Java集合
集合概述
1.⭐️⭐️⭐️常见的Java集合有哪些?
Java 的集合大体分成两类:单列集合(Collection) 和 双列集合(Map)。
1. 单列集合(Collection):主要存放单个元素,又分三种:
- List(有序,可重复)
ArrayList:底层是动态数组,查询快,增删慢。LinkedList:底层是双向链表,增删快,查询慢。Vector:老的线程安全实现,现在基本不用了。- Set(无序,不可重复)
HashSet:基于哈希表,查找快,但无序。LinkedHashSet:在 HashSet 基础上加了链表,能保持插入顺序。TreeSet:基于红黑树,元素有序,可以自定义排序。- Queue / Deque(队列/双端队列)
PriorityQueue:基于堆实现,按优先级处理元素。ArrayDeque:高效的双端队列。2. 双列集合(Map):存储键值对,Key 唯一
HashMap:最常用,基于哈希表,Key 无序,查找快。LinkedHashMap:保留插入顺序。TreeMap:基于红黑树,Key 按自然顺序或自定义排序。Hashtable:早期的线程安全 Map,现在基本被ConcurrentHashMap取代。
Java 集合框架如下图所示:
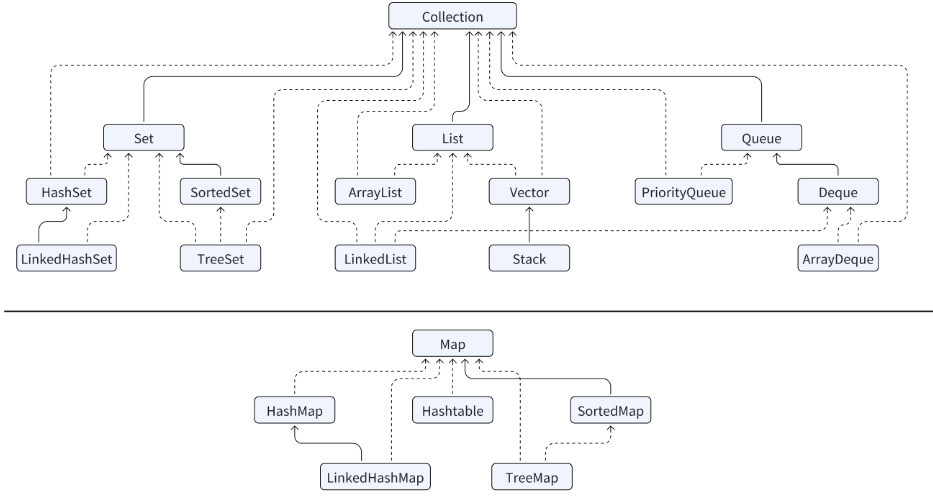
2.说说List,Set,Queue,Map四者的区别?
- List列表:有序,允许重复,按索引访问。
需要按顺序存放、允许重复数据,比如存放订单列表、聊天记录- Set集合:无序,不允许重复元素,只能遍历或迭代器访问集合中的元素。
去重场景,比如存用户 ID、关键词集合- Queue队列:有序,先进先出(FIFO)。
任务调度、排队系统、消息队列- Map映射:键值对存储,键唯一,值可重复。
需要通过 key 快速查找 value 的场景,比如缓存。
3. ⭐️⭐️⭐️Java集合框架底层数据结构总结
List 接口
- ArrayList:基于动态数组实现。查询快,增删慢。初始时会创建一个默认大小的数组,当元素数量超过数组容量时,会创建一个更大的新数组,并将原数组元素复制过去。它支持随机访问,通过索引能快速定位元素,但在插入、删除元素时效率较低,因为需要移动元素。
- LinkedList:基于双向链表实现。查询慢,增删快。每个节点包含数据、指向前一个节点的引用和指向后一个节点的引用。插入和删除元素效率高,只需修改相邻节点的引用,但随机访问效率低,需要遍历链表。
- Vector:基于动态数组实现,与
ArrayList类似,但它加了同步锁,是线程安全的,不过由于加锁操作,性能相对较低。Set 接口
- HashSet:基于
HashMap实现,内部存储元素的实际是HashMap的键,值统一为一个静态常量对象。通过hashCode()和equals()方法来保证元素的唯一性。插入、删除和查找元素的时间复杂度平均为 O (1)。- LinkedHashSet:继承自
HashSet,底层使用LinkedHashMap存储元素。它维护了一个双向链表,记录元素插入的顺序,因此迭代时可以按照插入顺序访问元素。- TreeSet:基于红黑树(一种自平衡的二叉搜索树)实现。元素会按照自然顺序或指定的比较器顺序进行排序。
Map 体系
- HashMap:基于哈希表实现,
在 JDK 8 之前,哈希表由数组 + 链表组成,当发生哈希冲突时,元素会存储在链表中。JDK 8 及以后,当链表长度超过阈值(默认为 8)且数组长度大于 64 时,链表会转换为红黑树,以提高查找效率。它不保证元素的顺序,线程不安全。- LinkedHashMap:继承自
HashMap,在**HashMap的基础上维护了一个双向链表,用于记录元素的插入顺序或访问顺序**(常用于 LRU 缓存),所以遍历时能保持顺序。- TreeMap:基于红黑树实现,键key会按照自然顺序或指定的比较器顺序进行排序。
- Hashtable:基于哈希表实现,
HashMap非线程安全,但它是线程安全的,不过由于加锁操作,性能相对较低。并且不允许键或值为null。- ConcurrentHashMap:
JDK 1.7:分段锁 + 数组 + 链表
JDK 1.8:CAS + synchronized + 数组 + 链表 + 红黑树
特点:高并发场景下的 Map 实现。
4.如何选用集合?
