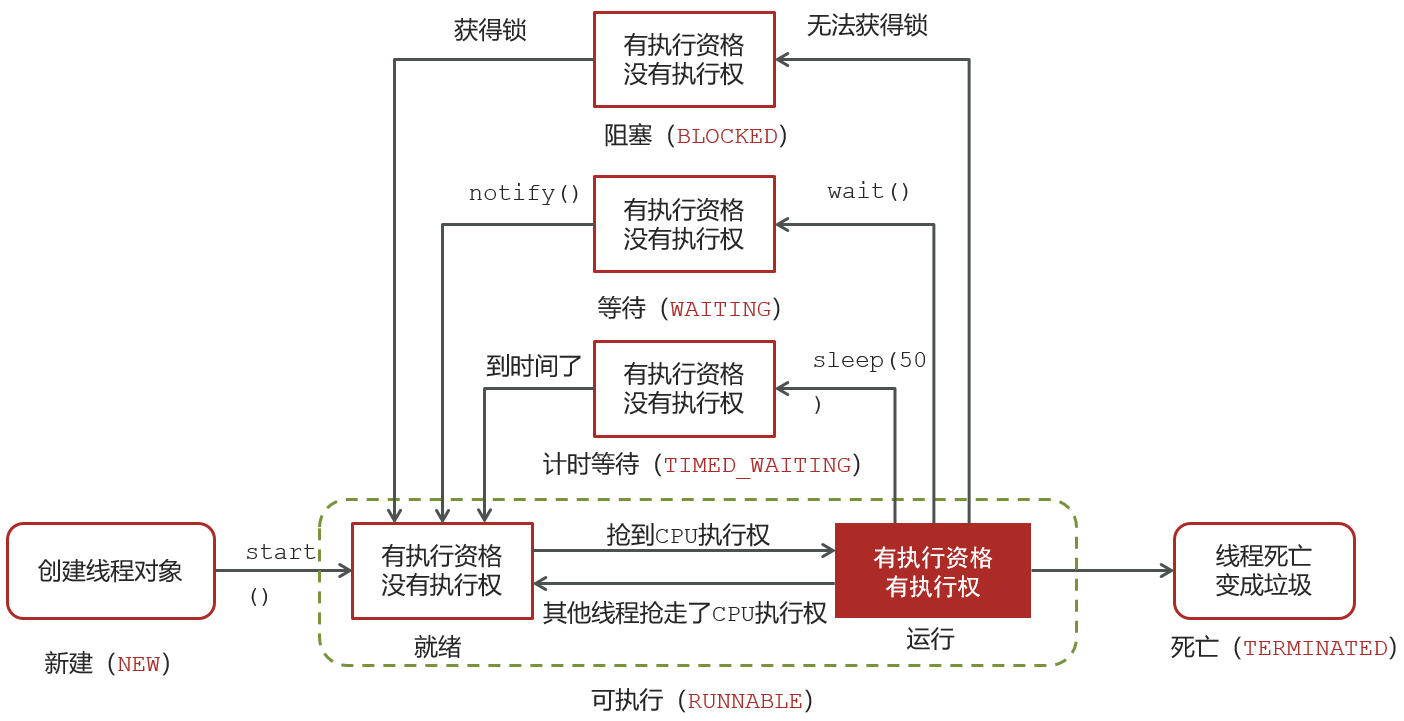
1.7 新建 T1、T2、T3 三个线程,如何保证它们按顺序执行?
- 可以的。有几种方法,比如最简单的就是使用 join() 方法。
- 在一个线程中启动另一个线程,另外一个线程完成,该线程继续执行。
- 我们可以让 T2 启动后调用 T1.join(),然后 T3 启动后调用 T2.join(),这样就能保证 T1 最先执行,T3 最后执行。
1.8 notify()和 notifyAll()有什么区别?
知道的。
- notifyAll() 会唤醒所有在等待的线程,
- 而 notify() 只会随机唤醒一个等待的线程。
1.9 在 Java 中 wait 和 sleep 方法的不同?
- 它们都可以让线程暂停,但不一样。
- sleep() 是 Thread 的方法,让线程暂停指定时间,但不会释放锁;
- wait() 是 Object 方法,必须在同步块里使用,会释放锁,等待notify()或notifyAll()唤醒。
简单来说,sleep() 是自己睡觉,锁还在手上;wait() 是放下锁,等别人叫醒你。
当面试题里说 wait() 必须在同步块里使用,它指的是:
wait() 是 Object 类的方法,它需要当前线程 持有对象的锁 才能调用。
如果你在没有获取锁的情况下调用 wait(),Java 会抛出异常 IllegalMonitorStateException。
举个例子:Object lock = new Object();
// 错误示例
lock.wait(); // 会报错,因为当前线程没有锁
// 正确示例
synchronized(lock) { // 这里是同步块,获取了lock对象的锁
lock.wait(); // 可以安全调用
}
所以所谓“必须在同步块里使用”,就是调用 wait() 前必须先获得这个对象的锁。

1.10 如何停止一个正在运行的线程?
有三种方式可以停止线程
- 不推荐用 stop() 方法来停止线程,因为它不安全,会造成资源状态不一致。
- 标志位法
- 定义一个 volatile boolean flag,线程在循环里不断检查这个变量。
- 外部线程把 flag 改为 false,线程就安全退出。
- interrupt() 方法
- 如果线程在 sleep、wait、join,会抛出异常 InterruptedException。
- 正常线程可以通过 isInterrupted() 检查中断标志安全退出。
volatile boolean running = true;
while(running) { // 执行任务 }
public void stopThread() { running = false; }
2. 线程中并发锁
2.0⭐️⭐️⭐️乐观锁和悲观锁的使用场景
乐观锁(Optimistic Lock):
- 持乐观态度,认为并发冲突很少发生,所以不加锁,更新时再校验“别人有没有改过”。
- 常见是 版本号机制、CAS(compare and swap)操作。
应用场景
- 读多、写少,冲突少的场景
- 高并发访问下,减少锁竞争,提高性能
- 数据一致性允许通过重试机制处理少量冲突
- 例如:点赞数、阅读量统计、配置类数据更新。
悲观锁(Pessimistic Lock):
- 持悲观态度,认为并发冲突一定会发生,所以访问数据前“先加锁”,别人就不能同时改
- 如synchronized、ReentrantLock
应用场景
- 写多、读少,冲突频繁的环境
- 对数据库敏感操作(更新、删除)
- 必须严格保证数据一致性时
- 比如:银行转账、库存扣减,不能有并发写入导致超卖或数据不一致。
2.1⭐️⭐️⭐️乐观锁是怎样实现的?
