Java核心知识2
Object
31.Object 类的常见方法有哪些?
Object 类是一个特殊的类,是所有类的父类,主要提供了以下 11 个方法:
equals()
比较两个对象是否相等,默认比较引用是否相同。通常会被重写为内容比较。
2
3Person p1 = new Person("张三");
Person p2 = new Person("张三");
System.out.println(p1.equals(p2)); // 默认返回 false,需要重写equals方法才会根据内容比较hashCode()
返回对象的哈希值,默认根据内存地址生成。equals和hashCode要配合使用(如果两个对象equals返回true,则它们的hashCode也应相等)。toString()
返回对象的字符串表示,默认是类名和哈希码。通常会被重写以提高可读性。
2Person p = new Person("张三");
System.out.println(p.toString()); // 输出:Person@1a2b3c4dgetClass()
返回对象的运行时类,用于获取类的相关信息。clone()
创建当前对象的浅拷贝。finalize()
1️⃣会在对象被垃圾回收之前由 Java 虚拟机调用。
2️⃣不推荐使用,执行时间不确定。已被java.lang.ref.Cleaner替代notify() / notifyAll()
唤醒在当前对象上等待的单个或所有线程,这些方法用于线程间通信。
32.⭐️⭐️⭐️== 和 equals() 的区别
- 对于基本数据类型,
==比较的是它们实际存储的值是否相等。
当涉及引用数据类型(如类、数组、接口等)时,==比较的是两个引用是否指向内存中的同一个对象,也就是比较它们的内存地址。equals()是Object类的方法,默认情况下,equals()方法比较的是对象的内存地址,只有在重写了equals()后,才会根据对象内容进行比较。
33.hashCode有什么用?为什么要有 hashCode?
hashCode主要用于提高哈希结构(比如HashMap、HashSet、Hashtable)中对象的存取效率。- 对象会根据
hashCode定位到某个哈希桶,再通过equals判断是否真的相等。这样查找就不用把集合里的所有元素都遍历一遍。
- 如果没有
hashCode,集合在存取元素时只能全表遍历,效率是 O(n)。- 有了
hashCode,就能先根据哈希值快速定位,大部分情况下复杂度能降到 O(1),大大提升了性能。
34.为什么重写equals时必须重写hashCode()方法?
- Java 规定:如果两个对象通过
equals相等,那么它们的hashCode必须相同。- 如果只重写了
equals没有重写hashCode,那么在哈希集合中,相等的对象可能会被分到不同的桶里,导致查找、去重都出问题。- 所以,重写
equals时必须保持hashCode的一致性,保证集合能正确工作。String
String
35. 常用方法
- length() – 返回字符串长度
- charAt(int index) – 获取指定位置的字符
- substring(int begin, int end) – 截取子串
- contains(CharSequence s) – 判断是否包含子串
- trim() – 去掉字符串前后空格
- toCharArray():把字符串转换为一个
char[]字符数组,这在逐字符处理时非常方便。- split(String regex) – 切分字符串
- equals(String another) – 判断两个字符串内容是否相等
- equalsIgnoreCase(String another) – 忽略大小写比较
- startsWith(String prefix) – 判断是否以某前缀开头
- endsWith(String suffix) – 判断是否以某后缀结尾
- replace(old, new) – 替换 replce(“垃圾”, “*”)
- compareTo(String another) – 按字典序比较大小
- indexOf(String str) – 返回子串第一次出现的位置 s.indexOf(“o”); “hello world” 4
- lastIndexOf(String str) – 返回子串最后一次出现的位置
- toUpperCase() – 转大写
- toLowerCase() – 转小写
36.⭐️⭐️⭐️String,StringBuffer,StringBuilder的区别?
可变性:
- String:不可变,每次修改会生成新的对象。
- StringBuffer 和 StringBuilder:可变,允许直接修改字符串内容。
线程安全性:
- String:线程安全,因为它是不可变的。
- StringBuffer:线程安全,方法使用了 **
synchronized**。- StringBuilder:非线程安全,性能较高,适用于单线程环境。
性能:
- String:每次修改都会创建新对象,性能较差。
- StringBuffer:对原对象操作,性能好于 String。
- StringBuilder:与 StringBuffer 相似,但更高效,适合单线程场景。
对于三者使用的总结:
- 操作少量的数据: 适用
String- 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer- 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder
37.⭐️String为什么是不可变的?