只是存一批元素(不需要 key)
- 允许重复 → List。
- 查询多、随机访问多 → ArrayList。
- 插入删除多 → LinkedList。
- 不允许重复 → Set。
- 不关心顺序 → HashSet。
- 需要有序(按插入顺序)→ LinkedHashSet。
- 需要排序 → TreeSet。
做排行榜,需要自动排序是否需要键值对存储
- 需要通过 key 找 value → 用 Map。
- 不要求顺序 → HashMap。
比如存一堆用户对象,并且要通过 id 快速查找- 要按插入顺序遍历 → LinkedHashMap。
比如做 LRU 缓存- 要排序(比如排行榜)→ TreeMap。
做排行榜,需要自动排序- 多线程环境 → ConcurrentHashMap。
特殊场景
- 队列/任务调度 → Queue / Deque
5.为什么要使用集合?
- 更方便管理数据
如果没有集合,我们只能用数组。但数组大小固定、操作不灵活。集合能动态扩容,增删查改都更方便。- 提高代码的可读性和安全性
Java 集合框架提供了统一的接口和泛型支持,可以在编译期就检查类型,避免类型转换错误,让代码更清晰。- 提升开发效率和性能
集合类内部已经帮我们实现了常见的数据结构,我们能根据需求选不同的集合来优化性能,比如我要存一批学生成绩,如果用数组,不仅要考虑扩容,还要自己写查找逻辑。用 HashMap 存 <学号, 成绩>,就能 O(1) 时间拿到成绩,写起来也简洁。
List
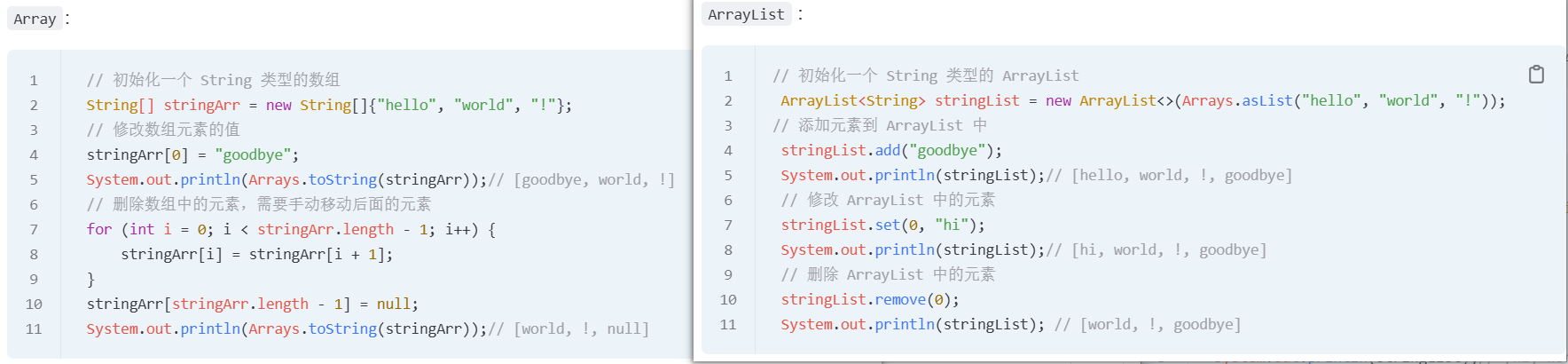
6.ArrayList与Array的区别?
长度是否固定
Array:长度固定,创建后不能改变。ArrayList:基于动态数组实现,可以自动扩容。存储内容
Array:既可以存基本数据类型(如int[]),也可以存对象引用。ArrayList:只能存对象,基本数据类型需要用包装类(如Integer)。操作方式
Array:需要自己写扩容、插入、删除逻辑,比较麻烦。ArrayList:封装了丰富的方法,比如add()、remove()、contains(),用起来更方便。类型安全
Array:不支持泛型,容易出现类型转换错误。ArrayList:支持泛型,可以在编译期检查类型,代码更安全。

7.ArrayList和LinkedList插入和删除元素的时间复杂度?