它常见的实现方式有两种:
CAS(Compare And Swap)机制:
- CAS 是一种原子操作:比较内存值和预期值,如果相等就更新,否则失败重试。
- 这个操作是由 CPU 的原子指令实现的,所以性能很好,不需要加锁。
版本号机制(常用于数据库乐观锁):
数据表加一个
version字段,每次更新数据时,同时检查版本号。修改数据前,检查
当前数据库version是否和读取时一致
,
- 如果一致 → 更新并把版本号加 1,
- 如果不一致 → 说明有人修改过,需要重试
2.2 ⭐️⭐️CAS 你知道吗?
定义:CAS 是一种乐观锁机制,全称 Compare And Swap,
- 核心思想是:更新数据前先比较当前值和期望值是否一致,一致才更新,否则重试。
过程:
- 线程先读出共享变量的旧值;
- 带着旧值和计算后的新值去更新主存;
- 如果此时主存中的值还等于旧值,就更新成功;否则说明被别的线程改过了,就需要自旋重试。
优点:无锁高性能、不需要阻塞挂起线程,适合高并发场景。由 CPU 保证的底层原子性,线程安全。
缺点:
- ABA 问题:变量 A 变成 B 又变回 A,CAS 误认为没变。常见解决办法是加版本号(AtomicStampedReference)。
- 自旋开销大:失败后会不断重试会浪费 CPU。
- 只能保证一个变量的原子性。
2.3 ⭐️⭐️⭐️谈谈你对 volatile 的理解
- volatile 是 Java 里的一个关键字,主要用在多线程编程中,用来保证变量的“可见性”。
作用:
- 保证可见性:一个线程修改了 volatile 变量,其他线程能立即看到。
- 禁止指令重排:通过内存屏障保证代码执行顺序,常用于双重检查锁的单例模式。
限制:
- 不保证原子性,比如
i++这种复合操作用 volatile 还是线程不安全,因为它不是一个原子操作。使用场景:
- 所以 volatile 一般用在那种状态标志位、比如停止线程的 boolean flag 这类场景中。
1 | |
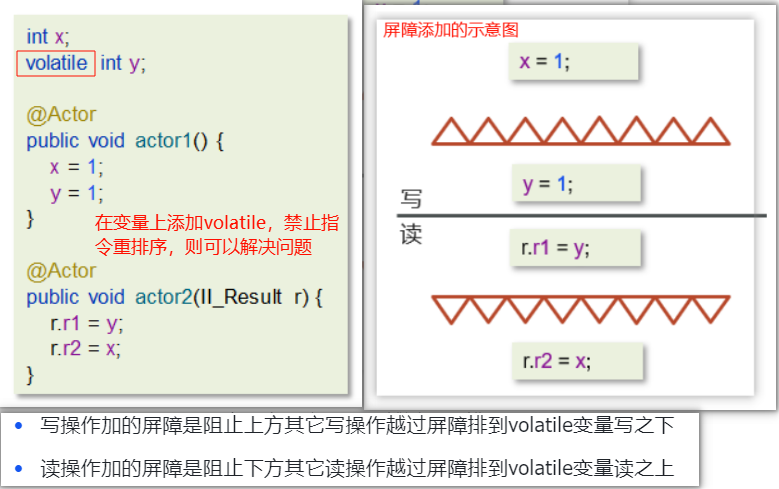

所以,现在我们就可以总结一个volatile使用的小妙招:
- 写变量(actor1)让volatile修饰的变量的在代码最后位置
- 读变量(actor2)让volatile修饰的变量的在代码最开始位置
2.4⭐️⭐️⭐️synchronized关键字底层原理?
- 是Java 提供的一种内置锁,它可以作用于方法或代码块,用来保证同一时间只有一个线程访问同步代码块或方法。
- 当线程进入 synchronized 区域时,会尝试获取锁;如果锁被占用,它就会阻塞等待。执行完毕后,锁会自动释放,让其他线程继续执行。
- synchronized 底层使用的 对象头中的Monitor 来决定当前线程是否获得了锁。
- Monitor 内部有 Owner、EntryList、WaitSet,分别记录持有锁、阻塞等待和调用 wait()方法 的线程。
代码进入synchorized代码块的具体的流程是:
- 先判断对象关联的monitor中Owner是否有线程持有。
- 如果没有线程持有,则让当前线程持有,表示该线程获取锁成功。
- 如果有线程持有,则让当前线程进入entryList进行阻塞,如果Owner持有的线程已经释放了锁,在EntryList中的线程去竞争锁的持有权(谁抢到锁,谁就先执行)。
- 如果代码块中调用了wait()方法,则会进去WaitSet中进行等待。
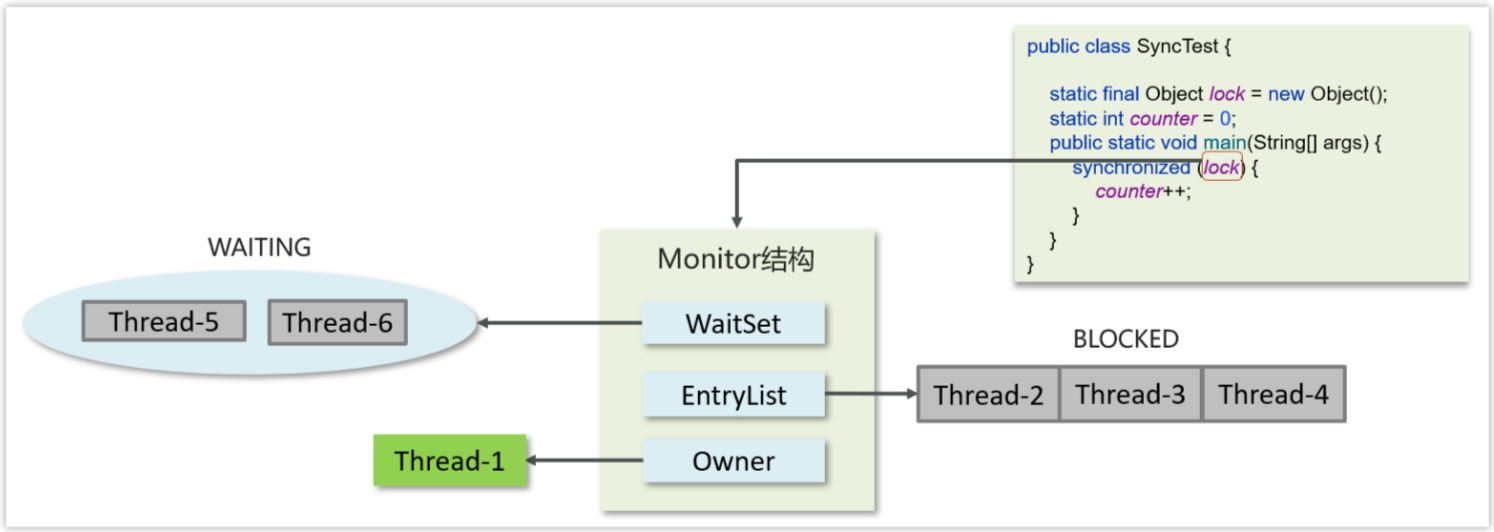
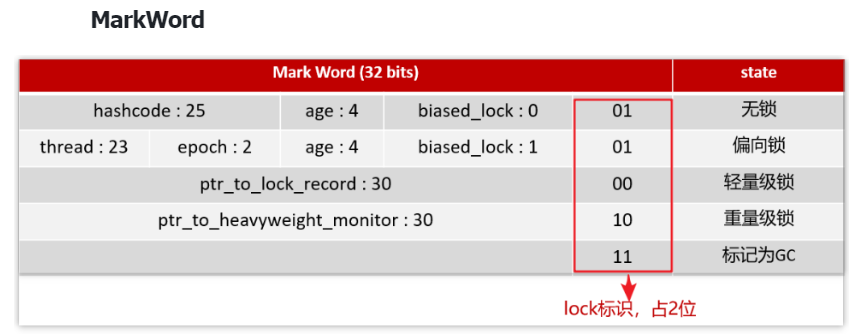
2.5⭐️⭐️⭐️Monitor实现的锁属于重量级锁,你了解过锁升级吗?