内部存储设计
- String 内部保存字符串的数组被
final修饰且为私有的;final让这个引用 一旦初始化就不能再指向别的数组;- 数组是私有的,外部访问不到;
- String 没有提供修改数组内容的方法,所以外部无法改动字符串。
类设计层面
- 同时String 类被
final修饰,不能被继承。- 避免了子类通过覆盖方法来破坏不可变性。
1 | |
final 修饰的数组本身内容还是能改的,但因为 String 把它封装得很严实(private + 无修改接口),外部根本没机会去动它,这才是不可变的关键。被 final 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,final 关键字修饰的数组保存字符串并不是 String 不可变的根本原因,因为这个数组保存的字符串是可变的(final 修饰引用类型变量的情况)
38.⭐️String类型的变量做“+”运算时发生了什么?字符串拼接用“+”还是StringBuilder?
String 做
+运算时,
- 如果拼接的是 编译期常量,编译器会直接优化成一个常量,不存在运行时开销。
- 如果拼接中有 变量,编译器会在底层用
StringBuilder来实现,调用append()方法拼接,最后执行toString()得到新的 String 对象。
- 由于 String 不可变,每次拼接都会产生新对象。在少量拼接时直接用
+就行,但在循环或大量拼接时应该显式使用StringBuilder,性能更高。
2
3
4
5
6
7
8String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";
String str4 = str1 + str2;
String str5 = "string";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false不过,字符串使用
final关键字声明之后,可以让编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。
2
3
4
5
6final String str1 = "str";
final String str2 = "ing";
// 下面两个表达式其实是等价的
String c = "str" + "ing";// 常量池中的对象
String d = str1 + str2; // 常量池中的对象
System.out.println(c == d);// true
39.String#equals() 和 Object#equals() 有何区别?
- 在 Object 类中,
equals()比较两个对象的引用是否相同(内存地址)。- String 类 重写了 Object 的 equals 方法。它比较的是 字符串的内容是否相同,而不是地址。
1 | |
40.字符串常量池的作用了解吗?
- 字符串常量池是 Java 中的一块特殊内存区域,用于存储字符串对象。
- 由于字符串是不可变的,当创建字符串常量时,JVM 会首先检查字符串常量池中是否已存在相同内容的字符串对象。如果存在,则直接返回该对象的引用,而不会重新创建新的对象,避免了重复创建相同内容的字符串,减少了内存占用。
1 | |
41.⭐️⭐️⭐️String s1 = new String(“abc”);这句话创建了几个字符串对象?
- 字符串常量池中不存在 “abc”:会创建 2 个 字符串对象。一个在字符串常量池中,由
ldc指令触发创建。一个在堆中,由new String()创建,并使用常量池中的 “abc” 进行初始化。- 字符串常量池中已存在 “abc”:会创建 1 个 字符串对象。该对象在堆中,由
new String()创建,并使用常量池中的 “abc” 进行初始化。


42.⭐️String#intern方法有什么作用?