ArrayList(动态数组)
- 尾部插入/删除:
O(1)均摊,偶尔扩容会O(n)。- 头部或中间插入/删除:
O(n),因为需要移动大量元素。LinkedList(双向链表)
- 头部/尾部插入或删除:
O(1),只改指针就行。- 中间插入/删除:操作本身
O(1),但要先遍历找到位置O(n),所以整体O(n)。
8.⭐️⭐️⭐️ArrayList和LinkedList的区别?
ArrayList(动态数组实现):
- 底层结构:数组,支持随机访问。
- 访问速度快:通过索引直接定位元素,时间复杂度
O(1)。- 插入/删除慢:中间或头部操作要移动大量元素,
O(n)。- 内存占用小:只存数据,连续空间,缓存友好。
LinkedList(双向链表实现):
- 底层结构:双向链表。
- 访问速度慢:要从头或尾遍历,查找元素
O(n)。- 插入/删除快:在头尾或已知节点处操作,只改指针即可,
O(1)。- 内存占用大:每个节点额外存两个指针,空间开销比 ArrayList 大。
ArrayList 适合查询多、插入删除少的场景;LinkedList 适合插入删除多、查询少的场景。
9.ArrayList的扩容机制
- ArrayList 默认容量是 10,
- 每次容量不足时会扩容为原来的 1.5 倍,
- 底层通过新建更大数组,并复制旧数据实现,
- 所以扩容是一个比较耗时的操作。
Set
10.排序规则Comparable和Comparator的区别?
1. Comparable(自然排序)
- 在
java.lang包里。- 需要类自己实现
Comparable<T>接口,并重写compareTo(T o)方法。- 比较规则写在类内部,一个类通常只能有 一种默认排序规则。
2. Comparator(定制排序)
- 在
java.util包里。- 是一个单独的比较器,要实现
Comparator<T>接口,并重写compare(T o1, T o2)方法- 可以定义在类外,一个类可以有 多种不同的排序规则。
1 | |
1 | |
11.无序性和不可重复性的含义是什么?
- 无序性不等于随机性 ,无序性是指元素在集合中的存储顺序并不是按照添加顺序决定的,而是根据数据的哈希值决定的。
- 不可重复性是指集合中不能出现相同的元素。这里的“相同”是通过对象的
equals()和hashCode()方法来判断的。
12.比较HashSet,LinkedHashSet和TreeSet三者的异同都实现了 Set 接口 → 都具备 元素无重复 的特性。
- 都依赖
equals()和hashCode()来判断元素是否重复。
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层结构 | 哈希表(数组 + 链表 + 红黑树,JDK8 后优化) | 哈希表 + 双向链表 | 红黑树(自平衡二叉搜索树) |
| 顺序性 | 无序,元素存储顺序和插入顺序无关 | 有序,能保证插入顺序 | 排序,元素按自然顺序或自定义比较器排序 |
| 应用场景 | 适合快速查找,不关心顺序 | 适合需要 保持插入顺序 的场景 | 适合需要 排序 的场 |
Queue
13.Queue和Deque的区别
| 特性 | Queue | Deque |
|---|---|---|
| 插入/删除位置 | 只能在队尾插入,在队头删除 | 队头和队尾都能插入、删除 |
| 用途 | 单向队列(FIFO) | 双向队列,可当队列或栈 |
14.说一说PriorityQueue
- PriorityQueue 是基于堆实现的优先级队列,取元素时是按照优先级而不是 FIFO。
- 默认是最小堆,可以通过 Comparator 自定义优先级。
- 常见场景比如任务调度、Top K 问题、最短路径算法。
Map
15. HashMap与HashTable的区别
HashMap 和 Hashtable 最大的区别在于 线程安全 和 null 值支持。
- HashMap 是非线程安全的,允许 null 键和 null 值,性能更高;
- Hashtable 是线程安全的,但不允许 null 键和 null 值,性能较差。
- Hashtable 已经很少用了,在并发场景下一般推荐用
ConcurrentHashMap替代。
16.HashMap与HashSet区别
底层实现
- HashMap:底层是 数组 + 链表 + 红黑树(JDK 8+),用来存储键值对(key-value)。
- HashSet:底层其实就是基于 HashMap 实现的,只不过 HashSet 只存 key,不存 value。
存储元素
- HashMap:存储 **键值对 (key-value)**。
- HashSet:只存储 单个元素,实际上这些元素被当作 HashMap 的 key 存储。
null 的支持
- HashMap:允许 1 个 null 键,多个 null 值。
- HashSet:允许 1 个 null 元素。
使用场景
- HashMap:当需要 通过 key 快速查找 value 时用。
- HashSet:当只需要存储元素,并且要求 去重 时用。
17.HashMap和TreeMap的区别
底层实现
- HashMap:基于 哈希表(数组 + 链表/红黑树) 实现。
- TreeMap:基于 红黑树 实现。
元素顺序
- HashMap:无序,元素的存储顺序和插入顺序无关。
- TreeMap:有序,会按照 键的自然顺序(Comparable)或 指定的比较器(Comparator) 排序。
时间复杂度
- HashMap:查找、插入、删除的平均时间复杂度是 **O(1)**,最坏情况下 O(n)。
- TreeMap:查找、插入、删除的时间复杂度是 **O(log n)**,因为需要维护红黑树的平衡。
null 支持
- HashMap:允许 1 个
null键,多个null值。- TreeMap:不允许
null键(会抛 NullPointerException),但允许null值。适用场景
- HashMap:更适合 快速查找 的场景,比如缓存、映射关系存储。
- TreeMap:更适合 需要排序 的场景,比如实现有序字典、范围查询(subMap/headMap/tailMap)。
18.HashSet如何检查重复?