传统的 Monitor 锁属于重量级锁,开销大。JDK 1.6 之后,为了优化性能,引入了锁升级机制,根据竞争程度自动在三种锁之间切换:
- 偏向锁:适用于只有一个线程访问同步代码块的情况,对象头记录线程 ID,后续访问无需竞争,直接获取锁,提升性能。
- 轻量级锁:当有另一个线程参与竞争时,偏向锁会升级为轻量级锁,线程通过 CAS 操作尝试获取锁,不成功就短暂自旋等待,适合锁竞争不激烈的场景。
- 重量级锁:如果竞争严重,自旋失败,就升级为重量级锁,线程会被阻塞,由操作系统调度,涉及上下文切换,性能最差,但能保障线程安全。
从偏向锁 → 轻量级锁 → 重量级锁,逐级升级,尽量避免线程阻塞,提高并发性能。

2.6⭐️⭐️JMM(Java 内存模型)
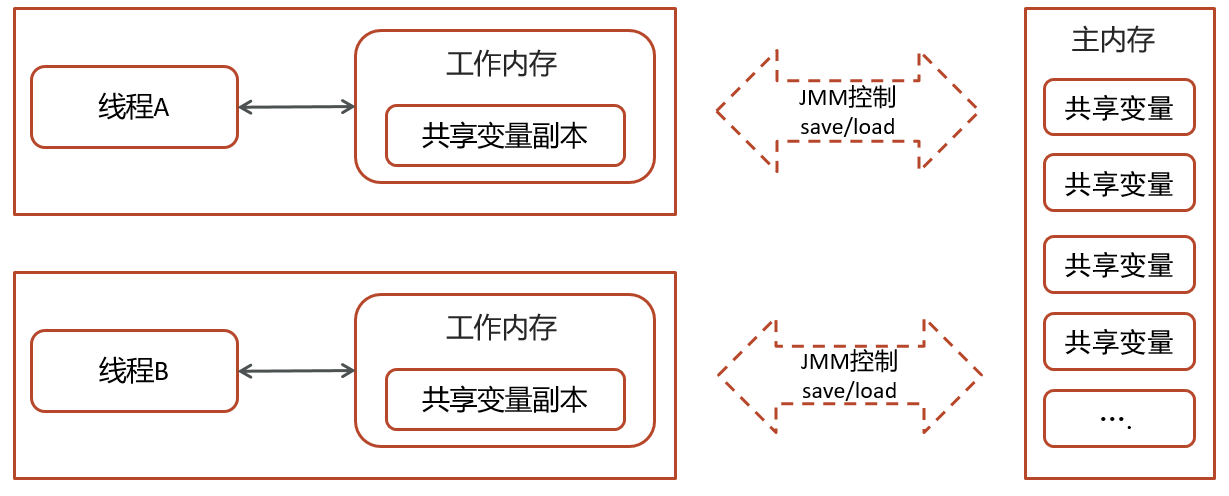
Java Memory Model 规定了 多线程读写共享变量的规则,主要解决 可见性、有序性、原子性 三大问题。
- 主内存 & 工作内存:
- 变量都存在 主内存(共享区)。
- 每个线程有自己的 工作内存(类似缓存)。
- 线程对变量的操作(读取、赋值)必须先从主内存拷贝到工作内存,然后再写回主内存。
- 线程之间不能直接访问对方的工作内存。
- JMM 三大特性:
- 可见性:一个线程修改了共享变量,其他线程能及时看到(
volatile/synchronized保证)。- 有序性:禁止指令重排(
volatile+ 内存屏障保证)。- 原子性:一个操作不可再分割,要么全做要么全不做(
synchronized/Lock保证)
2.7 ⭐️⭐️⭐️什么是AQS?核心思想是什么?
- AQS 全称是 AbstractQueuedSynchronizer(抽象队列同步器),是 Java 并发包里一个非常核心的抽象类。像可重入锁ReentrantLock、倒计时锁CountDownLatch、信号量Semaphore 这些常用的同步器,底层都是基于 AQS 实现的。
- 它的核心思想是:
- 状态变量(state):AQS 内部用一个 volatile int state 表示共享资源的状态,
在 ReentrantLock 里,state = 0说明锁空闲,state > 0说明被线程占用,值还可以记录重入的次数。
线程竞争锁时会通过 CAS 操作修改这个 state。- 等待队列:当线程没抢到锁时,AQS 会把它封装成一个 Node 节点,加入一个 FIFO 的双向队列里去挂起,等前面线程释放资源时再被唤醒。
- 提供了统一的同步框架,使得开发人员可以方便地构建各种同步器,减少了代码的重复开发
既然多个线程同时去抢锁,都要修改 state,那怎么保证不会乱呢?
CAS 是什么?