intern()方法会尝试把字符串加入到字符串常量池中:
- 如果常量池中已经有这个字符串,就返回常量池中该字符串的引用;
- 如果没有,就把当前字符串加入常量池中,并返回它的引用。
- 这样做的好处是,多个内容相同的字符串可以共享常量池中的同一个实例,减少内存开销。例如,当有多个不同的字符串对象存储着相同的内容时,通过
intern方法可以使它们指向常量池中的同一个字符串,避免了重复创建对象
1 | |
异常
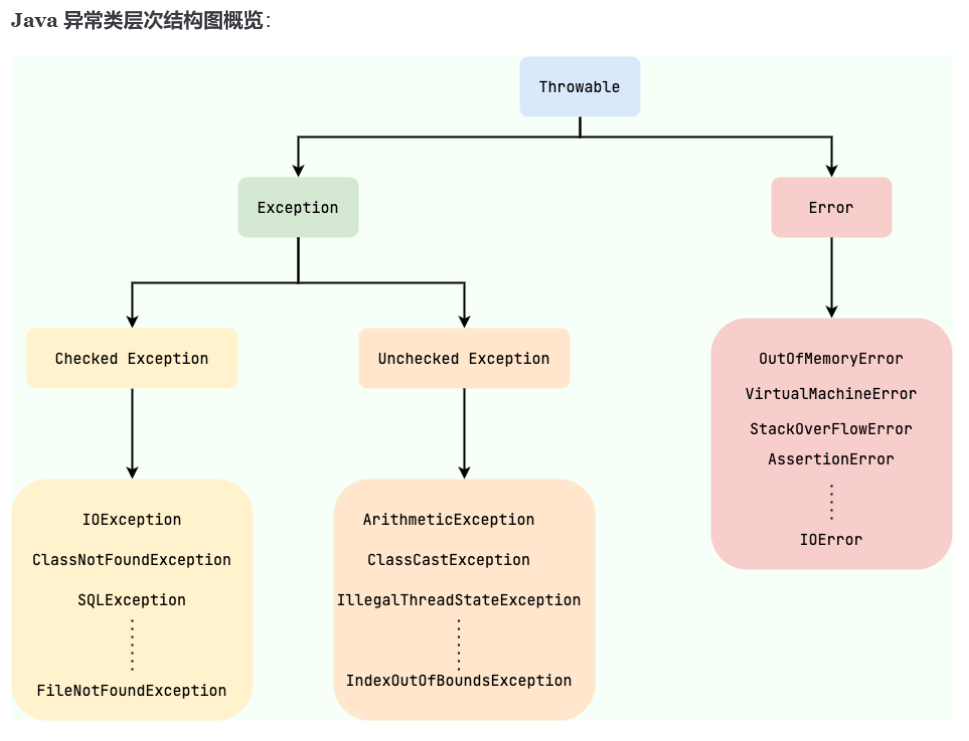
43.⭐️⭐️⭐️Exception和Error有什么区别?
两者都继承自 Throwable |
||
|---|---|---|
| 对比点 | Exception | Error |
| 定义 | 程序本身可以处理的异常 | 程序无法恢复的严重问题 |
| 常见场景 | 空指针NullPointerException、数组越界、IO 异常IOException、SQL 异常等 | 内存溢出(OutOfMemoryError)、栈溢出(StackOverflowError)、虚拟机错误 |
| 是否能处理 | 程序员需要关注并处理,属于业务逻辑或输入输出问题。通过 try-catch 或 throws | 一般不处理,交给 JVM 终止程序 |
| 语法关系 | Exception 分为 受检异常(Checked) 和 非受检异常(RuntimeException) |
都是 非受检异常 |
44.⭐️Checked Exception和Unchecked Exception有什么区别?
- Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 **
catch**或者throws关键字处理的话,就没办法通过编译。- Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
Checked Exception(受检异常):
- 在编译期必须要显式处理(要么 try-catch,要么 throws 抛出)。否则编译不通过。
- 比如:IOException、SQLException。
- 多用于 外部环境问题(文件丢失、网络异常、数据库连接失败),程序员应该预料并处理。
Unchecked Exception(非受检异常):
- 编译器不会强制要求处理。运行时可能抛出,但编译时不报错。
- 比如:NullPointerException、ArrayIndexOutOfBoundsException
- 多用于 程序逻辑错误(空指针、越界、类型转换错误),通常靠修复代码来避免,而不是捕获。
常见的Checked Exception:
- IOException)(输入输出异常):这是输入输出操作中常见的异常,当进行文件读写、网络通信等操作出现问题时会抛出。例如文件不存在、磁盘空间不足、网络连接中断等情况都可能导致该异常。
- SQLException(SQL 异常):在进行数据库操作时,若出现 SQL 语句执行错误、数据库连接失败等情况,会抛出此异常。
- ClassNotFoundException(类未找到异常):当使用
Class.forName()方法加载类,而指定的类在类路径中不存在时会抛出该异常。 - InterruptedException(中断异常):当一个线程在等待、睡眠或者其他阻塞状态时,被其他线程中断会抛出此异常。
常见的Unchecked Exception:
- NullPointerException(空指针异常):当尝试对一个
null对象进行操作时会抛出该异常,例如调用null对象的方法、访问null对象的属性等。
String str = null; System.out.println(str.length()); - ArrayIndexOutOfBoundsException(数组下标越界异常):当访问数组时,使用的索引超出了数组的有效范围会抛出此异常。
int[] arr = new int[5]; System.out.println(arr[10]); - ArithmeticException(算术异常):在进行数学运算时,若出现非法的运算,如除以零,会抛出该异常。
int result = 10 / 0; - ClassCastException(类型转换异常):在进行类型转换时,如果试图将一个对象强制转换为不兼容的类型,就会抛出该异常。
Object obj = “Hello”; Integer num = (Integer) obj;
 编辑
编辑 - NumberFormatException(数字格式异常):当试图将一个字符串转换为数字类型,但字符串的格式不符合数字的规范时,会抛出该异常。
String str = “abc”; int num = Integer.parseInt(str); - IllegalArgumentException(非法参数异常):当向方法传递了不合法或不正确的参数时会抛出此异常。

 编辑
编辑45.Throwable类常用方法有哪些?