HashSet检查重复主要依靠hashCode()和equals()方法。- 当把对象加入
HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,- 如果没有相符的
hashcode,HashSet会假设对象没有重复出现。- 但是如果发现有相同
hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
19.HashMap的底层实现
HashMap的jdk1.7和jdk1.8有什么区别
- JDK1.8之前采用的是数组+链表。
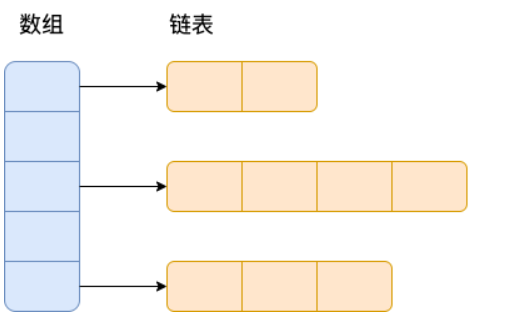
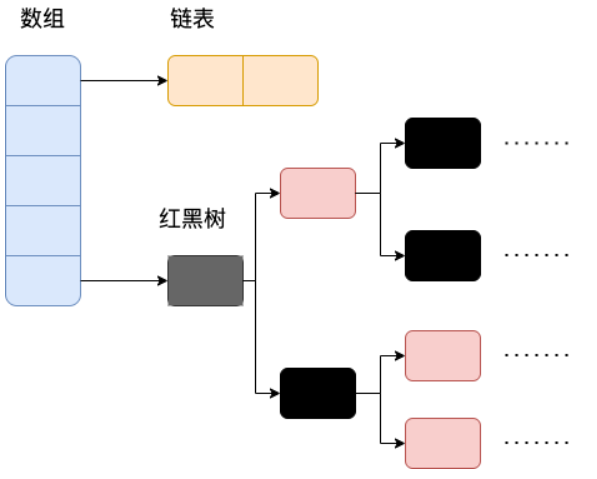
就是创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。- JDK1.8之后采用数组+链表+红黑树,链表长度大于8且数组长度大于64则会从链表转化为红黑树。
为什么优先扩容而非直接转为红黑树?
数组扩容能减少哈希冲突的发生概率,这在多数情况下比直接转换为红黑树更高效。
红黑树需要保持自平衡,维护成本较高。并且,过早引入红黑树反而会增加复杂度。
为什么选择阈值 8 和 64?
泊松分布表明,在绝大多数情况下,链表长度都不会超过 8。阈值设置为 8,可以保证性能和空间效率的平衡。
数组长度阈值 64 同样是经过实践验证的经验值。在小数组中扩容成本低,优先扩容可以避免过早引入红黑树。数组大小达到 64 时,冲突概率较高,此时红黑树的性能优势开始显现。
20.说下HashMap的put方法的具体流程?
HashMap 的 put 流程大致是:
- 先通过 key 算出 hash 定位到数组下标,
- 判断槽位是否为空:
- 如果该槽位是空的,直接放进去就行。
- 槽位不为空(哈希冲突)冲突时会有三种情况:
- key 已存在:找到相同的 key,用新值替换旧值。
- 该位置是链表:
遍历链表,
遍历过程中发现相同 key,就替换值。
没找到相同 key 就在尾部插入;
如果链表长度超过8 且 数组容量 ≥ 64,会把链表转成红黑树。- 该位置是红黑树:
这个数组位置上的节点之前因为冲突太多。
插入新节点就会按照红黑树的规则去挂载,保持树的平衡。- 检查是否需要扩容
- 每次成功插入新节点后,size++。
- 如果元素个数超过
容量 × 负载因子(默认 0.75),就触发扩容,把数组大小变为原来的 2 倍,并重新分配节点位置。
21.⭐️⭐️⭐️讲一讲HashMap的扩容机制
- HashMap 底层是数组 + 链表/红黑树。随着数据量增加,哈希冲突会越来越多,如果不扩容,,链表会越来越长,性能会下降。
- 所以,当元素数量超过阈值(
threshold = 容量 × 负载因子,默认负载因子 0.75)时,就会触发扩容。扩容过程
- 创建新数组:容量翻倍,比如从 16 变 32。
- 元素重新定位:
在 JDK 8 里,扩容时不需要重新算 hash,只需要将哈希值与原数组长度进行按位与运算,从而判断新位置。
- 结果为 0 → 元素留在原位置
- 结果不为 0 → 元素移动到「原位置 + oldCap」
👉 所以每个元素的位置要么不变,要么平移一段距离,非常高效。- 迁移元素:
- 如果桶里是链表 → 遍历链表,把节点用 尾插法搬到新数组里。
- 如果桶里是红黑树 → 根据节点数决定:
- 节点 ≥ 6 → 继续保持红黑树
- 节点 < 6 → 转回链表(因为节点少,用树反而浪费性能)。
- 每个数组元素其实是一个 Node 节点,节点里存了:
key、value、hash值,以及指向下一个节点的指针。
22.通过hash计算后找到数组的下标,是如何找到的呢,了解hashMap的寻址算法吗?