CAS 操作是 硬件层面提供的原子指令。它会做三件事:
- 读取内存中某个值(比如 state = 0);
- 和预期值比较(比如预期也是 0);
- 如果相等,就把新值写进去(比如改成 1),这个过程是 不可分割的原子操作;
如果不相等,说明有别的线程已经改了,那 CAS 就失败,返回 false。
多线程同时修改 state 的场景:
假设有三个线程 T1、T2、T3 同时去抢锁(此时 state = 0):
T1 先执行 CAS:发现 state = 0,预期值也是 0,就成功把 state 改成 1。T1 抢到锁。
T2 也执行 CAS:但它期望 state = 0,而现在内存里已经是 1 了 → CAS 失败。 T3 同理,也失败。
于是,T2 和 T3 就会被 AQS 放入等待队列里排队。
为什么能保证原子性?
- AQS 能保证多个线程抢同一个资源时的原子性,靠的就是 CAS 操作。
- CAS 是底层硬件提供的原子指令,它确保修改 state 的过程不会被打断,所以多个线程同时竞争时,只有一个能成功修改 state,其他线程都会失败并进入等待队列。
AQS是公平锁吗,还是非公平锁?
AQS 本身是一个框架,既可以实现公平锁,也可以实现非公平锁,取决于具体的子类实现。
- 公平锁:线程按等待队列的顺序获取锁(先来先得),不允许 “插队”;
- 非公平锁:线程获取锁时先尝试直接竞争,无视队列顺序(可能插队)。
比较典型的AQS实现类ReentrantLock,它默认就是非公平锁,新的线程与队列中的线程共同来抢资源。
2.8 ⭐️⭐️ReentrantLock的实现原理
ReentrantLock 是一个可重入锁。底层就是基于 AQS(AbstractQueuedSynchronizer) 实现的。
- 它通过一个 volatile 的 state 变量来记录锁的状态,0 表示没被占用,>0 表示被占用,值还可以记录重入的次数。
- 线程获取锁时,会用 CAS 修改 state,抢到的线程就设置为锁的持有者;抢不到的线程就会被加入到 AQS 的等待队列里,阻塞等待。
- 释放锁的时候,会把 state 减少,如果减到 0,说明完全释放了,就会唤醒等待队列中的下一个线程。
这就是它的基本实现逻辑。
- 可重入性:同一个线程可以多次获取同一把锁,不会被自己阻塞。每次加锁会把一个计数器加一,释放锁时减一,直到减到 0 真正释放。
- 独占锁:它是排他锁,一次只允许一个线程获取,没拿到锁的线程会进入 AQS 的 等待队列 挂起,等着被唤醒。
2.9 ⭐️⭐️ReentrantLock如何实现公平锁和非公平锁?
首先解释公平和非公平的概念:
- 公平:竞争锁资源的线程 严格按照请求的顺序来分配锁
- 非公平:竞争锁资源的线程 允许插队来尝试抢占锁资源
ReentrantLock 提供了两种模式:
- 非公平锁(默认):线程一来就直接用 CAS 抢锁,不管队列里是否有人排队,如果成功就直接拿到锁,失败了再进入队列。这样效率更高,但可能会导致“插队”。
- 公平锁:线程在获取锁时,先检查等待队列里有没有前驱节点,如果有,就老老实实排队,按 FIFO 顺序获取锁,这样保证了公平性。
2.10 ⭐️⭐️⭐️⭐️synchronized和ReentrantLock有什么区别 ?
| ReentrantLock | Synchronized | |
|---|---|---|
| 特性 | JUC 包下的类 | JVM 层面的关键字 |
| 实现层面 | 基于 AQS 实现 | 底层通过对象头的 Mark Word 和 Monitor 实现,由 JVM 保证 |
| 用法区别 | 手动调用 lock() 和 unlock() 加锁解锁,更灵活但要注意释放锁 | 加锁和释放是JVM****自动完成的 |
| 公平锁 | 提供了公平锁和非公平锁 | 是非公平锁,不支持公平锁 |
| 可重入性 | 可重入 | 可重入 |
| 使用场景 | 提供了更多功能,如可中断锁,适合复杂场景 | 适合简单场景 |
2.11 ⭐️⭐️⭐️死锁产生的条件?诊断方法?如何避免死锁?
死锁的产生条件?
死锁就是多个线程互相等待对方的资源,最后谁都动不了,就“锁死”了。
死锁产生必须同时满足四个条件:
- 互斥条件:资源一次只能被一个线程占用。
- 占有且等待:一个线程已经持有了部分资源,又在等待其他资源。
- 不可剥夺:线程持有的资源在未使用完之前,不能被强行剥夺。
- 循环等待:存在一个线程等待环,比如 T1 等待 T2 的资源,T2 等待 T1 的资源。
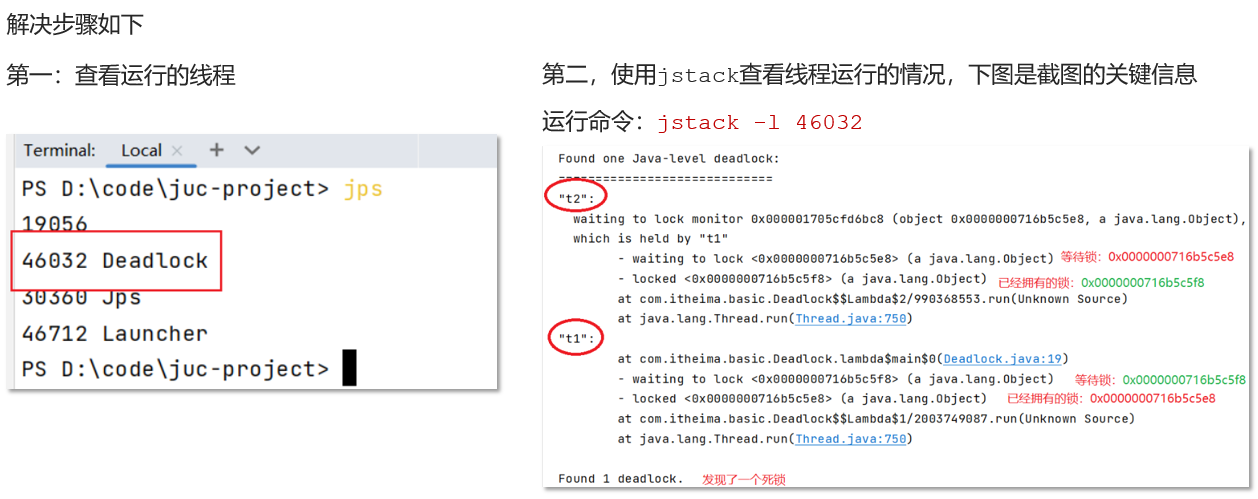
如何进行死锁诊断?