Throwable类是 Java 中所有错误(Error)和异常(Exception)的基类,它提供了一些常用方法,在处理异常和错误时发挥着重要作用:
- **
getMessage()**:返回异常发生时的详细信息。- **
toString()**:返回异常发生时的简要描述.- **
printStackTrace()**:在控制台上打印Throwable对象封装的异常信息。

46.⭐️try-catch-finally如何使用?
try-catch-finally是 Java 中用来处理异常的结构。它的基本用法如下:
try 块:
用于包含可能抛出异常的代码。如果代码执行时发生异常,程序会跳转到对应的
catch块进行处理。catch 块:
用于捕获并处理在
try块中抛出的异常。可以有多个catch块,用于捕获不同类型的异常。finally 块:
无论
try块中的代码是否抛出异常,finally块中的代码都会执行。通常用于执行清理工作,如关闭文件、数据库连接等资源。
1 | |
catch块的顺序:当存在多个catch块时,子类异常的catch块要放在前面,父类异常的catch块放在后面。这是因为如果父类异常的catch块在前,子类异常就会被父类异常的catch块捕获,导致子类异常的catch块无法执行。finally块的执行:即便在try或catch块中存在return、break或continue语句,finally块中的代码依然会在这些语句执行前执行(但System.exit()方法会使程序直接终止,finally块不会执行)。
47.finally中的代码一定会执行吗?
- 不一定的。在某些情况下,finally 中的代码不会被执行。
- 就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。
1 | |
48.如何使用try-with-resources代替try-catch-finally?
- try-with-resources 是 Java 7 引入的语法,用来简化 try-catch-finally。
- 它会在代码执行结束后,自动调用实现了 AutoCloseable 接口资源的 close() 方法,比如文件流、数据库连接、网络连接,从而避免忘记在 finally 中手动关闭导致的资源泄漏。
49.异常使用有哪些需要注意的地方?
- 捕获要精准:尽量捕获具体的子类异常,而不是笼统的父类异常。
- 处理要合理:不能简单打印或忽略异常,要结合业务记录日志、提示用户,避免空的 catch 块。
- 资源要安全:对文件流、数据库连接等资源,推荐使用 try-with-resources 自动关闭,避免资源泄漏。
例如,使用 FileNotFoundException 捕获文件未找到的情况,而非直接捕获 IOException,这样能更精准地定位和处理问题。
比如记录详细日志,方便后续排查;给用户明确提示,告知发生了什么。并且,绝对不要使用空的 catch 块,这会让异常被忽略,使问题难以发现。
泛型 Generics
50.⭐️⭐️⭐️什么是泛型?有什么作用?
- 泛型是 JDK 5 中引入的一个新特性,泛型(Generics)就是参数化类型,它允许在定义类、接口和方法时使用类型参数。
- 简单来说,就是在编写代码时不指定具体的数据类型,而是在使用时再确定。
- 如List
和 List ,都可以用同一个 List 类实现,只是类型参数不同。 - 使用泛型参数,提高了代码的安全性和复用性,避免了类型转换错误。
51.泛型的使用方式有哪几种?
泛型的使用方式有三种:泛型类、泛型方法和泛型接口,分别用于类、方法和接口的类型参数化。
泛型类
1 | |
1 | |
泛型接口
1 | |
实现泛型接口,不指定类型:
1 | |
实现泛型接口,指定类型:
1 | |
泛型方法
1 | |
使用:
1 | |
52.项目中哪里用到了泛型?