- 在 HashMap 里,存储键值对之前要先确定放到数组的哪个位置。
- 首先会算 key 的哈希值。
- 每个对象本身有
hashCode()方法,但直接用可能分布不均匀,- 所以 HashMap 会再做一次扰动运算,让高位信息也参与进来,减少哈希冲突。
- 接着再算数组下标。
- 不是用取模
%,而是用位运算,hash & (数组长度 - 1)。- 因为数组长度始终是 2 的幂次方,
n-1的二进制就是低位全是 1。- 这样算的结果其实等价于取模,但效率更高。
总体来说,HashMap寻址过程:算哈希 → 扰动运算保证均匀分布 → 位运算得到数组下标。
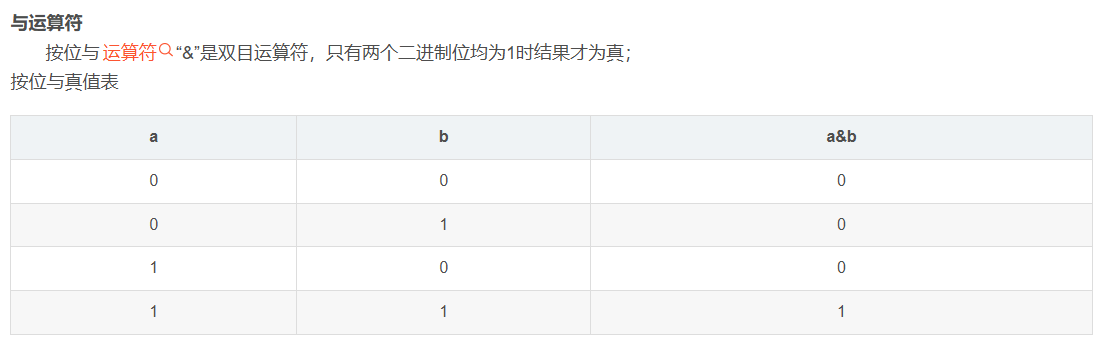
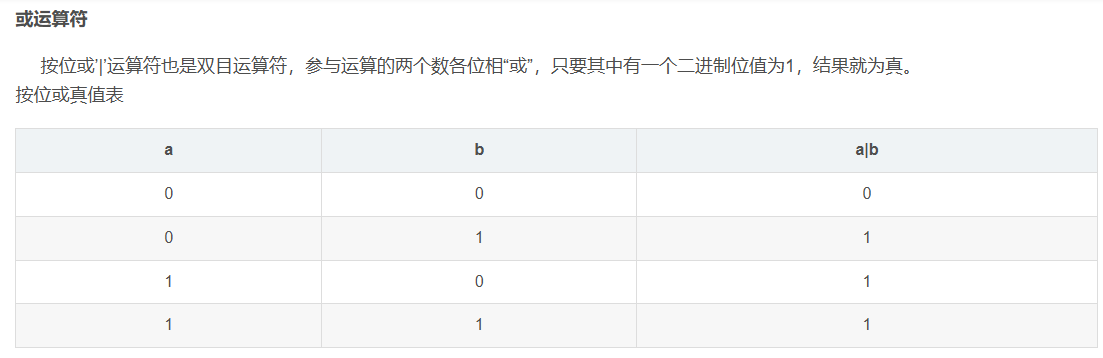
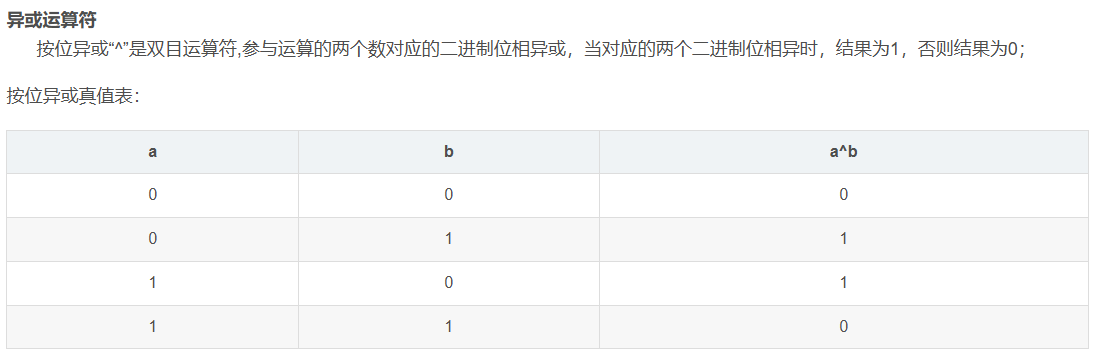
假设 HashMap 数组长度 n = 16,键的哈希值 hash = 23。
n - 1 的二进制是 0000 1111,hash 的二进制是 0001 0111,按位与运算过程如下:
 结果是
结果是 7,这就意味着该键值对会被存储到数组下标为 7 的位置。
23.⭐️⭐️⭐️为何HashMap的数组长度一定是2的次幂?