知道。其实用 JDK 自带的工具就够了。
我一般会这样:
- 先用 jps,看一下当前有哪些 Java 进程,拿到我要排查进程的 PID。
- 再用 jstack 打印这个进程的线程堆栈信息。如果有死锁,jstack 会直接提示“Found one Java-level deadlock”,而且会把涉及的线程和锁打印出来,很直观。
- 如果想要更直观一点,我会用 jconsole 或者 VisualVM,它们都有图形化界面。
- jconsole 在发生死锁的时候会直接弹出提示。
- VisualVM 功能更强大,还能看到线程、内存、CPU 使用情况,分析起来更方便
如何避免死锁?
- 保持统一的加锁顺序:比如我们要同时锁 A 和 B,就规定所有线程必须先锁 A,再锁 B,这样就不会形成循环等待。
- 尽量少用嵌套锁:锁嵌套越多,死锁风险越高,能拆开就拆开。
- 设置超时或支持中断:像 ReentrantLock 的
tryLock(timeout),超过时间没抢到就放弃,避免线程无限挂起。
比如一个线程调用了 lock() 去拿锁,结果锁一直没释放,它就一直阻塞在那儿,相当于“挂住”了,不再往下执行。在死锁场景里,这就是问题所在:大家都在等别人释放锁,结果谁也等不到,就一起挂起了。
2.12⭐️⭐️线程安全的本质?导致并发程序出现问题的根本原因是什么?
我理解线程安全的本质就是 多线程访问共享资源时,最终的执行结果要和单线程下的预期结果一致,并且不会出现数据不一致或程序异常。
并发程序出问题的根本原因就是 对共享资源的访问没有正确同步。
这通常有三个具体表现:
- 原子性问题:比如 i++ 不是原子操作,多个线程一起执行会丢失更新。
- 可见性问题:一个线程修改了变量,另一个线程可能看不到最新值,比如 CPU 缓存没刷新。
- 有序性问题:指令重排导致线程看到的执行顺序和预期不一样。
所以我们才需要用 锁、CAS、volatile、内存屏障 这些机制来保证线程安全。
并发问题的根源是 原子性、可见性、有序性 没有保证。
3. 线程池
3.0⭐️使用线程池ThreadPoolExecutor的好处
用线程池主要有三个好处:
- 降低资源消耗:线程是很昂贵的资源,频繁创建和销毁线程开销大,线程池能复用已有线程。
- 提高响应速度:任务来了不用新建线程,直接复用线程池里的线程,响应会更快。
- 可统一管理:线程池能帮我们控制线程数量,避免无限制创建线程导致 OOM,还能提供一些监控和扩展能力。
3.1⭐️⭐️⭐️线程池的核心参数
1 | |
- corePoolSize 核心线程数:核心线程数,线程池始终保留的线程数量;
- maximumPoolSize 最大线程数:最大线程数 = 核心线程 + 救急线程的最大数量;
- keepAliveTime 线程空闲存活时间:救急线程空闲多久后会被销毁;
- unit 时间单位: 指定
keepAliveTime的时间单位,如秒、毫秒等- workQueue 任务队列:用于存放待执行任务的队列。当核心线程都在工作,新任务会存入这里。
- threadFactory 线程工厂: 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等;
- handler 拒绝策略: 当任务队列满且线程数达到最大线程数时,对新提交任务的处理方式。
3.1⭐️⭐️⭐️线程池四大拒绝策略?
嗯,JDK 里其实自带了四种拒绝策略:
- AbortPolicy(中止策略):默认的拒绝策略,直接抛异常,如果任务很关键就要小心用(如订单支付、消息通知),因为可能丢掉关键任务。
- CallerRunsPolicy(调用者运行策略):把任务交给提交任务的线程自己执行,这样相当于“压制”提交速度,不会丢任务,但可能会拖慢调用方。
- DiscardPolicy(丢弃策略):直接丢掉任务,也不报错,适合那种偶尔丢一两个没关系的轻量任务。
- DiscardOldestPolicy(丢弃最旧任务策略):把队列里最老的任务丢掉,再尝试加新任务,适合新数据比旧数据更重要的场景,比如实时监控。
3.1⭐️⭐️线程池的执行原理(流程)?
线程池接收任务的时候,大体上是按这几个步骤走的:
- 先看核心线程数
如果当前线程数还没到核心数,就会直接创建一个新线程去执行任务。- 核心线程都在忙
如果已经达到核心线程数了,任务就会放进队列里排队。- 队列也满了
这时候会继续创建线程,但数量不会超过最大线程数。- 线程数也到上限了
那新任务就没办法处理了,会交给拒绝策略来处理,比如丢弃、抛异常,或者交给调用线程去执行。- 任务执行完成以后
线程会去队列里拿新的任务来执行。如果线程数超过了核心数,而且空闲时间超过 keepAliveTime,多余的线程就会被回收掉。
3.1⭐️上线后你会关注线程池的哪些指标?