自定义接口返回结果
- 通过泛型参数 T 可以根据业务动态指定返回的数据类型,避免重复写多个不同的返回类
集合框架
- Java 的集合类(List、Set、Map 等)都大量使用了泛型。
- 这样能在编译阶段进行类型检查,避免运行时强制转换错误,提高安全性和可读性。
反射 Reflection
53.⭐️⭐️⭐️何为反射?应用场景?反射的原理是什么?
- 反射允许 Java 在运行时检查和操作类的方法和字段。
- 通过反射,可以动态地获取类的字段、方法、构造方法等信息,并在运行时调用方法或访问字段。
应用场景 反射常见于框架底层,
- 比如 Spring 用来做依赖注入,
- MyBatis 用来做对象映射;
- 另外在序列化和反序列化时,反射也用来动态获取和设置对象字段。
反射的原理:
- Java 程序的执行分为编译和运行两步,编译之后会生成字节码(.class)文件,JVM 进行类加载的时候,会加载字节码文件,将类型相关的所有信息加载进方法区,反射就是去获取这些信息,然后进行各种操作。
55.反射的优缺点?
优点
- 灵活性高:在运行时动态获取类信息、创建对象、调用方法,提升了框架和工具的通用性。
- 框架底层支撑:Spring、MyBatis 等框架能实现依赖注入、对象映射,都是依赖反射实现的。
- 提高代码复用:可以写出通用的工具类,简化重复代码。比如 JSON 序列化/反序列化、ORM 映射,不用为每个对象单独写代码。
缺点
- 性能开销大:反射涉及动态类型解析和方法调用,性能比直接调用要低。
- 可读性差:代码逻辑更隐晦,不如直接调用清晰,维护成本高。
- 安全风险:反射可以突破封装(访问私有字段和方法),可能破坏类的安全性。
注解Annotation
56.⭐️何为注解?
注解其实就是 Java 提供的一种特殊标记,它可以加在类、方法、字段、参数上。
它
本身不影响代码的逻辑
,但是可以被
编译器或者运行时的工具
去读取,然后做一些额外的处理。
- 比如最常见的
@Override,它告诉编译器这个方法是重写父类的,如果写错了方法名,编译器就会报错,这样能避免低级错误。- 再比如 Spring 里的
@Autowired,框架在运行时会根据这个注解来完成依赖注入。
1 | |
57.⭐️⭐️注解的解析方法有哪几种?
注解只有被解析之后才会生效,常见的解析方法有两种:
编译期解析:
这种方式是通过 注解处理器(Annotation Processor)来完成的它会在
.java文件编译成
.class文件的过程中,扫描代码里的注解,然后做一些处理。
- 举个例子,像我们常用的 Lombok,它的
@Data、@Getter这些注解就是在编译的时候被处理器扫描,然后自动帮我们生成get/set/toString这些方法,所以我们代码里就不用再写这些模板代码了。运行期解析:
这是我们在框架里接触最多的一种方式。它依赖 Java 的 反射机制,前提是这个注解的
@Retention策略必须是
RUNTIME,这样注解信息才能加载到 JVM 里。
- 比如 Spring,在启动的时候会去扫描包,通过反射找到所有带有
@Component、@Service这些注解的类,然后把它们实例化并交给容器管理。- 再比如
@Autowired,Spring 就是通过反射读取到这个注解,然后把依赖对象注入进来。- JUnit框架在执行测试时,也是通过反射找到标记了
@Test注解的方法来运行。
⭐️⭐️⭐️注解的使用原理是什么?
回答了上面两条就可以。
⭐️⭐️⭐️一个类调用自己的内部类上的注解,该注解会生效吗?
- 不生效。
- Java的注解作用范围是声明它的那个元素,如果你在内部类上写了注解,外部类本身是看不到的,除非你通过反射去获取内部类的Class对象,然后查找它的注解。
SPI
58.何谓SPI?SPI和API有什么区别?SPI的优缺点?
- SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,
- 就是 Java 提供一个接口规范,然后不同厂商或者开发者可以自己写实现。
SPI 和 API(Application Programming Interface) 从广义上来说它们都属于接口
- API(Application Programming Interface):是“我要怎么用”。别人提供好接口,我们去调用。
- SPI(Service Provider Interface):是“我要怎么扩展”。JDK 或框架定义好接口,我们来写实现,系统在运行时会自动加载。
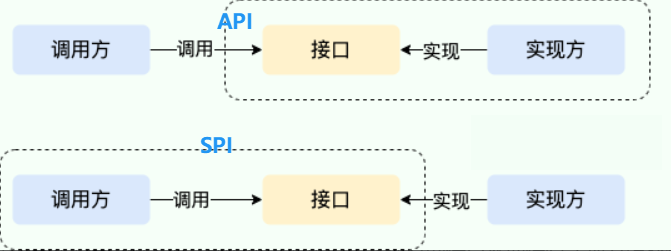
- 它的好处是解耦和扩展性强,常见于 JDBC、日志框架;
- 缺点是有性能开销,加载过程也不够透明。
序列化和反序列化
59.什么是序列化?什么是反序列化?
- 序列化就是把对象转成字节序列,方便存储到磁盘或者通过网络传输。比如把一个 Java 对象转成二进制,写到文件里或者发到远程服务。
- 反序列化就是把字节序列再恢复成对象。比如我从文件里读出数据,或者从网络收到数据,再把它还原成 Java 对象。
序列化就是把对象变成字节,方便存储或传输;反序列化就是把字节恢复成对象。
60.如果有些字段不想序列化怎么办?
- 使用
transient关键字:在字段声明前加上transient关键字,标记为该关键字的字段在序列化时会被忽略。例如:private transient int nonSerializedField;。- 关于
transient还有几点注意:transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
I/O
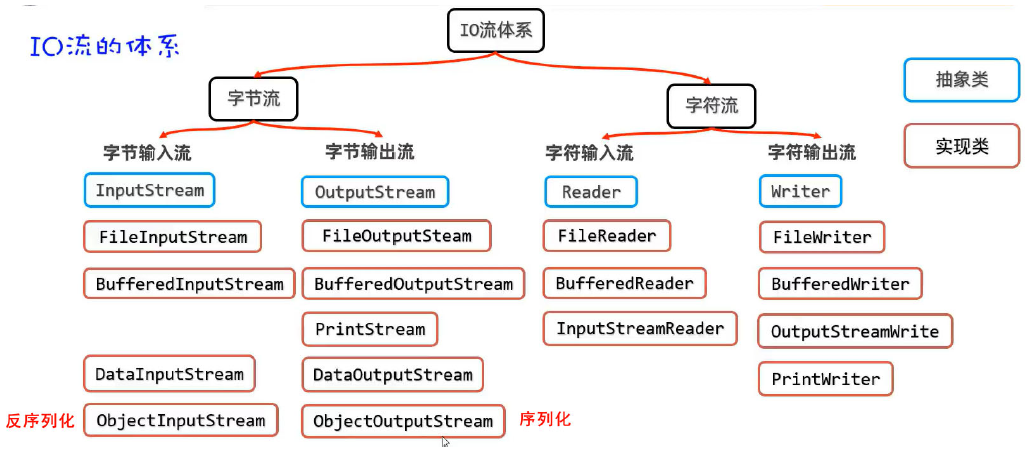
61.Java IO流了解吗?
Java 的 IO 流主要用来处理数据的输入输出。分为四大类:
- 字节输入流 InputStream
- 字节输出流 OutputStream
- 字符输入流 Reader
- 字符输出流 Writer
在计算机里,数据输入输出指的就是数据在不同设备之间的传递过程。
输入Input:把外部的数据读到程序里,比如从键盘输入、从文件读数据、从网络接收数据
输出Output:把程序里的数据写出去,比如在屏幕打印、写到文件、通过网络发送数据
在 Java 里,我们用 I/O 流来实现数据的输入输出,输入流用来读数据,输出流用来写数据。
62. I/O流为什么要分字节流和字符流?
- 字节流是最基础的,可以处理所有类型的数据(文本、图片、音频、视频),一个字节一个字节地读写;
- 字符流是在字节流之上封装的,专门用来处理文本数据,会自动考虑字符编码(比如 UTF-8、GBK),避免中文乱码问题。
- 简单来说,字节流是通用的,字符流是针对文本的便捷封装。读写文本时推荐用字符流,处理二进制文件就用字节流。
63. ⭐️⭐️⭐️⭐️⭐️BIO、NIO、AIO?Java 里常见的 IO 模型有哪些?有什么区别?