高效取模(用位运算代替取模)
- 我们定位元素位置用的是:index = hash & (table.length - 1)
- 数组长度总是 2 的幂次方,减 1 后二进制都是低位全 1,这样一按位与,相当于取模运算,效率比
%更高。分布更均匀,减少哈希冲突
- 如果数组长度不是 2 的幂,那么
length - 1 = 1001,低位不是全 1。- 这样 & 运算时,有些位就不会参与计算,导致元素分布不均匀,容易集中到某些槽位,增加哈希冲突。
- 长度是 2 的幂时,低位全 1,哈希值的所有低位都能参与运算,元素分布更均匀。
扩容迁移更方便
- HashMap 扩容时,数组长度会 翻倍。
- 元素在新数组中的位置要么跟原来一样,要么是 原位置 + 原数组长度。
- 这是因为多出来的一位(二进制高位)只会影响两种情况,迁移时只需要简单判断即可,效率很高。
24.知道Hashmap在1.7情况下的多线程死循环问题吗?
- JDK1.7 以及更早版本的 HashMap,在多线程环境下触发扩容时可能出现死循环问题。
- 具体原因是扩容迁移时使用了 头插法,当多个线程同时操作链表时,
- 会导致节点指针指向错误,从而形成环形链表,后续在查询时就可能陷入无限循环
- 到了 JDK1.8,HashMap 改成了 尾插法,避免了链表反转导致的环的问题
- 但它依然不是线程安全的。并发场景下如用HashMap,可能会出现数据覆盖或丢失
- 所以在实际开发中,会选择 ConcurrentHashMap 或者
Collections.synchronizedMap来替代。

25.⭐️⭐️⭐️HashMap为什么线程不安全?
HashMap 线程不安全,主要有几个方面:
- 并发写入导致数据丢失:多个线程同时
put,可能后写的数据覆盖前写的数据。- 扩容时的数据问题:
- 在 JDK1.7 里,多线程扩容可能造成链表反转,形成环形链表,导致死循环;
- 在 JDK1.8 虽然解决了这个问题,但扩容时依然可能丢数据。
- 读写并发不保证可见性:线程 A 写入的数据,线程 B 不一定马上能读到。
所以在多线程环境下,如果用 HashMap 可能出现数据不一致、丢失甚至死循环的问题。实际开发中我们一般会选择 ConcurrentHashMap 来保证线程安全。

26.HashMap常见的遍历方式?
HashMap 常见的遍历方式主要有三类:
遍历 entrySet(最常用也最高效):
2
3
4
5
6
7for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " = " + entry.getValue());
}
// map.entrySet():entrySet方法会返回一个包含Map.Entry对象的Set集合,
// 每个Map.Entry对象代表HashMap中的一个键值对。
// 通过增强型 for 循环(也叫 for-each 循环)遍历这个Set集合。
// 在每次循环迭代中,entry变量代表集合中的一个Map.Entry对象。这种方式一次性拿到 key 和 value,避免二次查找,效率更高
遍历 key → 再根据 key 取值:
2
3
4for (String key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
// map.keySet()方法返回一个包含HashMap中所有键的 Set 集合。这种方式适合只关心 key 的情况。
遍历 values:
2
3for (String value : map.values()) {
System.out.println(value);
}只关心 value 时用。
用 Iterator(可以在遍历时删除元素)
2
3
4
5
6
7
8Iterator<Map.Entry<K, V>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<K, V> entry = it.next();
it.remove(); // 安全删除
}
// .iterator():调用Set集合的iterator方法,返回一个迭代器对象,遍历Set集合中的元素
// hasNext:方法用于检查迭代器中是否还有下一个元素。只要还有元素,就会继续执行循环体。
// next():用于获取迭代器中的下一个元素,并将其赋值给entry变量。Map.Entry是一个接口,代表Map中的一个键值对。如果要边遍历边修改(删除),必须用迭代器。
此外,JDK8 之后还可以用 Lambda 表达式 + forEach:
2
3
4map.forEach((k, v) -> System.out.println(k + " = " + v));
// (k, v) -> { ... }:这是一个 Lambda 表达式,作为 forEach 方法的参数。
// (k, v) 是 Lambda 表达式的参数列表,分别代表 HashMap 中的键和值。
// { ... } 是 Lambda 表达式的方法体,其中定义了要执行的操作。在实际开发中,如果是大数据量场景,推荐用
entrySet遍历,因为效率最高。
27.⭐️⭐️⭐️⭐️ConcurrentHashMap?