我会重点关注几个:
- 活跃线程数:看看是不是一直接近最大值,如果接近,说明线程池快顶不住了。
- 队列长度:如果队列一直在堆积,说明任务处理不过来。
- 已完成任务数和总任务数:可以看出处理效率。
- 拒绝次数:这个一旦出现,就说明线程池和队列都满了,需要优化参数或者业务。
- 还有 线程存活时间,能帮助判断参数是不是设置合理。
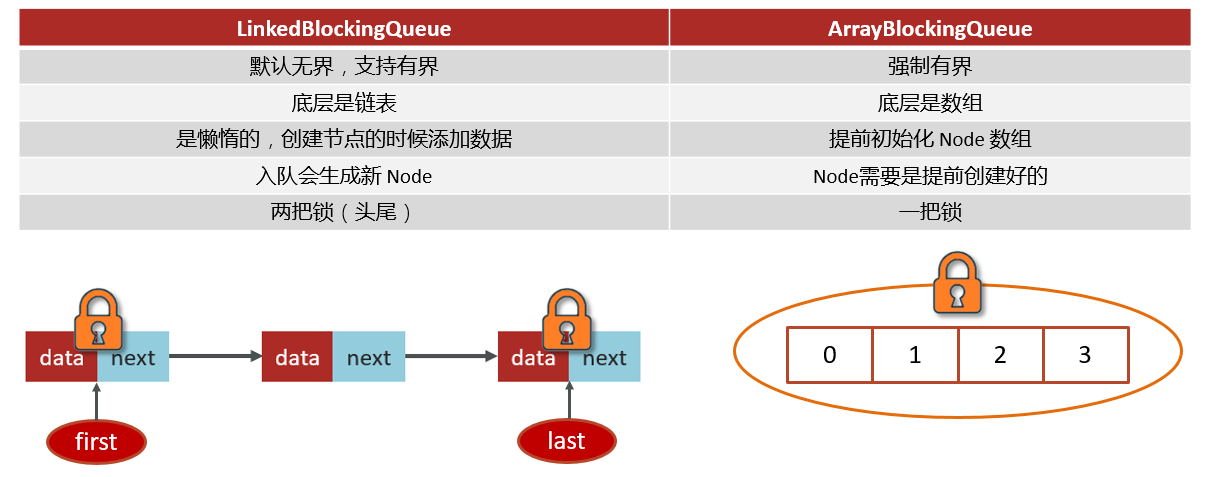
3.2 线程池中有哪些常见的阻塞队列
workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务。常用的主要有两个:
- ArrayBlockingQueue:基于数组的,有界队列,创建时就要指定容量。它是一把锁控制读写,访问快,但并发性稍差。
- LinkedBlockingQueue:基于链表,默认是无界的,也可以指定容量。它用了两把锁,读写分开,并发性能更好,但因为链表结构,访问元素没数组快。
- 如果任务量可控,我一般会用 ArrayBlockingQueue,避免无限堆积;
- 如果任务很多但能接受排队,就会用 LinkedBlockingQueue。
3.3 ⭐️⭐️⭐️⭐️如何确定核心线程数
这个我觉得要结合任务类型来看:
- 如果是 CPU 密集型任务(比如加密、计算),线程数一般设为 CPU 核心数 + 1,这样能把 CPU 利用到最大。
- 如果是 IO 密集型任务(比如文件、网络请求),线程数就要多一些,因为线程大部分时间在等 IO,可以设为 CPU 核心数的 2 倍。
当然,实际工作里我觉得还需要通过压测去验证和调整,不能光凭经验值。
3.4 线程池的种类有哪些
在java.util.concurrent.Executors类中提供了大量创建连接池的静态方法,常见就有四种:
1. 单线程线程池(SingleThreadExecutor)
- 特点:只有一个线程,所有任务都会按顺序执行。
- 核心线程数和最大线程数都固定为 1
- 适用于按照顺序执行的任务,日志写入。
2. 固定大小线程池(FixedThreadPool)
- 特点:线程池的线程数量是固定的,在创建时就指定好了。当有新任务提交时,如果有空闲线程,就会分配给空闲线程执行;如果所有线程都在忙碌,任务会在任务队列中等待。
- 核心线程数与最大线程数一样,没有救急线程
- 适合任务量比较稳定的场景
3. 缓存线程池(CachedThreadPool)
- 特点:线程池中的线程数量是可变的,根据任务数量动态调整。如果有新任务提交,且没有空闲线程,会立即创建新的线程来执行任务;如果线程空闲时间超过 60 秒,会被销毁。
- 适合任务数比较密集,但每个任务执行时间较短的情况
4. 定时任务线程池(ScheduledThreadPool)
- 特点:可以执行定时任务和周期性任务。线程池中的线程数量在创建时指定,能够按照设定的时间间隔或延迟时间执行任务。
- 适合做定时调度。
创建:ExecutorService executor = Executors.newSingleThreadExecutor();