Java 里常见的 IO 模型有 BIO、NIO、AIO,主要区别在 阻塞方式和编程模式:
- BIO(Blocking I/O):就是传统的阻塞 I/O ,
- 一个连接就需要一个线程去处理,线程要么在等数据,要么在处理数据。
- 优点是编程简单,缺点是并发量一大,就会产生大量线程,资源消耗很高。
- 一个请求就要一个线程去处理,线程在读写的时候会被阻塞,所以并发量大的时候资源消耗会很高。
- NIO(Non-blocking I/O):是非阻塞 I/O
- 它引入了 Channel、Buffer、Selector 这些概念,实现了非阻塞 + I/O 多路复用。
- 一个线程就可以同时监听多个通道上的事件,不需要一个连接一个线程。
- 这样可以大幅度提升并发能力,适合像 IM 聊天、服务器网关这种连接数多但单次请求短的场景。
- AIO(Asynchronous I/O):是异步 I/O
- 线程发起 I/O 请求后立即返回,当 I/O 操作完成后系统会通过回调通知我们。
- 这样应用线程不用管 IO 的具体读写过程,真正做到了异步化。
- AIO 适合连接数多、操作耗时长的场景,比如文件传输、长连接服务。

Stream流
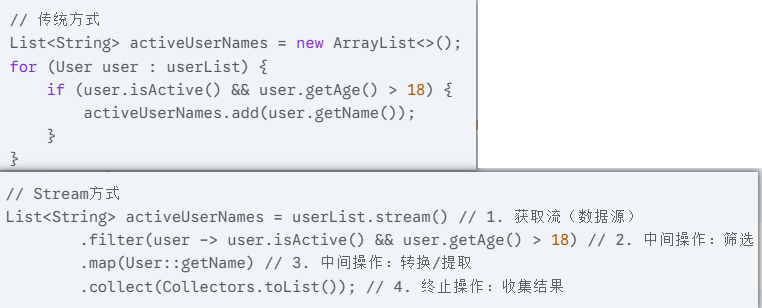
Stream 流一般用于集合,让代码更简洁、可读性更高,也方便并行处理。
- 它支持链式调用,可以组合多个操作,像过滤、映射、统计等。
操作分两类:
- 中间操作(Intermediate):返回 Stream,本身是惰性执行的,比如
filter(),map(),sorted()- 终止操作(Terminal):触发流的执行,返回结果或者副作用,比如
collect(),forEach(),count()
JDK 新特性?
- JDK自8版本以来,更新迭代的速度非常快,带来了很多提升开发效率和性能的新特性。我主要从几个关键的LTS(长期支持)版本,也就是JDK 8、11、17 和最新的 21,来介绍一些对我们Java后端开发影响比较大的新特性。
先说 JDK 8,它其实是现代 Java 的分水岭:
- Lambda 表达式和 Stream API:Lambda让代码更简洁,尤其是处理集合时,用Stream可以链式操作数据,像
.stream().filter().map().collect(),可读性高,而且方便并行处理。- Optional 类:优雅地避免空指针异常,代码更安全。
- 新的日期时间 API:完全取代了 Date 和 Calendar,设计清晰、不可变、线程安全。
然后是 JDK 11:
- var 局部变量类型推断:可以用
var声明局部变量,不需要显式写类型了,编译器会自动推断类型。比如var list = new ArrayList<String>();,尤其在泛型复杂的场景下很方便。- String 和 Files 的增强:比如
isBlank()判断字符串是否为空或全是空格、strip()去除前后空白,比 trim () 处理得更全面。Files 里新增readString()和writeString(),读写文件更方便。接着是 JDK 17,带来了很多语法糖和语言增强:
- Records(记录类):用一行代码就能定义一个不可变数据类,自带 getter、equals、hashCode、toString,非常适合 DTO。
- Pattern Matching for instanceof(模式匹配):可以在类型检查时直接声明变量,省掉单独强转的步骤,代码更简洁。
最后是最新的 JDK 21,亮点是并发能力的提升:
- 虚拟线程(Virtual Threads)。
JDK一直在往三个方向演进:语法更简洁(比如 var、Records)、表达能力更强(模式匹配),同时底层并发模型更高效(虚拟线程),让我们在实际开发中写出更高效、可维护的代码。