ConcurrentHashMap就是线程安全版的 HashMap,用来解决多线程下数据不一致的问题。
相较于老的
Hashtable或Collections.synchronizedMap(),它的并发性能更好。
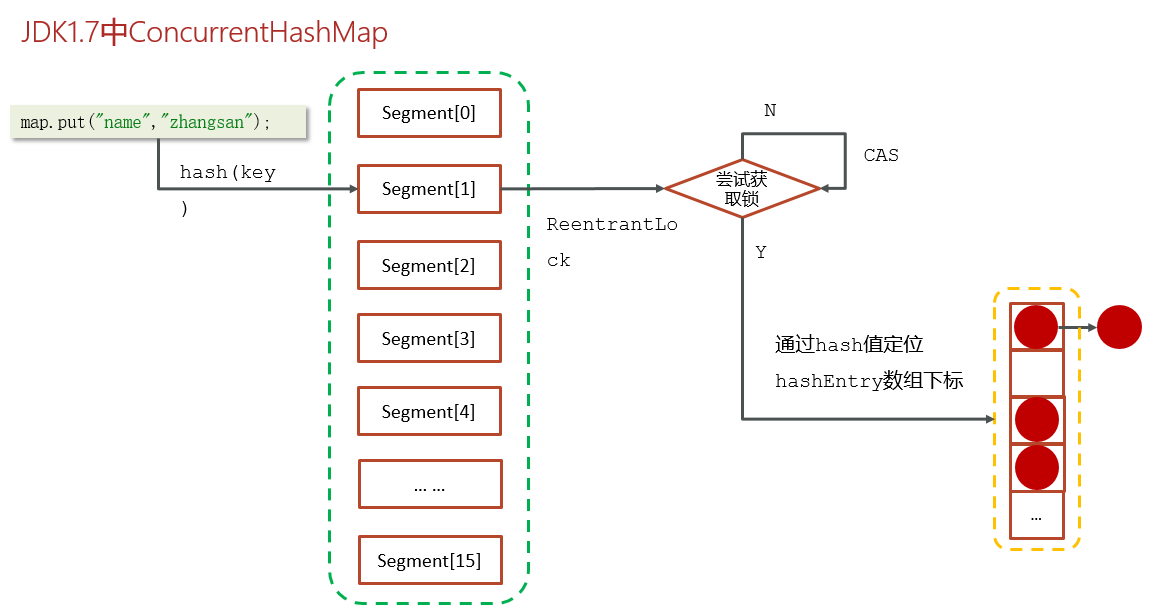
- 在 JDK1.7 中,它采用了 分段锁(Segment) 的机制,
- 整个 HashMap 被分成若干段(Segment,本质是小的 HashTable),
- 每个段有独立的锁,这样不同线程操作不同段时可以并发执行,
- 比 Hashtable 那种整张表加锁效率高很多。
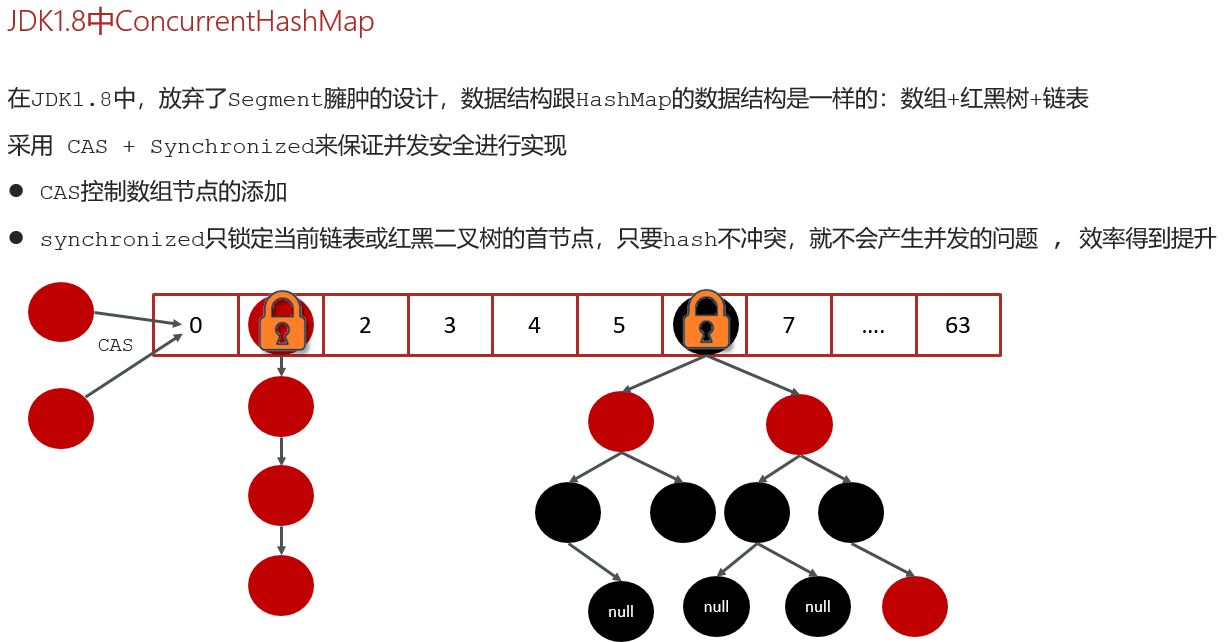
- 在 JDK1.8 中,抛弃了分段锁,改成了 CAS + synchronized 的机制:
- 插入的时候先尝试用 CAS 无锁更新;
- 如果 CAS 失败,再对某个桶加 synchronized,粒度比分段锁更细。
- 链表长度超过阈值时会转换为红黑树,提高查询效率。
在实际开发中,如果需要在多线程环境下使用 Map,首选 ConcurrentHashMap。
- 写操作:根据键的哈希值计算所在的Segment,对该Segment加锁,在锁的保护下进行插入、更新等操作。
- 读操作:大多数读操作不需要加锁,Segment中的数据通过 volatile 保证可见性。
既有悲观锁也有乐观锁。
28.⭐️⭐️⭐️ConcurrentHashMap 和 Hashtable 的区别?