创建:ExecutorService executor = Executors.newFixedThreadPool(5);
创建:ExecutorService executor = Executors.newCachedThreadPool();
创建:ScheduledExecutorService executor = Executors.newScheduledThreadPool(3);
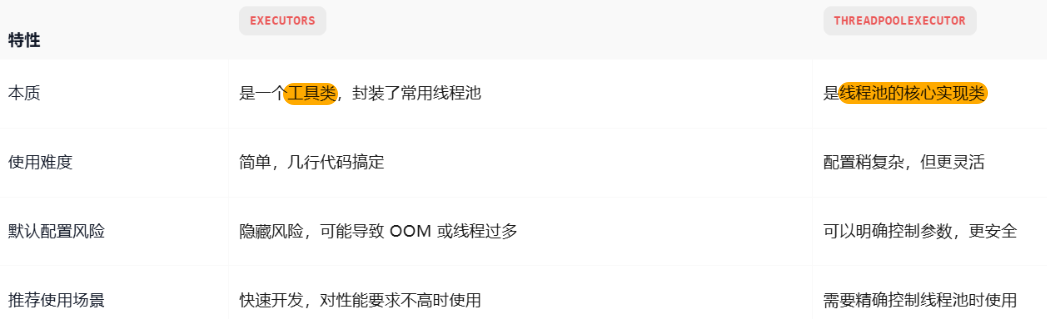
3.5⭐️⭐️为什么不建议用Executors创建线程池
- 虽然用 Executors 创建线程池很方便,但不推荐用,主要是因为它默认的参数不安全。
比如:
- FixedThreadPool() 和 SingleThreadExecutor() 默认用的是 无界队列,如果任务太多可能把内存撑爆。
- CachedThreadPool() 和 ScheduledThreadPool 默认最大线程数是 Integer.MAX_VALUE,在高并发场景下可能疯狂创建线程,直接导致 OOM。
- 所以更推荐自己用 ThreadPoolExecutor 来创建线程池,这样可以手动配置核心线程数、最大线程数、队列长度和拒绝策略,更安全也更可控。
4. 线程使用场景问题
4.1 线程池使用场景CountDownLatch、Future
CountDownLatch
CountDownLatch是一个并发工具类,它的核心作用就是 让一个或多个线程等待,直到一组操作执行完成。
- 它内部维护了一个计数器,初始化时设置一个数值。
- 每次调用
countDown(),计数器就减一;- 当计数器减到 0 的时候,所有在
await()上等待的线程就会被唤醒。常见场景是:主线程需要等多个子任务都完成再继续,比如并行加载多个远程配置文件,全部完成后再启动应用。
CountDownLatch 通过 AQS实现,通过state计数。等待线程调用 await() ,state != 0加入队列。任务线程通过 countDown() 递减 state,归零时触发唤醒。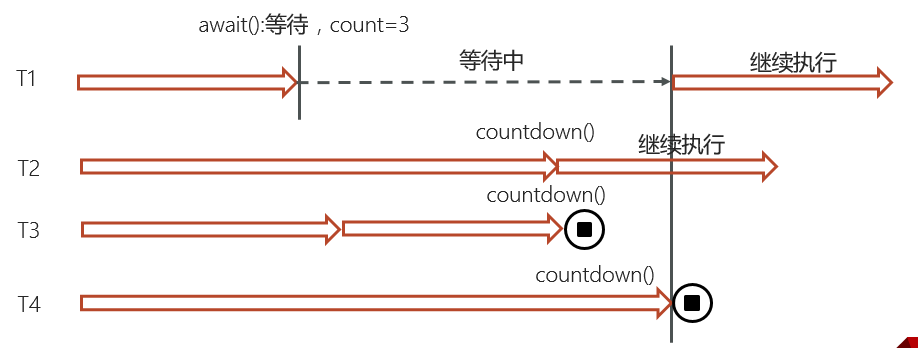

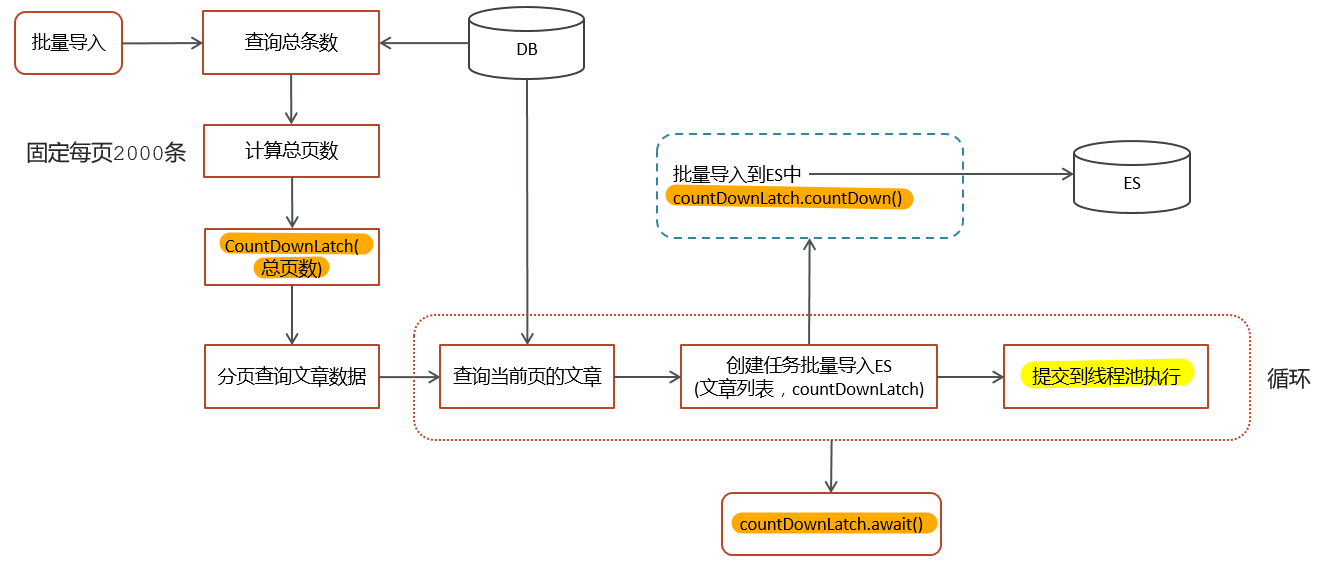
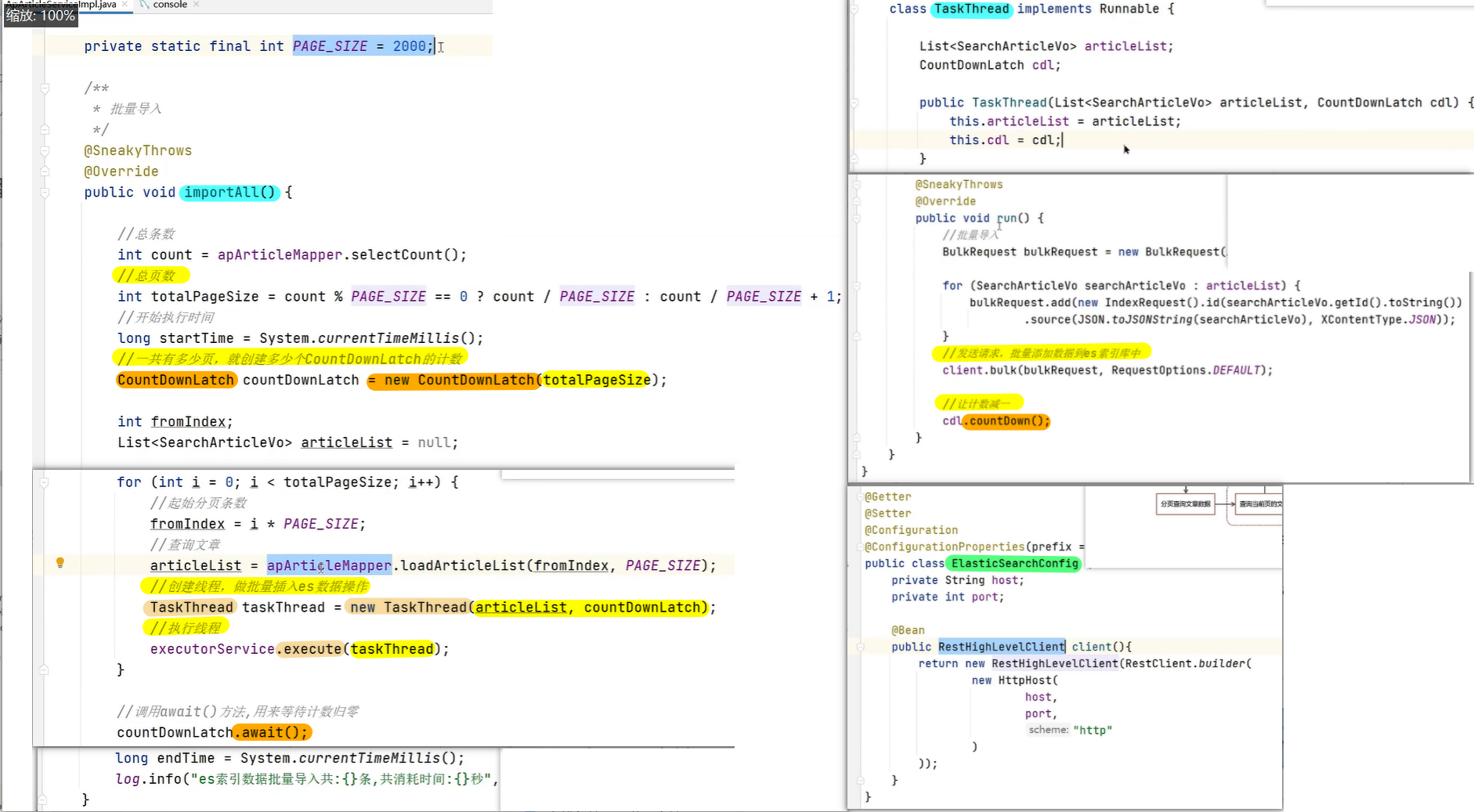
案例一( es数据批量导入)
- 在我们项目上线之前,我们需要把数据库中的数据一次性的同步到es索引库中,但是当时的数据好像是1000万左右,一次性读取数据肯定不行(oom异常),如果分批执行的话,耗时也太久了。
- 当时我就想到可以使用线程池的方式导入,利用CountDownLatch来控制,就能避免一次性加载过多,防止内存溢出。
整体流程就是通过CountDownLatch+线程池配合去执行

详细实现流程:
4.2 如何控制某个方法 允许 并发访问线程的数量?