- Hashtable 是早期的线程安全 Map,它用的是方法级别的 synchronized,也就是整张表加锁,所以并发性能很差。
- ConcurrentHashMap 是对它的优化,
- JDK7 用的是分段锁,只锁一个 Segment,比 Hashtable 粒度小。
- JDK8 改成了 CAS + synchronized,只锁单个桶,粒度更小。支持更高并发。
- 两者都不允许 null key 和 null value。否则会抛
NullPointerException。- 实际开发中,Hashtable 基本已经淘汰,都会用 ConcurrentHashMap。
29.ConcurrentHashMap 为什么不允许 null key 和 null value?
- HashMap 单线程允许一个 null key 和多个 null value,但 ConcurrentHashMap 不允许任何 null 键值。
- 根本原因是 在并发环境下无法区分“key 不存在”和“key 的值就是 null”,同时会给某些并发方法带来潜在风险。

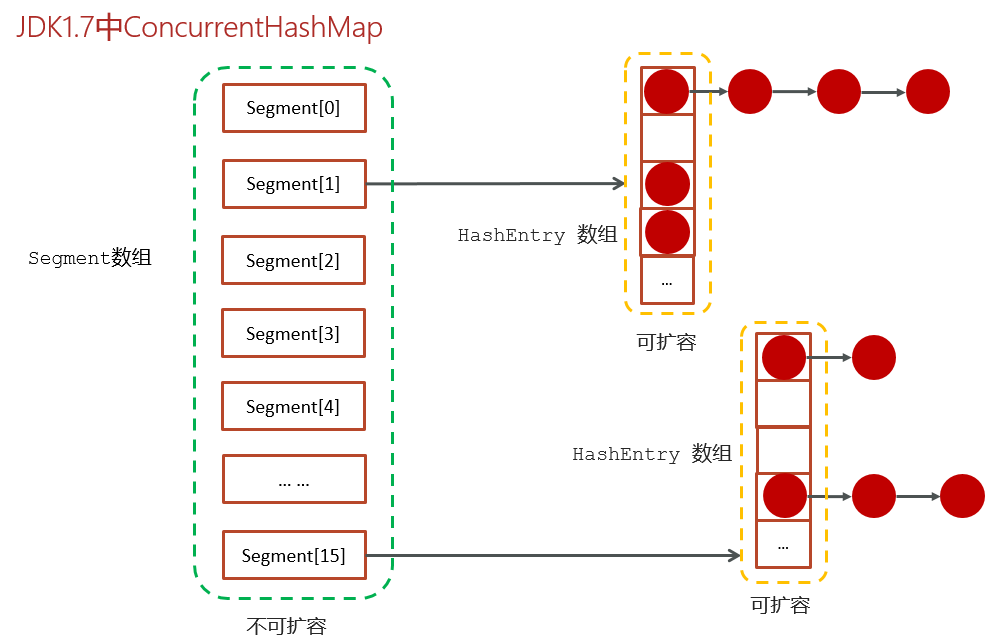
存储流程
- 先去计算key的hash值,然后确定segment数组下标
- 再通过hash值确定hashEntry数组中的下标存储数据
- 在进行操作数据的之前,会先判断当前segment对应下标位置是否有线程进行操作,为了线程安全使用的是ReentrantLock进行加锁,如果获取锁失败会使用cas自旋锁进行尝试