如果我有一个方法,只允许同时有 N 个线程并发访问,你会怎么做?除了 Semaphore,还有别的方法吗?
我第一反应就是用 Semaphore(信号量)。Semaphore 内部也是基于 AQS 实现的。
- 它本质上是一个计数器,初始化的时候设置一个许可数,比如 N=3,表示最多只能有 3 个线程同时进入这个方法。
- 当线程进入时会
acquire()拿一个许可,执行完再release()释放许可。- 如果没有许可了,后面的线程就会阻塞等待。这样就能精确控制并发线程数。
- 也可以用 线程池 来控制,核心线程数设置成 N,这样天然就保证了只有 N 个线程能并行执行任务。

4.3⭐️⭐️⭐️谈谈你对ThreadLocal的理解
- ThreadLocal 其实不是用来解决多线程共享变量问题的,其主要功能是为每个线程提供一份独立的变量副本。
- 这样同一个变量,不同线程之间互不干扰,各用各的。典型场景比如用户 Session、或者一些上下文信息的存储。
4.4⭐️⭐️⭐️ThreadLocal的底层原理实现
- 底层其实就是在线程对象里,维护了一个
ThreadLocalMap,这个 Map 的 key 是 ThreadLocal 本身,value 就是要存储的值。- 所以每个线程都有属于自己的
ThreadLocalMap,存进去和取出来,都是在当前线程里找,天然就实现了线程隔离。
4.5 你说的 ThreadLocalMap,有没有什么特别的地方?
- 有的。它的 key 其实是一个弱引用(WeakReference),
这样做是为了防止 ThreadLocal 对象不用的时候,还一直被强引用,导致没法被回收。- 但是这里就埋下了一个隐患:
如果 ThreadLocal 被回收了,Map 里的 key 变成了null,但是它的 value 可能还在,这就可能导致内存泄漏。
4.6⭐️⭐️⭐️ThreadLocal内存泄漏(溢出)问题
内存泄漏的本质原因是:
- key 是弱引用,很容易被 GC 回收;
- value 却是强引用,可能一直跟着线程活着,尤其是在线程池这种线程不会销毁的场景。
- 如果我们不用的时候不手动
remove(),这些 value 就会一直占着内存。所以最佳实践就是:
- 用完一定要调用
remove()清理;- 避免在线程池这种长生命周期线程里,随意放大对象。
4.7 那总结一下 ThreadLocal 的优缺点吧?
- 优点:线程隔离、使用简单,避免了加锁带来的性能开销。
- 缺点:容易被误解为线程间共享变量;另外如果用不当,很容易导致内存泄漏。
5. 多线程交替打印
5.1 ⭐️⭐️⭐️多线程交替打印ABC(Semaphore)
1 | |
用 信号量(Semaphore) 控制线程执行顺序
semA初始值为 1,保证线程 A 最先执行;semB和semC初始值为 0,意味着 B 和 C 必须等待;- A 打印完 →
semB.release()→ 轮到 B;- B 打印完 →
semC.release()→ 轮到 C;- C 打印完 →
semA.release()→ 下一轮又回到 A;- 这个循环执行 N 次,就能得到
ABCABCABC。执行流程举例(N=3):
开始时:
semA=1,semB=0,semC=0- A 线程能运行,B 和 C 都会阻塞。
第一轮:
- A 获取
semA,打印"A",释放semB→ 现在semB=1。- B 获取
semB,打印"B",释放semC→ 现在semC=1。- C 获取
semC,打印"C",释放semA→ 现在semA=1。👉 输出:
ABC第二轮、第三轮:
重复上面过程,最终输出ABCABCABC。为什么能保证顺序?
- 每个线程在打印前必须
acquire()对应的信号量;- 只有上一个线程
release()之后,当前线程才能继续;- 形成一个严格的执行链条:
拿 semA → 打印 "A" → 释放 semB(唤醒 B)
5.2 ⭐️⭐️⭐️2个线程交替打印0-100(synchronized + wait + notifyAll)
用 synchronized + wait + notifyAll 来保证线程按顺序交替打印。
1 | |
整体逻辑
我们想让多个线程交替打印数字(0~100):
- 用一个全局共享变量
count表示当前要打印的数字。- 每个线程有自己的
index(编号),比如 2 线程时是 0、1,3 线程时是 0、1、2。- 线程根据
count % N == index判断是不是自己要打印,如果不是,就wait()挂起等待- 打印后
count++,再notifyAll()唤醒其他线程。这样大家就能 轮流打印 了。
第一个
if (count > MAX)
- 这个在进入临界区后马上判断:
- 说明可能别的线程已经把数字打印完了(比如最后一个数字 100 打完)。
- 那么当前线程就没必要再干活了,直接退出循环。
notifyAll()是为了防止有线程还在wait()状态里卡死,保证大家都能顺利结束。 👉 这是 **”预检查退出”**。
第二个
if (count > MAX)
- 这个出现在
wait()之后:
- 线程被唤醒时,不一定是它的 turn,有可能已经结束了。
- 如果别的线程在这期间把
count打到 >100 了,那当前线程就要再检查一次。- 否则它可能还会执行
System.out.println(...),导致 打印超过 100 的错误。 👉 这是 **”打印前的安全检查”**。
总结
- **第一个
if**:保证线程刚进来时发现任务结束 → 直接退出,避免死锁。- **第二个
if**:保证被唤醒时不再打印多余数字 → 避免越界。- 两个
if各有用途,不是重复,也不是错误。
5.3 ⭐️3个线程交替打印0-100
1 | |
原因:
- 用了
synchronized+wait()+notifyAll()控制并发;- 用
count % N == index判断是否该自己打印;- 两个
if (count > MAX)保证了 不会越界打印、不会死锁。这类写法就是经典的“多线程轮流打印”题的标准解法。面试官一般会追问:
- 为什么要两个
if (count > MAX)?- 为什么要
notifyAll()而不是notify()?
(因为有多个线程等待,notify()可能唤醒错线程,导致大家都卡死。)
即便是 2 个线程,用notify()也存在唤醒错误 → 双方都 sleep → 程序卡死。
所以稳妥的做法是 **永远用notifyAll()**。